
NTTドコモでは2/6~2/17の2週間で現場受け入れ型インターンシップを実施しました! 現場受け入れ型インターンシップとはドコモが手掛ける数多くの事業の中から厳選したポストにて、実務を体験していただけるイベントとなっています。
今回、サービスイノベーション部の画像認識チームでは1名のインターン生を受け入れ "車載カメラ映像×文字認識" の価値創出をテーマに取り組んでいただきました。今まで車載カメラ映像を路面状態理解などの文脈で検討していましたが、今回は、映像中に多く含まれる街中の文字を活用することをテーマとして、技術検証・ユースケースの探索などの業務を体験していただくこととなりました。
以下インターン生による取り組み内容の報告になります!
はじめに
2月6日~2月17日の現場受け入れ型インターンシップに参加した別宮 広朗です。 大学の研究室では、深層学習の高速化や車道上の障害物の検出といった研究に取り組んでいます。
この記事では、インターンシップで取り組んだ 「車載カメラ映像に文字認識を応用する技術検討の業務」 の体験談について記載したいと思います。
参加のきっかけ
インターンシップに参加したきっかけは、「研究開発の現場を体験し、実際に働くイメージを具体化すること」 です。
説明会や夏のハッカソンに参加していたのですが、研究開発業務に関して下記のような疑問を持っていました。
- 実際の会社や部署の雰囲気がわからない
- 実際の業務って、具体的にどのようなことをするのだろうか?
- 研究室とは異なる、会社の研究開発との具体的な違いとは?
以前から、ドコモの研究開発の業務に興味があったので、疑問を解消し働くイメージを具体化したいと思い、インターンシップに応募しました。
インターンシップにおける取り組み内容
2週間のインターシップでは、 車載カメラの映像に文字認識技術の応用を検討するというお題を元にディスカッションを行い、どこまで検出することができるのか、どのようなユースケースが考えられるか という課題に取り組みました。
初めに文字認識とはどういうものかを紹介し、次にインターンを通じて取り組んだ内容やユースケースとして検討したことを紹介します。
0. 文字認識技術とは?

このブログでの「文字認識技術」は、画像データから文字が映る領域を囲う座標を検出し、何の文字かを認識する技術のことを指します。
上記の画像上だと、「あいうえお」を囲う4つの座標を出力し、その領域の文字が「あいうえお」であることを認識できていれば成功ということですね。
1. 街中の文字情報をワードクラウド化し、地図上へプロット
課題を頂いた際に、「車載カメラ映像のOCR結果をワードクラウドにして、地図上にプロットすると面白い情報が得られるかもね。」というヒントをいただきました。そのため、最初に車載カメラの映像から検出された文字情報をワードクラウド化することを検討いたしました。
ワードクラウドとは、単語の出現頻度にあわせて文字の大きさを変えて視覚化する下図のようなグラフのことです。

突然ですが、ワードクラウドの紹介ついでにクイズです!
このワードクラウドは、ある街中の文字から作成されました。
一体、どこの街でしょう?正解は少し下にあります。
手法としては以下の順に処理を行い、車載カメラの映像に映る街中の文字情報をワードクラウド化し、地図上へプロットしました。
- 車載カメラの映像からフレームを分割し、画像化
- 車載カメラのGPSの位置情報と画像を結合
- 各画像に対して、文字認識技術を適用
- 文字認識された文字を形態素解析を行い、形態素(意味を持つ最小の単位)化
- ある区間で検出された形態素に対して、ワードクラウド化
- GPSの位置情報をもとに、地図上へワードクラウドをプロット
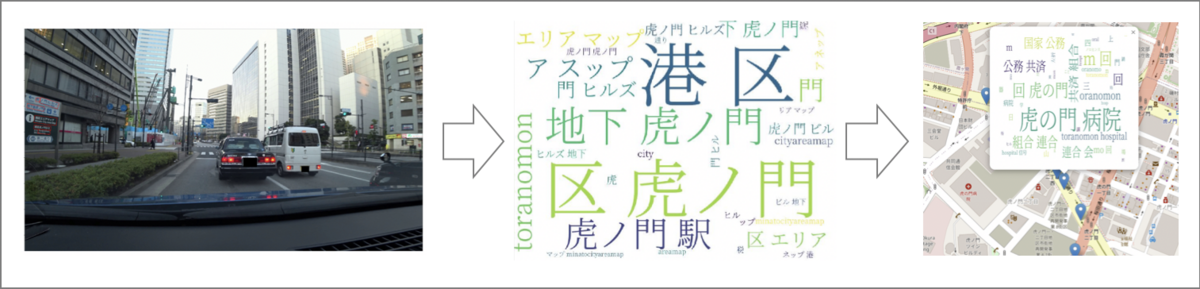
上図は、東京都港区の虎ノ門あたりの車載カメラ映像をワードクラウド化したものです。
実際に街中の看板や標識を通じて、港区や虎ノ門という文字が検出されているのがわかると思います。
2. 地域の類似性の検出
ワードクラウド化により、街中の看板や標識を通じて地域性のようなものが検出できていそうだと実感しました。したがって、検出された地域同士の似てる似ていないが判断できたら面白そうだなと思い、地域の類似性を検出できないか検討してみました。
初めに、様々な地域でワードクラウド化してみます。


