
NTTドコモ R&Dイノベーション本部 サービスイノベーション部
ビッグデータ基盤担当 3年目社員の小澤です.
普段の業務では, 1日数百TBにわたる弊社のLTE/5GSA基地局の通信制御信信号をリアルタイムで分析可能とし, ネットワークエリア品質向上に役立つデータへ変換するシステムの研究開発業務に携わっており, いわゆるデータエンジニア的な業務に携わっております.
2年前は自身の業務に関連するロードバランサ関連技術やOSS, 昨年は, 東京ディズニーシーの混雑分析について投稿しました.今年は, 11/27〜12/2にアメリカのラスベガス現地で参加させていただいたAWS:re:Invent2023に関しての記事を投稿します. 普段の業務では, Kinesis, Athena, ElastiCache, S3, RDS, EC2 on ECS等の大量のデータをリアルタイムで扱うために必要なサービスを主に使用しています . 入社3年目という若手ながら, 世界中からAWSに関する有識者が集まる盛大なイベントである, AWS re:Invent2023への参加の機会をいただき, 貴重な経験をさせていただきました!現地にて習得した知識をチームや組織に還元し, 技術検証に繋げてシステムの質を向上させることが主な目的でした. アウトプットの1つとしてこちらの記事を投稿します. 所々で, パワーポイント形式の資料の図を添付しますが, 社内の勉強会や会議向けに作成した資料をカスタマイズした内容になっております.

目次
- 目次
- AWS re:Inventとは?
- ビッグデータ基盤屋として, 気になったKeynote & サービスアップデート
- Keynoteとは?
- Adam Selipsky CEOによるKeynote-生成AI関連機能の拡充
- Dr. Werner CTOによるKeynote-コストを非機能要件に組み込め
- Amazon Aurora Limitless Database
- Amazon S3 Express One Zone storage class
- Amazon Q generative SQL in Amazon Redshift Query Editor
- CloudWatch-AI-powered natural language query generation
- Amazon Q in QuickSight
- CloudWatchLogs- Infrequent Access log class
- Amazon QがGlueに統合 & Glue Data Qualityが, 動的ルールとMLベースの異常検出に対応
- 生成AI, データ分析, ETL系の新サービスを触ってみる!
- まとめ & 今後の意気込み
AWS re:Inventとは?
AWS re:Inventとは, Amazon Web Services(AWS)が主催し, 毎年ラスベガスで開催されるAWSの新サービス, 今後の方向性の発表や各種サービスの詳細から事例のセッション, 実際に参加者で手を動かすワークショップ等の学習型カンファレンスです.

ビッグデータ基盤屋として, 気になったKeynote & サービスアップデート
Keynoteとは?
Keynoteとは, AWS re:Inventの中でも最も聴講者数が多く, 新サービスの発表やAWSの今後の方向性が感じられるスピーチのことです. 現地での熱気や盛り上がりが, とにかくすごかったです. 今年の主な話題は, 予想通り生成AI関連となりました.

