
はじめに
こんにちは、ドコモ・テクノロジ サービスインテグレーション事業部の神崎です。 ドコモCCoE(Cloud Center of Excellence)のメンバーとして、組織横断的なクラウド活用の促進に取り組んでいます。
本ブログでは、AWS Step Functionsを活用して既存の処理を並列化し、大幅な効率化を実現した事例をご紹介します。具体的には、従来Amazon Elastic Container Service(ECS)上でシーケンシャルに処理していたコードを、Step Functionsを用いることでより効率的に動作させるよう改善したプロセスを解説します。Step Functionsの並列処理機能を活用することで、各タスクを同時実行し、全体の処理時間を大幅に短縮することに成功しました。
背景と目的
多くのシステムでは、特定のデータ(例えばプロジェクトやユーザー)に対する処理を順次行うアプローチが採用されています。たとえば、複数のプロジェクトリストを取得し、それぞれに紐づくユーザー情報を取得・加工するようなケースです。このような「逐次処理」のアプローチはシンプルで理解しやすい一方で、以下のような課題が生じがちです。
処理時間の増大
プロジェクト数やユーザー数が増えると、処理が一つずつ実行されるため全体の実行時間が長くなります。ロジックの複雑化と保守性の低下
特定部分の修正が他の処理にも影響を及ぼす可能性があります。再利用性の欠如
個別の処理が独立していないため、他のユースケースで再利用が難しく、冗長なコードが生じます。
こうした課題に対して、Step Functionsの並列処理機能を活用することで、次のような改善を目指しました。
処理時間の短縮
並列化により、複数タスクを同時に実行し、全体の処理速度を向上保守性の向上
タスクを分離して独立性を高め、変更が容易なアーキテクチャを実現再利用性の確保
各タスクを汎用的に利用可能な形に分離
AWS Step Functionsの概要
AWS Step Functionsは、サーバーレス環境でワークフローを簡単に構築、管理できるサービスです。以下の特徴を備えており、システムの効率化や運用の改善に役立ちます。
視覚的なワークフロー設計
ワークフローはステートマシンとして定義され、AWS Management Consoleで視覚的に確認可能です。豊富な統合性
AWS Lambda、Amazon Simple Notification Service (Amazon SNS)、Amazon Simple Queue Service (Amazon SQS) など多くのAWSサービスと簡単に連携できます。並列処理のサポート
Mapステートなどを使用することで、タスクを並列化し、効率的なデータ処理が可能です。
ただし、実行イベント数やステート遷移の制約があるため、初めて利用する場合は公式ドキュメントや小規模な例で理解を深めることをお勧めします。
本ブログでは、Step Functionsの基本的な使い方から並列処理の活用方法までを解説し、より効率的なシステム構築のヒントをお伝えします。
従来のECS上のループ処理
本事例では、プロジェクト管理システムのAPI を利用して、このプロジェクトに関連するユーザー情報を処理する仕組みを対象としています。 このシステムでは以下のような処理が行われていました。
APIを用いてプロジェクト一覧を取得
各プロジェクトごとに、関連するユーザー情報を取得
必要に応じてユーザーやプロジェクト情報を更新
しかし、この従来のアプローチには以下の課題がありました。
処理時間が長い
各プロジェクトに対するユーザー取得処理を直列的に実行していたため、全体の処理時間が増大並列化が困難
プログラムだけで並列処理を実現するには複雑な実装が必要
Step FunctionsのMapステートで並列化
Step Functionsの導入により、従来の「for文で直列処理」を「Mapステートを活用した並列処理」に置き換えました。これにより、以下の改善が実現しました。
効率的な並列処理
各プロジェクトのユーザー取得処理を1つのLambda関数として切り出し、Step FunctionsのMapステートを使用して可能な限り同時に処理。並列処理の上限値を設定することで、負荷を調整しながら効率化を図りました。処理時間の短縮
各タスクが独立して実行されるため、全体の実行時間を大幅に削減。制約への対応
並列実行数に上限を設けることで、Step Funtionsの制約に対処。
このアプローチにより、システムの効率性が飛躍的に向上し、全体の処理時間を大幅に短縮することができました。
Step Functions導入前後のアーキテクチャ
改善前のコード
従来のECS環境では、プロジェクトごとに順番にユーザー情報を取得する直列処理を行っていました。以下にその一部を示します。