大阪の道頓堀を文字認識技術によってワードクラウド化してみた結果が左図で、右図は横浜の中華街の結果です。 どちらの地域の検出結果も各地名や店という文字が存在しており、先程の虎ノ門よりも似ている印象を受けます。
各地域の検出された文字情報の類似度で重要な点として、下記が考えられます。 * 自然言語として類似性を考える必要がある * 地域性を考える上で検出される文字の頻度も考慮した方が良さそうである
上記の点を考慮しながら地域同士の類似度を算出するために、以下のような処理を行いました。
- word2vecという単語をベクトル化する技術を用いて、検出された形態素をベクトル化
- 各形態素の頻出数に応じて重み付けしたベクトルの和を取り、"地域言語ベクトル"のようなものを算出
- ベクトル同士の類似度を測るCOS類似度という指標を用いて、"地域言語ベクトル"同士の類似度を評価
横浜中華街と虎ノ門や道頓堀の"地域言語ベクトル"間の類似度を計算してみます。
今回のインターンシップで利用したデータでの類似度の測定の結果は、以下の通りです。
| 横浜中華街と虎ノ門の類似度 | 横浜中華街と道頓堀の類似度 |
|---|---|
| 0.5943 | 0.7856 |
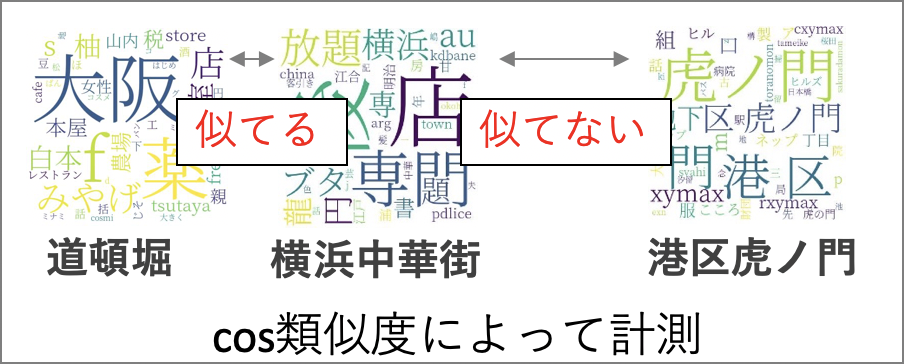
横浜中華街は虎ノ門に比べて、道頓堀の方が類似しているという結果になり、個人的なイメージとも一致しました。
3. 文字情報の多い場所のヒートマップ化・可視化
ここまでの取り組みを通じて、利用していた文字認識技術では、何の文字かを判別する文字認識よりも文字の領域を推定する文字検出の方が精度が高いことがわかりました。
したがって、詳細に文字認識ができなくても、価値を創出できないかという検討を行いました。文字数や文字の大きさなどは高い精度で検出できるため、人が注目してしまう文字情報の検出に利用できるのではないかと考察しました。
人が注目する領域を検出する手法としてSaliency detectionがありますが画像上のエッジや色などの画像特徴から検出されるため、文字のような情報は考慮されていないといえます。文字認識技術は文字情報を考慮した人が注目する領域の検出が期待できます。
人が注目してしまう文字に関する要素を「文字量・文字サイズ・画像上の文字の散らばり」と仮定し、それらの要素に対する評価値の和を文字情報として定義し、車載カメラの映像から文字情報の多い場所や少ない場所を検出してみます。文字情報は以下のように計算しています。
= 文字の領域面積を正規化した値
= 複数の文字領域の重心とのx、y軸の標準偏差の正規化した値
= 検出した文章の文字量を正規化した値
- 文字情報 =

左の図では文字情報が少なく、右の図は文字情報が多い地域となります。実際に左の図は検出できた文字はなく、右の図では文字の量も多く、文字の大きさや散らばり具合も大きいため"文字情報"が多いといえます。
検出された文字情報をヒートマップで示し、文字情報が多い地点と少ない地点を可視化してみます。
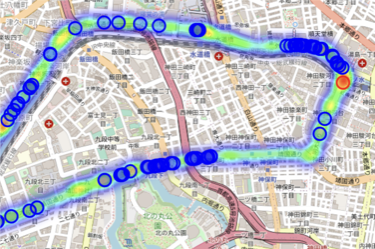
ヒートマップの図では、赤い○の地点が最も文字情報が多く、青い○の地点は文字情報がない地点として確認できます。
4. 車載カメラ映像×文字認識技術のユースケースや展望
これらの取り組みから、ユースケースや展望を考えていきたいと思います。
ワードクラウドのユースケースでは、「地域の言語的流行の発見」と「言語的な類似地域の検索」があります。
「地域の言語的流行の発見」について説明していきます。
先程のクイズの答えは、大阪の「 新世界 」でした!
新世界のワードクラウドでは、新世界の一部の世界であったり、日という文字が大きいことがわかります。
日という文字が大きい原因を解明するために、実際に文字を認識した地域の画像を観察してみると、日本一を称するお店が多いことがわかり、地域の言語的な流行語を認識することができました。
地域の言語的流行を発見できれば、新しく看板や広告を掲載する際に流行語を取り入れることや流行しすぎている言葉と差別化することが可能となるため、広告や看板の内容を決めるための手助けになることが期待できます。
次に、「言語的な類似地域の検索」について説明していきます。

