
はじめに
こんにちは。サービスイノベーション部での石井です。 業務ではデータサイエンスやAI等の技術を活用したビジネス適用を行なっております。
データサイエンス分野に長く関わっていると手法やトレンドにも徐々に大きな変化が起きてきていると感じています。 膨大なパラメータを持った基盤モデル(大規模モデル)の登場はその大きな変化の1つで、データ分析に日頃接点の少ない方でも LLM*1 と言うワードを一度は耳にしたことがあるかと思います。
本記事ではそのような基盤モデルの中でもあまり馴染みのないグラフに特化した大規模グラフモデル(以降、Graph Foundation Model*2 と記載)を取り扱っていこうと思います。言語モデル以外でもこういった技術があるのかと深く考えずに読んでもらえればと思います。
本記事で扱う内容
本記事では以下の内容について扱います。
- 基盤モデルについて
- Graph Foundation Model について
- Graph Foundation Model の実践
初めに前提となる基盤モデルや Graph Foundation Model に関しての簡単な説明をした後に、汎用的なノード分類タスクが行える GraphAny と呼ばれる技術を試しに動かしてみようと思います。基盤モデルや Graph Foundation Model の概要については既に知っているよという方は記事後半の「 GraphAny の紹介」まで読み飛ばしてください。
基盤モデルとは
昨今のデータサイエンス分野において、飛躍的な成果を出しているアプローチとして大量のデータと膨大な計算リソースを用いて訓練された大規模モデルがあります。この大量かつバリエーションに富んだデータセットで学習した大規模モデルのことを基盤モデル*3 と呼び、様々なドメインのデータで学習していることから高い表現能力を有する技術となります。
基盤モデルはその表現能力を通してドメイン非依存の問題に適応することが可能で、ゼロショットでの推論や FineTuning などを駆使して様々な下流のタスクに応用することが可能です。加えて、1つのモデルで多くのタスクを解くことができるため、これまで特定のタスクごとに最適化された個々のモデルを構築・運用していた形態から、基盤モデルと呼ばれる汎化性の高い単一のモデルを構築・運用する形態となることで、運用面におけるコスト削減も狙うことができます。 実際にエンタープライズで機械学習モデルを運用していると、複数のモデルやパラメータなど、複雑化する管理から解放されるのは大きなメリットなるかと思います。
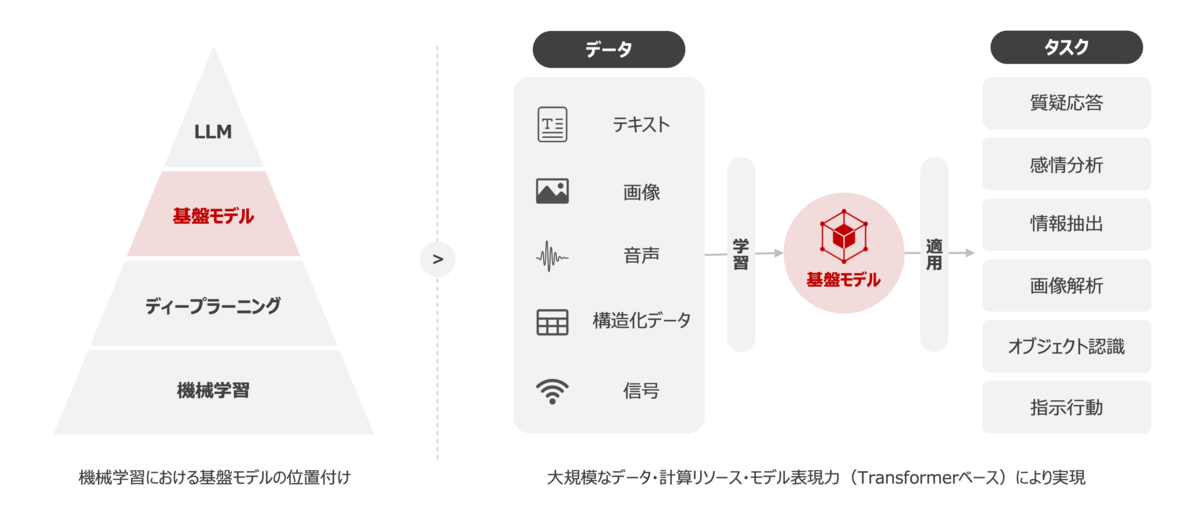
基盤モデルの種類としては言語や画像などのドメインに特化したものから、テキストから画像を生成するといったクロスドメインのものまで多様なものがあります。皆様も馴染みがあるところでいうと、言語系の基盤モデルとして GPT-4、Gemini なども基盤モデルの一種です。以下では、全てを網羅的にまとめるのは難しいのでよく使われる代表的なモデルをまとめておきますので参考にしてみてください。
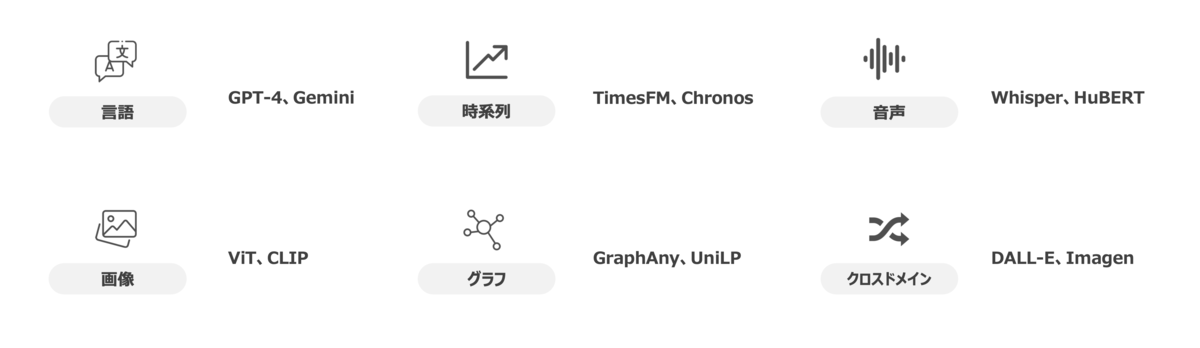