Adam Selipsky CEOによるKeynote-生成AI関連機能の拡充
 CEOのAdam SelipskyによるKeynoteは, 参加したKeynoteの中で最も盛り上がっていると感じました. Amazon QやBedrock等の生成AIサービスの新機能の発表が中心となりました. その中でも, Amazon Qの発表は, 大盛り上がりでした. 後ほど, 述べますが各種ETL, データ分析系のサービスにもAmazon Qが組み込まれており, コードレスでアプリケーションの構築や高度な分析が可能になることが期待できると感じました. 生成AI関連の機能を, 「インフラ, アプリケーション, Bedrockを中心としたLLMやFMを用いたbuildツールの3つの層に分けて対応していく」と述べており, 利用者の様々なユースケースに応じて対応できると感じた一方で, ここまで対応してくれると, ますます特定のクラウドベンダへの依存度も高まっていくのではないかと感じました.
CEOのAdam SelipskyによるKeynoteは, 参加したKeynoteの中で最も盛り上がっていると感じました. Amazon QやBedrock等の生成AIサービスの新機能の発表が中心となりました. その中でも, Amazon Qの発表は, 大盛り上がりでした. 後ほど, 述べますが各種ETL, データ分析系のサービスにもAmazon Qが組み込まれており, コードレスでアプリケーションの構築や高度な分析が可能になることが期待できると感じました. 生成AI関連の機能を, 「インフラ, アプリケーション, Bedrockを中心としたLLMやFMを用いたbuildツールの3つの層に分けて対応していく」と述べており, 利用者の様々なユースケースに応じて対応できると感じた一方で, ここまで対応してくれると, ますます特定のクラウドベンダへの依存度も高まっていくのではないかと感じました.
Dr. Werner CTOによるKeynote-コストを非機能要件に組み込め
Dr. WernerのKeynoteは, 非常に大事なことを述べていると感じました. 「The Frugal Architect」, 倹約なアーキテクト実現のための7つの法則を紹介しました. 一般的にシステムにおける非機能要件は, 「性能」, 「セキュリティ」, 「可用性」, 「運用のしやすさ」等が挙げられるかと考えられます. しかし, Dr.Wernerは「コスト」を非機能要件に組み込めと言っております. 監視していないシステムは, 見えないコストを産み出し, 結果的に無駄なコストが生じてしまう. ここは, とても共感しました. システムにおけるコスト最適化は, 面白くなく重要でないと考えられる傾向にあると感じますが, 実際にはシステム全体を理解して, 監視しなければならず学びになる部分も多いです. 入社1年目の際に, コスト最適化を任された際にはモチベーションが低かったのですが, 当時の上長からコスト最適化はシステム全体の理解に繋がるし, 学びになる部分が多くチームとしての貢献が大きいと言われたことが今になって, やっと理解できました. 以下に記載する4点を意識することで, Dr.Wernerの言う「The Frugal Architect」の実現へと繋がるのではないかと考えます.
- 可視化
- 最適化
- FinOpsの実践
- 予測と計画
所属するチームでは, 監視の強化, 自動化対応, チーム内でのコストの意識化により数千万円/年のコスト削減実績があり, チーム全体でコストの最適化・意識化が進んでおります. 「The Frugal Architect」の実現のため, 7つの法則を意識していくことは重要であると感じました.

Amazon Aurora Limitless Database
Amazon Aurora Limitless Databaseにより, Auroraの書き込み性能を大幅に向上させることができる(数百万/秒)ようになりました. 従来では, 書き込み性能を向上させるためには, インスタンスタイプを上げる(垂直方向スケール), 複数のDBを用意する(水平方向スケール)必要がありました. また, 複数のDBを扱うためにはデータの一貫性を担保するために同一主キー相当のデータは同一のDBへ分散する工夫が求められ, アプリとインフラの運用負担増加が課題でありました. 今回のupdateによってインフラ部分の運用負担の軽減に繋がり, 読み込み性能を向上させる際に利用されるリードレプリカと同様の要領で書き込み性能を向上させることができます. ただし, 以下の図にも示しているように, 自身でShard数とShard Keyを定義して書き込み先を振り分ける必要があるため, この点は意識する必要があり, アプリケーションの改修も必要になります.

Amazon S3 Express One Zone storage class
Amazon S3 Express One Zoneは, 通常のS3スタンダードクラスは3つのAZにデータを書き込みのに対して1つのAZにしかデータを書き込まない代わりにデータのアクセス速度を10倍以上向上させたものです. Athena, SageMaker, EMR, Mountpoint等のS3をデータソースとして利用するサービスの性能が軒並み向上するとのことです. Keynoteでの発表時には, リクエストコストが50%削減されるとのことで盛り上がっていましたが, ストレージのコストは10倍近く上昇しており, 前述したサービスを利用する場合には, それなりの規模のデータを扱う必要があると考えられため, 総コストは上昇してしまうケースが多いのではないでしょうか? コストと, 性能のバランスを考慮して本番環境に適用するか, 検討していきたいですね.

