
はじめに
NTTドコモ サービスイノベーション部の小原です。生成AI関連の業務する一方で、3D処理関係の手法に関して個人的興味を持っているため、最近はこの二つの要素を合わせた3D表現の生成(本記事では3D生成と呼ぶ)に関して調査しております。 その一環として、本記事では最近進化が著しくなったテキストや単体画像からの3D生成について、本タスクの説明から実際に生成を行う方法までの紹介をしようと思います。
テキストや単体画像からの3D生成って何?
本記事の「テキストや単体画像からの3D生成」とはそのままの意味で、単体画像やテキストを入力として、入力内容に基づいて3D表現を出力する手法を指します。 例えば、テキストから3D生成を行う手法の一種であるDreamFusion[1]では、以下の図の様に「a squirrel gesturing in front of an easel showing colorful pie charts」(カラフルな円グラフを示す画架の正面で身振りするリス)というテキストをモデルに入力すると、このテキスト内容に従った3D表現を出力することができます。

出力される3D表現のフォーマットにも種類があり、以下の4つが挙げられるかと思います。
- 3D点群: オブジェクトやシーンの表面に沿って点を敷いた表現となっている。視覚化時は、点(下図の青色)がどこにあるかで形を把握する。
- 3Dメッシュ: 頂点と辺と面の要素に従って表現される。面(下図の灰色)によってどの様な形を持っているか把握できる。
- 3Dボクセル: 3D空間のグリッド上にボクセルと呼ばれる四角の要素が並ぶ。画像に似た表現方法となっている。
- 自由視点画像: NeRF系統の手法で得ることができる、被写体に対する別視点の予測画像。

テキストや単体画像からの3D生成が何の役に立つのか?
テキストや単体画像からの3D生成は、3Dモデル作成の作業工数の削減やUser Generated Content(UGC)を目的としたサービスや検証で利用されていることが確認されています。
例えば、Meshy LLCが提供しているMeshy[2]はテキストや画像からの3Dモデルもしくは3Dモデルのテクスチャの生成を可能としているサービスです。こちらのサービスはゲーム開発者や3Dアーティストをターゲットとしており、3Dモデルのアセットを簡単に作成することを売りとしています。生成をすぐに試せるDiscord上の環境もある一方で、生成物のライセンスの取り決めなどを含む有料プランも用意されています。
他にも、Luma AI Inc.がGenie[6]というテキストから3Dモデルを生成するサービスを提供しており、こちらはDiscord上でテキスト入力をすることで3Dモデルを生成出来ます。
日本でも、今年の11/7に株式会社セガと東大スタートアップの株式会社EQUESがUGCへの応用が期待される3Dモンスター生成AIを発表[4]しました。こちらの生成AIは、簡単なキーワードの入力から3Dボクセルのモンスターが生成可能となっています。
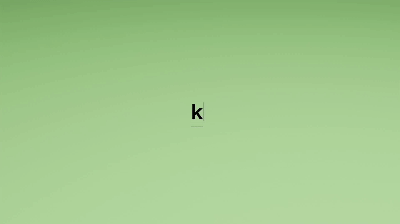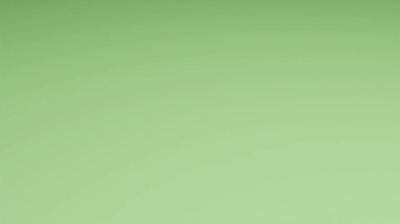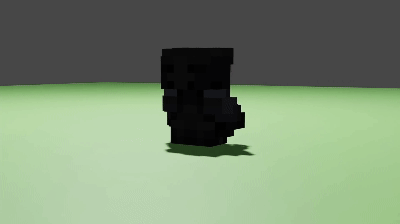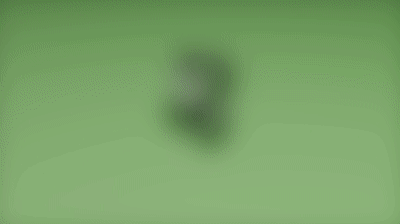
テキストや単体画像からの3D生成をすぐに試すことはできるか?
近年では、HuggingFaceのSpaces[21]というWebサービスで機械学習系手法のデモが公開されることがあり、テキストや単体画像からの3D生成手法も一部がSpacesで公開されています。Spacesは特にアカウントを用意せずとも簡単に試すことができます。手法のリスト[5]をベースにした2023/12/06時点での調査より、公式実装もしくはプロジェクトページからのリンクでSpacesのデモ公開が確認できた手法は以下の通りです(論文公開が早い順で並んでいます)。これらのデモで提供されている入力や出力のフォーマットは、手法ごとに異なるため注意してください(例: DreamGaussianは生成物を3D空間上で回転して表示できるが、Wonder3Dなどは生成物を画像でしか表示できないなど)。
また、Discordアカウントを作成する手間は増えるものの、「テキストや単体画像からの3D生成が何の役に立つのか?」の章内で紹介したMeshyやGenieも、Webやアプリですぐに生成を行うことができます。
実際に試してみよう!
「テキストや単体画像からの3D生成をすぐに試すことはできるか?」で紹介したSpaces上のデモの手法を用いて、生成を行ってみましょう! ここでは、比較的最近出た「Wonder3D: Single Image to 3D using Cross-Domain Diffusion」のSpacesのデモを使って、以下の単体画像の入力から生成までの説明を行います。
1. 入力画像選択
生成実験で使う被写体はトンカツです。この画像を入力するにあたって、良い生成結果を得られると思われる以下を考慮しています。
- 被写体と背景で色が完全に分けられている、背景が透過されているとなお良い。
- 被写体があまり複雑な見た目を持たない。