それぞれのドメイン毎で技術の発展度合いには差があります。上記で記載した中では言語モデルが圧倒的に技術開発が進んでおり、一般社会での注目度と言語という分かりやすさも相まって投稿される論文数*4 でも顕著な差があります。言語モデルについては多くの方が記事を書いているので、今回はこのドメインの中でも今後の発展が期待されるグラフに特化した基盤モデルである Graph Foundation Model について以降では焦点を当てていきたいと思います。
Graph Foundation Model とは
まずは Graph Foundation Model を解説する前にグラフで扱う問題設定について少し補足しておきます。
一般的にグラフを扱った機械学習の問題設定では大きく3つのタスクを取り扱います。3つとは、主にノードを対象としたタスク、グラフ全体を対象としたタスク、エッジを対象としたタスクであり、このタスクの選択に加えて、通常の機械学習で扱う分類や回帰といった設定を適用する形で問題設定を定義します。この辺りの詳細については以前に私が投稿した記事があるのでこちらの記事を参考にしてもらえればと思います。 また、これ以外にも1種類のノードで表現された同種グラフ(Homogeneous Graph) や 複数の多様なノードで表現された異種グラフ(Heterogeneous Graph)などのグラフ構造によっても適用可能な手法が異なるため、扱う問題設定やデータ構造に応じて適切な手法、アルゴリズムを選択していかなければならない多様性がある点を意識する必要があります。
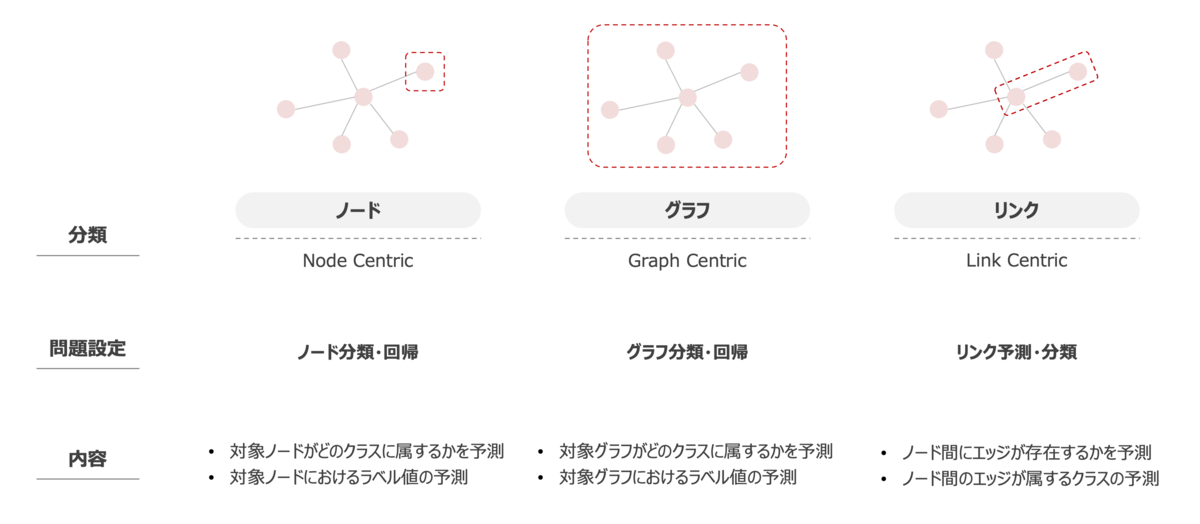
さて、本題の Graph Foundation Model について説明していきます。
Graph Foundation Model は未知のグラフ構造データに対して一般化できる転移可能なグラフ表現を学習した単一のニューラルネットワークモデルを指します。要するにグラフ構造データを扱うことのできる単一かつ様々な下流タスクに適用可能な汎化モデルです。基本思想は基盤モデルと同じで、大量かつ多様なグラフデータセットによる学習を通じて高い表現能力を獲得した事前学習モデルを構築し、ノード分類やグラフ回帰などの下流のタスクに適用させていきます。以下に概要のイメージを記載しておきます。
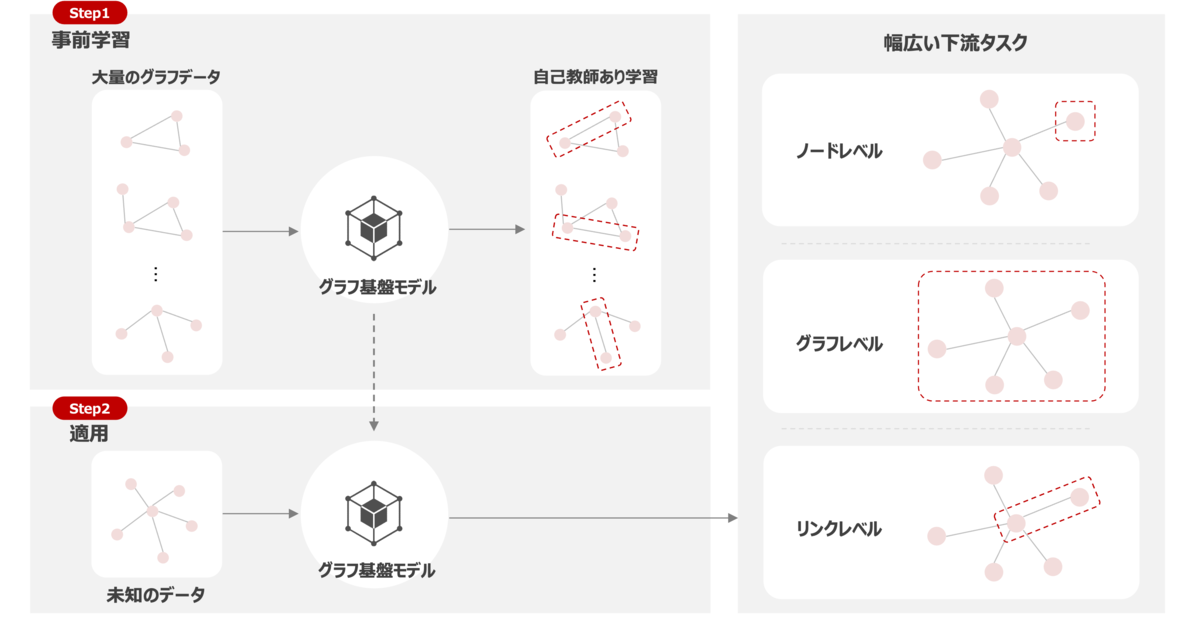
ちなみに事前学習モデルのバックボーンには、自己教師あり学習によるニューラルネットワーク*5 や Transformer アーキテクチャを用いるのが一般的とされています。ただし、現在に至るまでグラフデータを扱った機械学習領域では、グラフニューラルネットワーク*6(以下、GNN)のフレームワークによって技術が発展してきた経緯があり、Transformer アーキテクチャをそのまま転用することが難しいといった課題があります。厳密には Transformer ベースの GNN 手法*7 も存在はしているのですが、画一的な技術として確立はしておらず、Graph Foundation Model を実現する上でのバックボーンの再設計が今後の鍵になってくるとされております。以降では、 Graph Foundation Model の実現に際しての課題について言及していきます。
Graph Foundation Model の課題