Amazon Q generative SQL in Amazon Redshift Query Editor
RedshiftのSQLのクエリ生成に, Amazon Qが統合されました. 自然言語でSQLクエリを生成することが可能であるため, 知識の差を吸収した分析が可能になることを期待しております. モバイルネットワークの部署の方が自然言語をベースとしたネットワーク分析, 営業関連部署の方が 売上に関するデータを自然言語をベースとした分析が可能になることでお客様への価値が向上するような施策に繋げることができれば, 素晴らしいと感じました.

CloudWatch-AI-powered natural language query generation
CloudWatch Logs Insightsで自然言語を用いて, クエリ生成が可能になりました. 所属するチームでは, CloudWatch Logs Insightsを用いてアプリケーションのエラーログ等を解析することが多いのですが, Insights特有のクエリを記述しなければならず学習コストが課題でありました. 学習コストのみが課題であれば, 学習すれば良いのですがSQLと比較すると特殊で書きずらいと感じておりました. その中で, 自然言語でクエリを生成して分析が可能になるとのことで分析の負担の軽減に繋がることを期待します. ログの分析は, 機能の開発担当者でないと対応することが難しいことが多いのですが, 本機能を利用することで属人化の防止にも繋げられるとベストだと感じます.

Amazon Q in QuickSight
QuickSightにAmazon Qが統合されました. こちらは, Keynoteでの発表時に大盛り上がりでした. QuickSightで見やすいダッシュボードを作成するためには, 知識やデザインの工夫が必要になり少し手間が掛かってしまう印象を受けます. 本機能によって, 自然言語でストーリーを与えることでダッシュボードを作成することができます. こちらの機能も同様に, 有識者との知識の差を吸収してデータの可視化が容易になると弊社での更なる顧客価値の向上に繋げられるようになることを期待します.

CloudWatchLogs- Infrequent Access log class
こちらは, コスト最適化関連のアップデートになります. S3では, 低頻度用のアクセスクラスが存在しますが, ここでCloudWatchLogsにも同様のクラスが発表されました. 通常のCloudWatchLogsと比較すると機能に大きな制限があるように感じますが, あまり使い込んでいない & データ規模が大きい場合にはコスト最適化として, 有用な機能になるかと考えます. ストレージ料金は, 通常通り発生します. コスト最適化の選択肢として, 覚えておくと良いのではないでしょうか. ただし, 紹介したCloudWatchLogs Insightsのクエリ自動生成機能を使うことができません.

Amazon QがGlueに統合 & Glue Data Qualityが, 動的ルールとMLベースの異常検出に対応
Amazon QがGlueに統合されました. 自然言語で, Pythonスクリプト等の言語でETL処理用のスクリプトを生成することができます. Glueにまで, Amazon Qが統合されコードレスで, ETL処理ができるようになる未来も遠くないのかもしれません. 近いうちにRDS, Athena, EMR, Kinesis(Amazon Managed Service for Apache Flink)あたりの機能にも対応するのではないでしょうか?また, Glue Data Qualityが, 動的ルールとMLベースの異常検出にも対応し, 処理中におけるデータの品質監視力が向上します. 質の高いETL処理実現のためには, 有効的な機能だと感じます.

生成AI, データ分析, ETL系の新サービスを触ってみる!
それでは, 実際にre:Inventで発表された新サービスであるAmazon QとRedshift, CloudWatch Logs Insightsのクエリ自動生成機能について検証してみます!
Amazon Q
Amazon Qとは, 今年のre:Inventの目玉の新サービスでAWS版のChatGPTと理解していただいて構いません. AI chat botを通じてAWSに関する質問をすることができます.


