
はじめに
はじめまして、NTTドコモ サービスイノベーション部、2年目社員の韓です。 今回、アドベントカレンダーのラスト記事を書かせていただきます!初めてのブログ投稿のため、お手柔らかにお願いいたします<m(__)m>
本記事では、画像認識の分野で良く使われるCNN(畳み込みニューラルネットワーク)と、音楽データのメルスペクトログラム(人の聴覚に基づいた尺度によるスペクトル画像)を用いて、音楽の感情認識を画像分類問題として解いてみたことについて書きたいと思います。 また、この記事は業務DXを追求する観点で、LLM(Large Language Models)をフル活用して執筆してみました。読みにくかったら申し訳ありません!(LLMによる出力箇所は、引用として区別しています。)
CNNとメルスペクトログラムを用いた音楽認識について(from GPT-4)
“近年、音楽認識技術は飛躍的に進化しており、その中でもCNN(Convolutional Neural Network、畳み込みニューラルネットワーク)とメルスペクトログラムを用いた手法が注目されています。 音楽認識では、音楽の要素であるメロディ、リズム、和音などを高精度で識別することが求められます。そのためには、音楽を時系列データとして扱い、それらの要素を特徴量として取り出すことが必要です。
この特徴量抽出に非常に有用なのが「メルスペクトログラム」です。メルスペクトログラムは人間の聴覚特性に基づいて周波数軸を変換し表示します。この変換は、メルスケールと呼ばれる人間の聴覚特性のスケールに基づいて行われます。メルスペクトログラムは、音声信号の周波数特性をより人間の聴覚に近い形で表現するため、音声処理や音声解析において広く使用されます。メルスペクトログラムを、時間を横軸、周波数を縦軸で表示し、音の強さを色で表現する画像化を行うことで、一見複雑に見える音楽データを画像のように扱い、特徴量抽出を効果的に行うことができます。
そして、このメルスペクトログラムを画像として扱い、高度な画像認識を可能にするCNNを用いる研究が進められています。CNNとメルスペクトログラムを組み合わせることで、音楽の各要素を高精度に識別し、音楽のジャンル認識、曲識別、音楽生成など、様々な音楽認識タスクに対応することが可能になってきています。”
ということで、CNNとメルスペクトログラムを用いた音楽認識技術が、ここ数年、注目を集めています。最も権威のある国際的なオーディオ検索・評価コンペティションであるMusic Information Retrieval Evaluation eXchange (MIREX) [1]でも、近年音声感情分類の精度が一番高いのはメルスペクトログラムとCNNの組み合わせになっています。
データセットの選定
今回の検証では、CAL500 Expansion(CAL500exp) [2]というオープンデータセットを使いました。このデータセットは、表1に記載の通り、3000セグメント以上の音楽の断片に、専門家によって音楽に関する感情・楽器・歌唱のタグが付与されているものであり、信頼性とともにデータ量も多く、ひとまず、感情認識を試してみるには最適なものになっています。

CAL500expには、表2に示す通り、67個の感情・楽器・歌唱に関するタグが付いており、今回の検証ではそのうち、以下の3つの感情(Emotion)タグを用い、音楽がCalming/Soothing (心を落ち着かせる/なだめる)か否かを分類するタスクを行ってみました。
- Calming/Soothing (心を落ち着かせる/なだめる)
- Angry/Aggressive (怒っている/攻撃的)
- Exciting/Thrilling (エキサイティング/スリルがある)

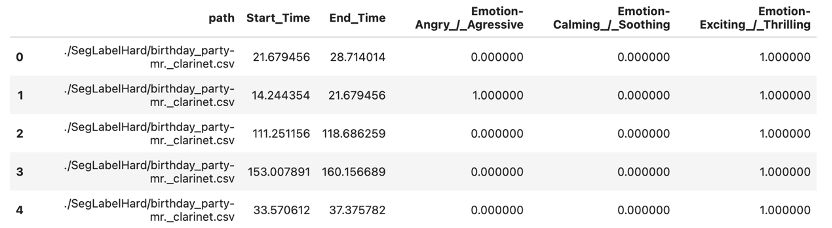
データセットは、図1のように、音楽データ中のセグメントの開始時刻と終了時刻と、そのセグメントにおけるタグが付与されています。
メルスペクトログラムの作成
音楽のセグメントは図2に示す通り長さがバラバラのため、短いセグメントはリピートするなどして17秒の長さに統一し、Waveファイル形式に変換しました。