ここまでで Graph Foundation Model についての簡単な概要は理解できたかと思います。前節でも少し触れましたが、Graph Foundation Model には直面しているいくつかの課題があり、本節ではその中でも主だった課題について触れていきます。

まずはバックボーンの課題です。 GNN では一般的に Over Smoothing と呼ばれる、ニューラルネットワーク層を深くすることでノード間の表現が似通ってきてしまい、見分けがつかなくなることによる精度劣化の問題があります。これにより、GNN を多層にできないことから、言語モデルのような多くのパラメータ数を持つことができないために、実世界で有効となる汎用的な知識の蓄積を実現することが難しいといった課題へと繋がっていきます。また、GNN は主に Message Passing の仕組みにより隣接するノードの影響を相互に反映して各ノード情報を更新することでグラフにおける表現を獲得しています。基盤モデルのような様々な一般化されたタスクに対応したモデル実現のためには非常に多くのパラメータを保有する必要があるため、言語処理で成功を収めた Transformer のようなアーキテクチャへの再設計が必要とされております。
次に、データの課題です。 1つは 同種グラフ(Homogeneous Graph)や異種グラフ(Heterogeneous Graph)といった異なる性質を持ったグラフデータの種類(タイプ)が存在することです。これらに対して通常はデータ種類に応じた最適化されたバックボーンアーキテクチャを設計することが必要となり、この対応が Graph Foundation Model を実現する上での大きな課題をもたらします。現時点では HAN*8 のような異種グラフを複数の同種グラフにマッピングするメタパスベースのアプローチを用いて解決する方法もありますが、現実世界の複雑なグラフを表現するには不十分であり、より複雑なグラフに対応していかなければなりません。 2つ目はグラフスケールにおけるギャップです。グラフで扱う問題では、化学分子のような数百程度のノードからなる比較的小さいグラフから購買取引グラフなど数百万ものノードとエッジを含む大規模なグラフといった大小様々なスケールがあり、グラフスケールの大小によって顕在化する問題が異なります。例えば、大規模なグラフでは大多数のノードとほとんどエッジが形成されないため、多くのノイズを引き起こし、ストレージ容量や計算量を悪化させてしまいます。 最後の3つ目はグラフデータの多様性です。グラフにはソーシャルネットワークのような単一ドメインのみを扱ったものから、同じ商品でも日用品や衣服といった目的の異なるアイテムのようなクロスドメインを扱うデータも存在します。特に、クロスドメインのグラフでは統一化されたセマンティクスが欠落するため、新しいデータセットにモデルを適用した際にパフォーマンス低下やネガティブな転移へと繋がることから Graph Foundation Model の実現にとっても大きな課題となってきます。
Graph Foundation Model の展望
Graph Foundation Model は様々な課題を克服していく必要があることは伝わったかと思います。ここからはその課題を踏まえて Graph Foundation Model を実現するためのアプローチを記載しようと思います。これまでに記載した課題を全て解決する設計や実装に関する決定的な方策はまだ定まっていないですが、現時点で有効と考えられている方向性を記しておきます。