(日本語訳) VPCエンドポイントを経由してS3に接続できない原因として、以下が考えられます: VPCエンドポイントに関連付けられているサブネットは、インターネットまたはNATゲートウェイへのルートを持っていません。S3 VPCエンドポイントは、DNS名を解決するためにインターネットアクセスが必要です。 プライベートDNSがVPCエンドポイントで有効になっているが、S3サービスがプライベートDNS解決をサポートしていない。S3インターフェイスエンドポイントはプライベートDNSをサポートしていません。 セキュリティグループとネットワークACLがVPCエンドポイントとS3間のトラフィックをブロックしています。ポート443は開いている必要があります。 VPCエンドポイントポリシーが、エンドポイントを使用するプリンシパルに必要なアクション(s3:GetObjectなど)を許可していません。 パブリックホスト名を使用している場合、DNS解決に失敗します。VPC で DNS が正しく設定されているか確認してください。 VPC エンドポイントが "pending" または "deleting" 状態であり、まだ完全に作成されていません。使用するには「使用可能」状態である必要があります。 いくつか試してみてください: S3インターフェースのエンドポイントを作成する際にプライベートDNSを無効にする。 S3エンドポイントへのポート443での接続性をテストするためにtelnetを使用する。 セキュリティグループとネットワークACLルールを確認する ソース
RedshiftでのSQLクエリ自動生成
Amazon Qと同様に, オレゴン(us-west-2)とバージニア北部(us-east-1)リージョンでのみで利用可能になっております. 今回は, オレゴンリージョンでの環境構築を進めます. Amazon Qとは異なり, 日本語での入力を受け付けてくれるようでした. しかし, クエリ結果に日本語を含んでしまい, 期待するカラム名とならないことや, 英語で指示を与えた際よりも期待するクエリの生成確率が低かったため今回は英語での入力としております.
Redshift環境の構築
今回は単発での検証のためRedshift Serverlessを利用しました. 対象のVPCと3つのサブネットさえ構築しておけば簡単に分析環境を構築することができます. 5分程度でできました.
サンプルデータベース-TICKITを利用
Redshiftのquery editorでTICKITデータベースを選択します. 架空のWebサイト「TICKIT」上で販売されたスポーツイベント, ショー, コンサート等のチケットの購入者や販売者, 開催場所, 開催地域等を確認することができます. (TIKITデータベースについて)
簡単なSQLのクエリ自動生成を試してみる
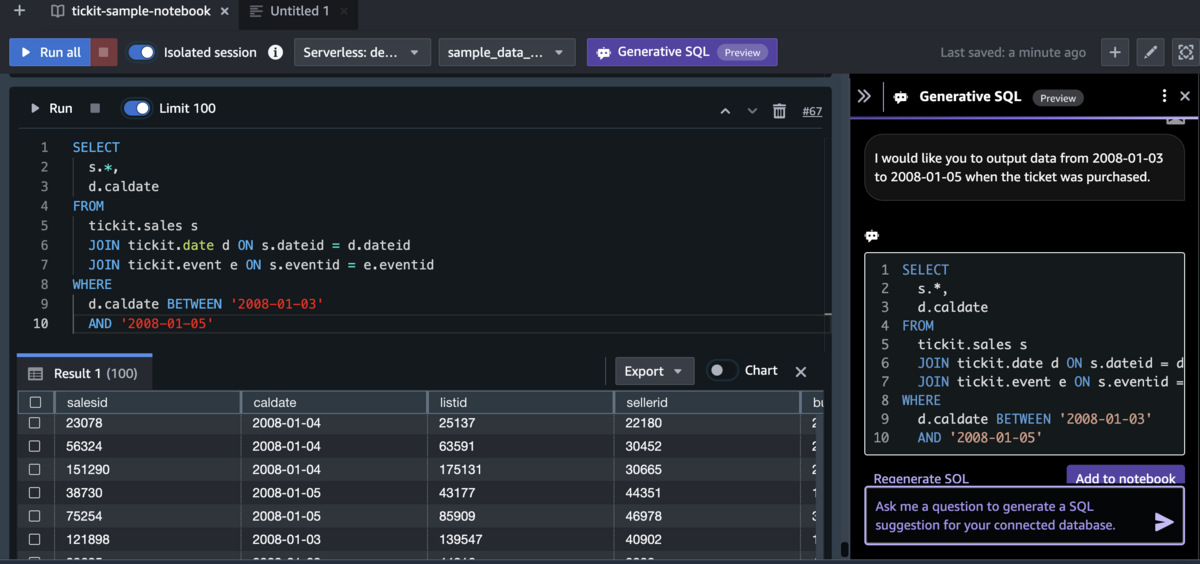