2. データの入力
Spacesのデモへアクセスすると、以下の図のページにアクセスできます。 アクセス後は、図の番号と以下のリスト番号の順に従って操作します。
- 画像を①にドラッグ&ドロップして画像を読み込ませる。
- ②は画像に対する前処理として、背景を自動で削除するかの選択です。画像の被写体のみが写っている&背景が透明の場合はチェックボックスを外し(背景透明な場合にチェックボックスを埋めたままにすると、被写体の一部が消えます)、そうでない場合はチェックボックスを埋める。
- ③をクリックで生成開始、生成後は画面下にスクロールして結果を確認する。

3. 出力の確認
トンカツの生成結果は以下の様になりました。2行6列に分かれており、行は生成画像の種類、列は見た角度ごとの画像で分かれています。行は二段に分かれおり、上段は予測された自由視点画像のカラー画像、下段は上段の法線マップを示します。法線マップは、オブジェクトの表面から垂直に向いている方向に従って色をつけた表現[8]で、この表現によって生成された物が形状的に正しいか判断しやすくなります。列は複数の視点から見た場合の自由視点画像を並べています。

裏面(右から三列目)は皿が適切に生成されておらず表面(左から一列目)の表現がそのまま写っていますが、他は適切に生成されているように見えます。裏面が欠けた理由は、単に皿裏のドメインを想定していなかっただけかと思います。今回は自由視点画像の生成となっているため、実際のアプリケーションで使用しやすい3Dメッシュデータへ変換した場合は品質が変わりそうではあります。
まとめ
本記事では、テキストや単体画像からの3D生成について、説明から任意の画像を用いた生成デモの利用までを紹介しました。本記事で紹介した3D生成手法は企業でも注目しており、商用利用を前提とした技術開発が進められています。また、テキストや単体画像からの3D生成技術はHuggingFaceのSpacesで簡単に試すことができ、生成までの手順説明と実験を行いました。実験結果では裏面の画像がイマイチになりましたが、それ以外は適切に生成されました。 最近のこの分野の発展は激しく、この記事を書いている間にもインパクトのある手法が提案されていました。今後も、さらに高品質かつ手軽に生成が可能な技術の提案がなされ、3Dトンカツも今回の実験より高品質な結果が得られることが期待できそうです。
参考文献
- [1] POOLE, Ben, et al. Dreamfusion: Text-to-3d using 2d diffusion. arXiv preprint arXiv:2209.14988, 2022.
- [2] Meshy LLC. Meshy | 3D AI Generator. [online]. [Accessed 2023/12/07]. Available from: Meshy.ai: https://www.meshy.ai/
- [3] GKIOXARI, Georgia; MALIK, Jitendra; JOHNSON, Justin. Mesh r-cnn. In: Proceedings of the IEEE/CVF international conference on computer vision. 2019. p. 9785-9795.
- [4] 株式会社EQUES. 東大松尾研発スタートアップ「EQUES」、セガと共同で3Dモンスター生成AIの開発(PoC)を発表. [online]. 2023/11/07. [Accessed 2023/12/07]. Available from: https://prtimes.jp/main/html/rd/p/000000005.000101360.html
- [5] yyeboah. yyeboah/Awesome-Text-to-3D: A growing curation of Text-to-3D, Diffusion-to-3D works. [online]. 2023/11/26. [Accessed 2023/11/27]. Available from: https://github.com/yyeboah/Awesome-Text-to-3D
- [6] Luma AI Inc. Genie, a research preview of Luma's generative 3d foundation model. [online]. [Accessed 2023/12/07]. Available from: https://lumalabs.ai/genie
- [7] POOLE, Ben, et al. DreamFusion: Text-to-3D using 2D Diffusion. [online]. [Accessed 2023/12/07]. Available from: https://dreamfusion-cdn.ajayj.com/gallery_sept28/crf20/a_squirrel_gesturing_in_front_of_an_easel_showing_colorful_pie_charts.mp4