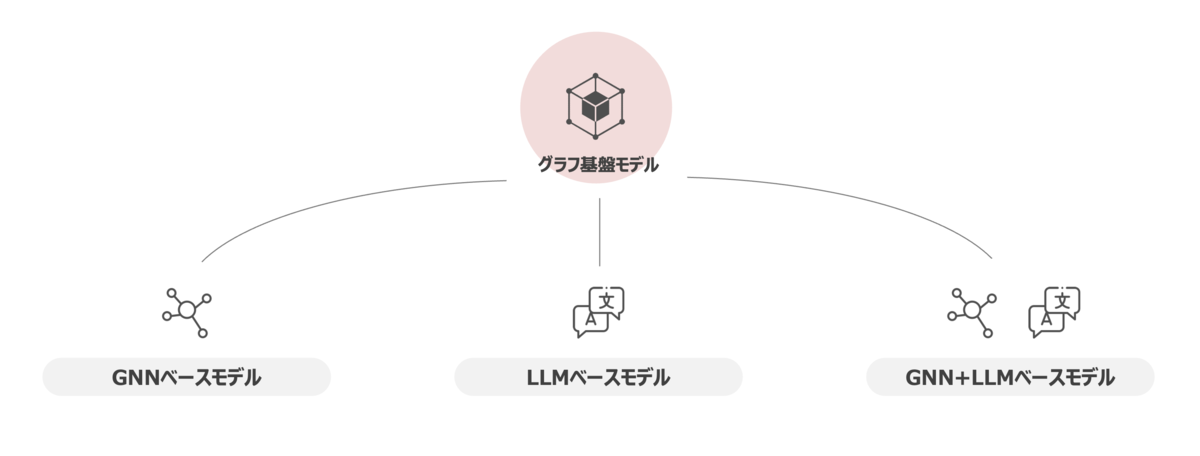
GNN based Model
GNNベースのモデルは、言語処理で使用されるアーキテクチャやパラダイムから着想を得てグラフタスクに適用する方法です。GNN はグラフデータの学習に対して一定の効果があることを証明している一方で、Over Smoothing等の制限に直面している実態があります。そこで、GNN に言語処理で革新的な発展をもたらした Transformer アーキテクチャを応用することで、従来の Message Passing の欠点を解決することを狙います。具体的なアルゴリズムとしては Graph Transformer*9 や Graphormer*10 といったものが既にあります。 一般的に GNN ベースのモデルでは比較的コンパクトなパラメータサイズとなることから、低コストな学習とリソース制限下での展開が可能となるメリットがあるとされております。ただし、大きな欠点としてノードやエッジに含まれた意味情報が十分に活用されないことが多くあり、様々なドメインに渡って一般化する能力が抑制され、幅広いコンテキストの理解や常識的な推論を必要とするタスクでのパフォーマンスが落ちるといった制限を受けてしまいます。
LLM based Model
LLMベースのモデルは、グラフをトークンやテキストとして扱ってLLMをバックボーンとして問題を解く方法です。このアプローチでの主な論点はグラフデータを自然言語とどのように整合させて、LLMが理解できるようにしていくかに焦点が当たっています。例えば、グラフにおけるノードとエッジを独立なものとして捉えてそれぞれをトークンとして扱い、トークンに Type Identifier による識別子を付与して LLM 等に入力させる TokenGT*11 などがあります。 グラフ構造を記述するために必要な長いテキストをLLMが効率的に処理できないことや時間経過とともに変化するグラフの動的な性質を処理することが難しいといった問題が確認されています。そのため、LLMベースのアプローチではグラフ構造の自然言語記述による情報損失の懸念に対して、今後はグラフ構造の効率的かつ情報損失の少ない言語的記述へのモデリング手法を開発していくことが期待されています。
GNN + LLM based Model
最後のGNN + LLMベースのモデルは、LLMの言語理解とGNNの構造分析の両方の長所を活用するために統合化したより強力なモデルを実現する方法です。 LLMのテキストデータからパターンやコンテクストを抽出する能力とGNNの構造分析によるグラフデータから埋め込みベクトルを獲得できる能力により、パフォーマンス向上と下流タスクへの適用が可能となります。しかし、LLMとGNNを共通の意味空間に落とし込むことが難しいとされており、両方のモデルからの埋め込みベクトルが意味や構造情報をどの程度捉えているかといった言語とグラフの整合性を実現する効果的な方法を設計することが今後重要となってくると考えられています。
GraphAny の紹介