取り組みから地域の類似性を検出できる可能性があることがわかりました。
類似した地域を検出することができれば、好きな地域がある人に類似する地域のレコメンドや、よく行く地域とは類似しない未開拓な地域へのレコメンドが実現できると考えます。
これらを活用することで、旅行における観光地のレコメンドなどが可能となり、潜在的なニーズの顕在化や旅行に行く場所を探す手間の削減が期待できます。
文字情報のユースケースでは、「文字情報の少ない箇所や交通量のデータから、広告や看板の提案」と「多い箇所は運転能力が低下する可能性があるので注意喚起による安全化」があります。
「文字情報の少ない箇所や交通量のデータから、広告や看板の提案」について説明します。
運転中は景色が変わり続けるため、人間が瞬時に認識できる文字情報は限られます。
したがって、広告や看板を設置する場所は文字情報が多すぎる場所は避け、少ないところに設置するべきだといえます。

文字情報の検出から、上図のような文字情報がない地域を検出できます。 また、広告や看板を設置する上では交通量が多いことも重要だと考えられるため、ドコモが保有する交通量のデータを組み合わせることで、「交通量が多く、文字情報が少ない地域」の発見も可能です。
文字情報認識とドコモが保有するデータから広告や看板に適した地域の発見やレコメンドの実現が期待できます。
多い箇所は運転能力が低下する可能性があるので注意喚起による安全化」について説明します。
1では、運転中にデジタル掲示板の文字を読んだ際に、運転手の車線維持ができないという研究があります。
看板や広告といった運転者から見える文字情報が運転能力に影響があると考えられるため、下図のような検出した文字情報が多い地域に対して、注意喚起を行うことで運転手の交通安全への活用が期待できます。

インターンシップを振り返って
インターンシップの初日に、取り組む内容を聞いた時から「車載カメラの映像に、文字認識技術を応用させるのは何かができそうで面白いな!」と思い、ワクワクしていました。しかし、面白い技術でも実際に技術に価値を創出するのは難しかったです。
価値を創出する上で色んな意見が欲しいなと感じ、メンターの方々に進捗報告の際に相談したところ、一緒に意見を出し合う時間を設けていただけました。結果的に、メンターの方々から様々な分野や事業へ視野を広げた価値創出できそうな事例などの意見をいただくことができました。この経験から、技術に価値を見出す上で、一人で視野を狭く考えるのではなく、複数人で幅広く視野を広げながら意見を出し合うことの重要性を学ぶことができました。
また、積極的な行動により、様々な経験ができることも実感しました。 「取り組みの応用となりうる分野の社外打ち合わせへの参加」や「(※基本リモートワークではあるが)積極的な出社」によって、様々な方のお話を聞く機会を得られ、インターンシップの参加目的だった「働くイメージの具体化」も達成できました。目的達成のために、積極的に動き続けることは重要だと再認識することができました。
インターンシップを振り返り、非常に学びの多いインターンシップだと実感しています。
最後に
メンターをしていただいた、加藤さん、北出さん、福島さん、川波さんには深く感謝いたします。 インターン期間中は、毎日朝と夕方に相談する時間を設けていただき、的確なフィードバックも頂くことができたので、順調に業務に取り組むことができました。ありがとうございました。また、インターン期間中にお話を伺わせていただいた社員の皆様にも深く感謝いたします。
トレーナーからのコメント
以上インターン生による取り組み内容の報告でした。
ここからは別宮さんのトレーナーを担当したサービスイノベーション部画像認識チームの川波からトレーナーを代表してコメントさせていただきます。
別宮さんには、車載カメラ映像へ文字認識技術を活用して価値創出していただくというテーマで取り組んでいただきました。 OpenCV・形態素解析などを用いた技術検証プロセスに加え、どのようなユースケースへ適用できそうかという価値創出の面まで提案していただきました。 与えられたテーマを解釈した上でさらに別宮さんのアイデアを加えたプレゼンは部長も唸るほどでしたのでトレーナーとしても成長を見守れて大変嬉しく思います。 今回のインターンシップで得た経験が、別宮さんの今後の研究や取り組みのお役に立てば幸いです。2週間本当にお疲れ様でした!
- Schieber, Frank, et al. “Evaluation of the visual demands of digital billboards using a hybrid driving simulator.” Proceedings of the Human Factors and Ergonomics Society Annual Meeting. Vol. 58. No. 1. Sage CA: Los Angeles, CA: SAGE Publications, 2014.↩