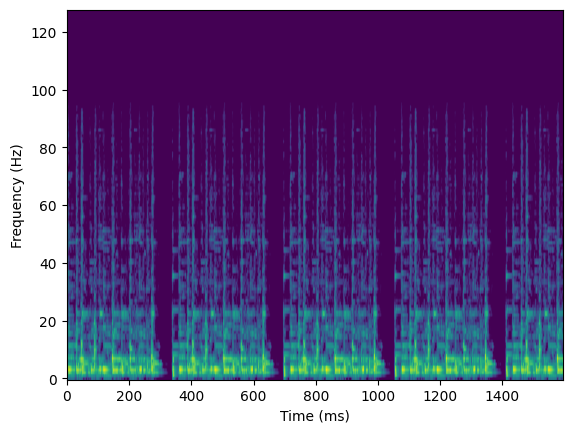
次に、17秒に統一したWaveファイルをメルスペクトログラムに変換し2次元の同じサイズの画像を生成しました。変換プログラムはLibrosa[4]というPythonの音響解析および信号処理のライブラリを用いました。
# waveデータをメルスペクトログラムに変換する def wave2melspecs(waves, fs, db): melspecs = np.empty(shape=(db.shape[0], 128, 1594, 1)) for i, wave in enumerate(waves): melspec = librosa.feature.melspectrogram(y=wave, sr=fs) logspec = librosa.amplitude_to_db(melspec) melspecs[i,] = np.expand_dims(logspec, axis=-1) return melspecs
# 全データをメルスペクトログラムに変換する
melspecs = wave2melspecs(waves, sampling_rate, selected_rows)
コードで生成したメルスペクトログラムのサンプルを示します。また、改めて、メルスペクトログラムの特徴について説明を追加しておきます。
メルスペクトログラムとは(from GPT-4)
“メルスペクトログラムは、音声信号の周波数成分を可視化するためのグラフであり、主に音声処理や音響解析の分野で使われます。通常のスペクトログラムでは、周波数成分が一様に分割されますが、メルスペクトログラムでは人間の聴覚特性を考慮して縦軸がスケール変換されます。メル尺度という特殊なスケールを用いることで、より人間の聴覚に近い分解能で周波数成分を表現することができます。メルスペクトログラムは、横軸に時間、縦軸にメル周波数を表示し、その時間点での音声信号のメル特性を色や濃度で表現します。このようにすることで、音声信号の周波数成分の変化やパターンを人間の聴覚に合わせて視覚的に把握することが可能です。メルスペクトログラムは、音声の特徴抽出や音声分類、音声認識などの音声処理タスクにおいて有用なツールとされています。”
感情分類モデル
今回の感情分類に用いるCNNモデルとして、この論文 [5]に使われているような2D-CNNのモデルを流用しました。2D-CNNは畳み込み層とプーリング層のセットを重ねたシンプルな構造で、下記に示すような特徴があります。
2D-CNNとは?(from GPT-4)
“2D-CNN(2次元畳み込みニューラルネットワーク)は、2次元のデータ(画像など)を処理するための畳み込みニューラルネットワーク(CNN)のことです。
CNNは、ビジュアル認識タスクに広く使用され、特に画像の分類、物体検出、顔認識などのタスクで優れたパフォーマンスを発揮します。具体的には、CNNは、画像の局所的な特徴を抽出する畳み込み層と、特徴量のサイズを縮小するプーリング層で構成されています。
2D-CNNは、この畳み込み層とプーリング層の操作を2次元のデータに対して適用します。すなわち、2D-CNNは、画像の幅と高さの両方に沿ってフィルタをスライドさせることで、画像の各部分から特徴を抽出します。
この2D-CNNの性質により、画像のどこに特定の特徴が存在してもそれを検出でき、物体の位置や姿勢の変化に対しても鮮明性を保つことができます。そのため、2D-CNNは画像認識タスクに非常に適しています。”
分類タスクと精度
データセットとモデルの準備ができたので、最後に分類タスクの内容とその結果について共有します。前述の通り、今回の検証では以下の3つの感情(Emotion)タグを用い、音楽がCalming/Soothing (心を落ち着かせる/なだめる)か否かを分類するタスクを行ってみました。
- Calming/Soothing (心を落ち着かせる/なだめる)
- Angry/Aggressive (怒っている/攻撃的)
- Exciting/Thrilling (エキサイティング/スリルがある)
音楽がCalming/Soothing (心を落ち着かせる/なだめる)か否かを分類するタスクで、なぜ3つの感情(Emotion)タグを用いたのかについてですが、単にCalming/Soothingのタグだけを用いて学習を行っても高い精度が出なかったためです。
そのため、Angry/Aggressive(怒っている/攻撃的)とExciting/Thrilling(エキサイティング/スリルがある)も用いて、下記のような正例と負例で学習データを整理しました
Angry/AggressiveとExciting/Thrillingは、Calming/Soothingの感情から一番離れていると想定し、そのどちらかがtrueでCalming/Soothingがfalseのデータを負例にすることで、より精度の高いモデルが作成できると考えました。
- 正例:Calming/Soothing =true
- 負例:「Calming/Soothing =falseかつExciting/Thrilling =true」 or 「Calming/Soothing =falseかつAngry/Aggressive =true」
最後に検証結果です。Calming/Soothing (心を落ち着かせる/なだめる)か否かを判断する二値分類の問題に対して、テストデータに対する評価を行いました。図4に示すように、少し過学習気味ではありますが、、、正確度(accuracy)は約0.8程度という、ある程度の精度の分類モデルを得ることができました。また、主観評価した結果でも高い精度が確認できました。

最後に
今回は、CNNとメルスペクトログラムを使って音楽感情認識を試してみました。既存のデータセットやモデルを利用するだけで、かなり簡単にある程度の精度の感情分類モデルを得ることができました。音楽を感情分類するという少し複雑なタスクが、CNNを用いることで簡単に実現できることを改めて実感できました!
音楽の感情認識は、音楽サービスのレコメンデーション、音楽療養、さらには、ユーザの感情状態に応じて最適な音楽やBGMを自動再生するようなアプリケーションなど、幅広い範囲応用が考えられます。
音楽感情認識を用いたサービスはまだまだ少ないです。この記事を読んで、新しいサービスを開発するための素晴らしいアイデアが生まれることを期待しています。
メリークリスマス!2024年もあなたに幸せが訪れますように。
参考文献
[1] https://www.music-ir.org/mirex/wiki/MIREX_HOME
[2]https://paperswithcode.com/dataset/cal500exp
[3] Towards time-varying music auto-tagging based on CAL500 expansion, SY Wang, JC Wang, YH Yang, HM Wang, 2014 IEEE International Conference on Multimedia and Expo (ICME).
[4] Librosa - https://librosa.org/
[5] Deep-Learning-Based Speech Emotion Recognition Using Synthetic Bone-Conducted Speech, Md. Sarwar Hosain, Yosuke Sugiura, Nozomiko Yasui, Tetsuya Shimamura, Journal of Signal Processing 27(6) 151-163, 2023.