これまでの内容で Graph Foundation Model における概要から課題、発展に向けた方向性について解説してきました。現時点では全ての下流タスクに適用可能な Graph Foundation Moldel は確立されていない状況です。ですが、特定タスクにおいては単一モデルで未知の様々なデータに適用可能な技術が少しずつ出始めてきています。今回はノード分類タスクに特化した Graph Foundation Model である GraphAny を最後に紹介しておきます。
GraphAny は単一の事前トレーニング済みモデルで、任意の特徴次元とクラスを持つ未知のグラフでノード分類を実行できる最初の Graph Foundation Model です。LinearGNN と attention モジュールの大きく2つのコンポーネントから構成されており、 LinearGNN によって未知のデータに対して inductive な推論を可能にしています。GraphAny の詳細については論文を参照してもらえればと思います。
実装は Github リポジトリに公開されているソースコードおよび事前学習モデルがあるため、そちらをクローンしてきて設定ファイルに学習や推論で扱うデータを定義するだけで、指定したデータセットでの簡易検証を行うことが可能です。設定ファイルはいくつか存在しますが、主に configs/data.yaml ファイルの内容を以下に示すように変更するだけで実行できます。
_dataset_lookup: WikiWisconsinInference: train: [ Wisconsin ] # モデルと同じ学習データセットを指定 eval: [ Wiki ] # 推論したいデータセットを指定
また、推論実行は以下のように事前学習モデルと扱うデータセットを指定して動作させます。
$ python graphany/run.py prev_ckpt=checkpoints/graph_any_wisconsin.pt total_steps=0 dataset=WikiWisconsinInference
Wisconsinデータセット*12 で事前学習したモデルに対して、他のオープンなデータセットを用いたゼロショットでの推論結果は以下のようになりました。事前学習で用いたWisconsinデータセットのクラス数は 5 であるため、Reddit のような 41 クラスもあるデータセットでもしっかり高い精度を出している点には技術として期待が持てる結果となりました。一方で、精度が 50% 程度でランダムと同程度の精度しか出ていないパターンもあり、データ内容を見るとノード数やエッジ数が少ないデータの場合には期待する精度が得られない傾向があるようにも見えます。事前学習時に利用したデータセットによって精度に影響が出てくるところかと思いますので、皆様が実利用する際には様々なバリエーションで試してみてください。
| データセット | ノード数 | エッジ数 | 特徴量 | クラス | 精度(%) |
|---|---|---|---|---|---|
| AmazonPhoto | 7,650 | 238,162 | 745 | 8 | 89.96 |
| 232,965 | 114,615,892 | 602 | 41 | 90.89 | |