- [8] Wikipedia. 法線マッピング - Wikipedia. [online]. 2023/07/17. [Accessed 2023/12/07]. Available from: https://ja.wikipedia.org/wiki/%E6%B3%95%E7%B7%9A%E3%83%9E%E3%83%83%E3%83%94%E3%83%B3%E3%82%B0#
- [9] GUO, Ziyu, et al. Point-bind & point-llm: Aligning point cloud with multi-modality for 3d understanding, generation, and instruction following. arXiv preprint arXiv:2309.00615, 2023.
- [10] MELAS-KYRIAZI, Luke, et al. Realfusion: 360deg reconstruction of any object from a single image. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023. p. 8446-8455.
- [11] WANG, Haochen, et al. Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023. p. 12619-12629.
- [12] SEO, Junyoung, et al. Let 2d diffusion model know 3d-consistency for robust text-to-3d generation. arXiv preprint arXiv:2303.07937, 2023.
- [13] LIU, Ruoshi, et al. Zero-1-to-3: Zero-shot one image to 3d object. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023. p. 9298-9309.
- [14] ARMANDPOUR, Mohammadreza, et al. Re-imagine the Negative Prompt Algorithm: Transform 2D Diffusion into 3D, alleviate Janus problem and Beyond. arXiv preprint arXiv:2304.04968, 2023.
- [15] LIU, Yuan, et al. SyncDreamer: Generating Multiview-consistent Images from a Single-view Image. arXiv preprint arXiv:2309.03453, 2023.
- [16] TANG, Jiaxiang, et al. Dreamgaussian: Generative gaussian splatting for efficient 3d content creation. arXiv preprint arXiv:2309.16653, 2023.
- [17] YI, Taoran, et al. Gaussiandreamer: Fast generation from text to 3d gaussian splatting with point cloud priors. arXiv preprint arXiv:2310.08529, 2023.
- [18] LONG, Xiaoxiao, et al. Wonder3d: Single image to 3d using cross-domain diffusion. arXiv preprint arXiv:2310.15008, 2023.
- [19] SHI, Ruoxi, et al. Zero123++: a single image to consistent multi-view diffusion base model. arXiv preprint arXiv:2310.15110, 2023.
- [20] MeshyAI. Introducing Meshy-1: Generate 3D Models with AI in Just a Minute. YouTube [online]. 2023/10/21. [Accessed 2023/12/07]. Available from: https://www.youtube.com/watch?v=ueQB1fzXy-s
- [21] Hugging Face. Spaces - Hugging Face. [online]. [Accessed 2023/12/07]. Available from: https://huggingface.co/spaces