# プロジェクト情報とユーザー情報の取得処理(改善前) def get_users_project(): projects = json.loads(get_projects()) # 全プロジェクト一覧を取得 users = json.loads(get_users()) # 全ユーザー一覧を取得 projectuserlist = {} for project in projects: pjuserlist = [] # 各プロジェクトに関連するユーザー情報を取得(直列処理) pjusers = get_project_users(str(project["id"])) for pjuser in json.loads(pjusers): pjuserlist.append(pjuser["id"]) projectuserlist[project["projectKey"]] = sorted(pjuserlist) # 各ユーザーが属するプロジェクト情報を作成 userprojectlist = {} for user in users: belongproject = [ projectkey for projectkey, pjuserlist in projectuserlist.items() if user["id"] in pjuserlist ] userprojectlist[str(user["id"])] = sorted(belongproject) return userprojectlist
新しいアーキテクチャ
Step Functionsを導入し、直列処理を並列処理に置き換えました。これにより、各プロジェクトごとの処理が並列で実行され、全体の処理時間が短縮され、効率的にユーザー情報を取得できるようになりました。
ユーザー情報取得の並列化
従来のECSでの処理を、Step FunctionsのMapステートを活用して並列化。各プロジェクトに対するユーザー情報取得を並列で行い、処理の効率を大幅に向上させました。コードのリファクタリング
ユーザー情報取得処理をLambda関数として分割し、それをStep Functions内で並列実行することで、全体のスループットを改善しました。
実装例
以下に、新しい構成のStep Functionsワークフローのワークフロー図とJSONを示します。
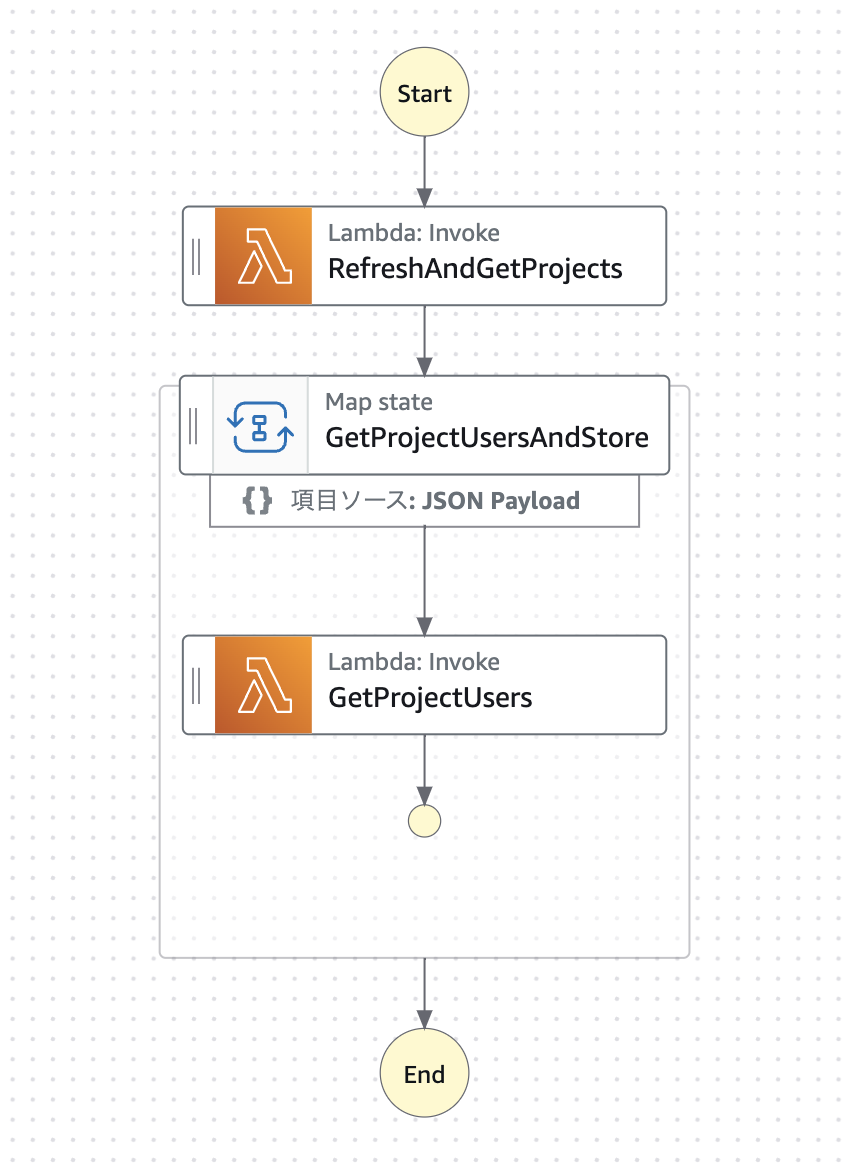
{ "Comment": "Updating Project User List File on S3", "StartAt": "RefreshAndGetProjects", "States": { "GetProjectUsersAndStore": { "Comment": "Get Each Project Users from System and Put it to S3", "End": true, "Iterator": { "StartAt": "GetProjectUsers", "States": { "GetProjectUsers": { "End": true, "Resource": "arn:aws:lambda:YOUR_REGION:YOUR_AWS_ACCOUNT:function:sample-dev-GetProjectUsersFunction", "Retry": [ { "BackoffRate": 2, "ErrorEquals": [ "States.TaskFailed" ], "IntervalSeconds": 3, "MaxAttempts": 3 } ], "Type": "Task" } } }, "MaxConcurrency": 100, "Type": "Map" }, "RefreshAndGetProjects": { "Comment": "Delete S3 Files and Get Projects Info ", "Next": "GetProjectUsersAndStore", "OutputPath": "$", "Resource": "arn:aws:lambda:YOUR_REGION:YOUR_AWS_ACCOUNT:function:sample-dev-GetProjectsFunction", "Retry": [ { "BackoffRate": 2, "ErrorEquals": [ "States.TaskFailed" ], "IntervalSeconds": 3, "MaxAttempts": 3 } ], "Type": "Task" } } }
説明
RefreshAndGetProjects
プロジェクト管理システムから全プロジェクト情報を取得し、S3に保存するタスク
タスクが失敗した場合、リトライ処理(最大3回、指数バックオフ)を実行します。
GetProjectUsersAndStore
Mapステートを使用し、各プロジェクトのユーザー情報を並列で取得し、S3に保存します。
最大並列実行数は100 (MaxConcurrency)
内部の GetProjectUsers ステートでは、Lambda関数を使用して各プロジェクトのユーザー情報を取得し、失敗時にはリトライ処理を実行します。
この構成により、プロジェクトごとのユーザー取得を並列処理することで、全体の処理時間が短縮されます。
Step Functionsでの実行履歴クオータへの対策