| AirportsBrazil | 131 | 1,038 | 131 | 4 | 53.85 |
| Cora | 2,708 | 10,556 | 1,433 | 7 | 79.40 |
| Deezer | 28 | 281 | 185,504 | 2 | 50.52 |
おわりに
本記事では基盤モデルの一種である Graph Foundation Model について紹介させていただきました。 基盤モデルのような単一の汎用モデルによってドメイン非依存で様々なタスクを解くことができるようになれば、専門のデータサイエンティストによるモデル構築は不要となり、データさえあれば誰もが高度な予測が行えるようになる未来もあり得るかも知れないですね。 まだまだ、技術としては未確立な領域ではありますので、今後の発展に期待する部分が多分にあるかと思いますが、この記事を読んで少しでも皆様の参考となれば幸いです。
*1:Large Language Model の略。大規模言語モデルとも呼びます
*2:Graph Foundation Model を GFM とも略します
*3:スタンフォード大学が発表した「On the Opportunities and Risks of Foundation Models」という論文内で基盤モデルが定義されています
*4:Position: Why Tabular Foundation Models Should Be a Research Priority の論文内にICMLでのドメイン別の投稿数の記載があります
*5:言語処理における Masked Language Model などが類似の処理に該当します
*6:グラフデータを扱うための深層学習技術の総称を指します
*7:Graphormer や NodeFormer などがあります
*8:Wang, Xiao, et al. "Heterogeneous graph attention network." The world wide web conference. 2019.
*9:Dwivedi, Vijay Prakash, and Xavier Bresson. "A generalization of transformer networks to graphs." arXiv preprint arXiv:2012.09699 (2020).
*10:Ying, Chengxuan, et al. "Do transformers really perform badly for graph representation?." Advances in neural information processing systems 34 (2021): 28877-28888.
*11:Kim, Jinwoo, et al. "Pure transformers are powerful graph learners." Advances in Neural Information Processing Systems 35 (2022): 14582-14595.
*12:「Geom-GCN: Geometric Graph Convolutional Networks」で提案されたノードがウェブページ、ハイパーリンクをエッジとして表現されたグラフデータセットです