Step Functions導入前後のアーキテクチャで、従来の逐次処理アプローチから並列処理を活用したアーキテクチャに変更したことを説明しました。この新しいアプローチでは効率化が進む一方で、Step Functions特有の制約である実行履歴クオータへの対応が必要になります。以下では、この課題を克服するための具体的な工夫について解説します。
Step Functionsでは、各ステートの実行履歴が記録されます。この履歴には、入力データ、出力データ、実行状況などが含まれますが、大量のデータを処理する場合、記録量がクオータ(制限値)を超えるとエラーが発生します。特に、Mapステートのように複数の並列処理を扱う場合、履歴データが急増し、25,000件の制限に達してしまうことがあります。
これを防ぐため、本システムでは以下のアプローチを採用しています。
データ量の調整
プロジェクト一覧取得後、一定の単位ごとにデータを分割。一度に処理するデータ量を調整することで、1つのステートで扱うデータ量を最適化し、実行履歴クオータを回避します。プロジェクトの分割処理
プロジェクトリストをループ処理し、グループ化してStep FunctionsのMapステートに渡します。これにより、各グループを効率的かつ並列に処理可能です。
実装例
以下は、上記アプローチを実現するためのLambda関数の実装例です。この関数は、プロジェクト一覧をBATCH_SIZE単位で分割し、Mapステートで処理するためにリストに格納します。
BATCH_SIZE = int(os.getenv("BATCH_SIZE")) def lambda_handler(event, context): project_list = [] try: projects = sample.get_projects() # プロジェクト一覧取得 count = 0 for project in projects: if count % BATCH_SIZE == 0: batch = [] batch.append({"project_id": project['id'], "project_key": project['projectKey']}) if count % BATCH_SIZE == BATCH_SIZE - 1 or count == len(projects) - 1: project_list.append(batch) count += 1 except Exception as e: print(e)
実行履歴クオータを回避する別の方法: AWS Step Functions Distributed Mapの利用
実行履歴のクオータ(25,000件)を回避するための別の方法として、AWS Step Functions Distributed Map(以下、Distributed Map)を利用することができます。Distributed Mapでは、Mapステートのイテレーションが個別の子ワークフローとして実行されます。このため、各子ワークフローには親ワークフローとは異なる実行履歴が存在し、親ワークフローの履歴に影響を与えることがありません。
Distributed Map の主な利点は以下の2点です。
大規模な並列処理のサポート
通常のMap ステートが 40の同時実行数制限があるのに対し、Distributed Mapでは最大10,000の並列実行をサポートしています。これにより、大規模なデータセットでも効率的な処理が可能です。独立した実行履歴管理
各子ワークフローは独自の実行履歴を持ち、親ワークフローとは別個に管理されます。そのため、親ワークフローの実行履歴クオータ(25,000 件)に影響を与えることなく、大量のイテレーションを処理できます。
これらの特徴により、Distributed Mapは以下の利点を提供します。
大規模な並列処理を効率的に実行
実行履歴クオータを超えるリスクを大幅に軽減
より多くの並列実行による処理時間の短縮
コストに関する注意点
Distributed Mapでは、各イテレーションが独立した子ワークフローとして実行されるため、通常のMapステートと比較して状態遷移回数に応じた追加コストが発生します。そのため、処理の規模や頻度に応じたコスト試算を行った上で、活用を検討することをお勧めします。
まとめ
本記事では、Step Functionsを使用したシステムのアーキテクチャにおける効率化の方法について説明しました。特に、実行履歴のクオータを回避するために、データの分割処理やMapステートの工夫を通じて、並列処理を最適化し、システムの安定性を向上させる方法を詳しく解説しました。
また、Distributed Mapを活用することで、さらに並列処理の効率化と処理時間の短縮を実現できることを紹介しました。これにより、Step Functionsの限界を意識しながらも、大規模なデータ処理をスムーズに行うことが可能です。
今後は、Step Functionsのシンプルでスケーラブルなワークフローを活かし、より柔軟で効率的なシステム設計を実現し、さらなるパフォーマンス向上を目指していきます。
寒さが増してきましたが、アドベントカレンダーも折り返し地点です。みなさまもクリスマスに向けて素敵な時間をお過ごしください!