初めに, 簡単なクエリを生成できるのか検証してみます. 売り上げ日(caldate)が, 2008-01-03から2008-01-05の情報を出力して欲しいとフワッとした要望を投げてみます. 入力文としては, 画像にあるように以下のように与えました.
I would like you to output data from 2008-01-03 to 2008-01-05 when the ticket was purchased. (日本語訳: チケットが購入された, 2008-01-03から2008-01-05までのデータを出力してほしい)
購入日の日付, 2008-01-03から2008-01-05に限定した出力になっておりますし, 売上に関する情報も出力されていて期待するSQL文が生成されていそうです. 自然言語を与えただけで, BETWEEN句まで用いている点に驚きました!
やや複雑なSQLのクエリ自動生成と答え合わせ
続いて先ほどのクエリよりもやや複雑なものを生成できるかを検証してみます. 今度は逆算的に生成されたクエリが正確であるかを検証するために, Documentに存在するSQL分を参考にします. 以下のSQLクエリの結果と同様のクエリを自然言語から生成することができるのでしょうか?
select sellerid, username, (firstname ||' '|| lastname) as name, city, sum(qtysold) from sales, date, users where sales.sellerid = users.userid and sales.dateid = date.dateid and year = 2008 and city = 'San Diego' group by sellerid, username, name, city order by 5 desc limit 5; sellerid | username | name | city | sum ----------+----------+-------------------+-----------+----- 49977 | JJK84WTE | Julie Hanson | San Diego | 22 19750 | AAS23BDR | Charity Zimmerman | San Diego | 21 29069 | SVL81MEQ | Axel Grant | San Diego | 17 43632 | VAG08HKW | Griffin Dodson | San Diego | 16 36712 | RXT40MKU | Hiram Turner | San Diego | 14 (5 rows)
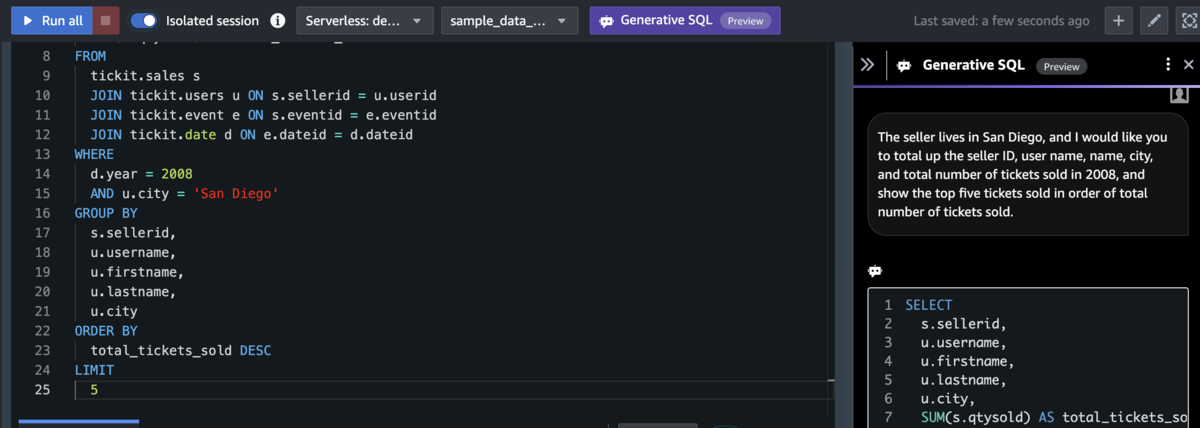
Documentに記載されている上記と同じSQLクエリ結果が得られるように, SQLを生成できるか検証してみます. それなりに複雑なクエリですので, これを自然言語で生成できたらすごいですよね. 入力文としては, 画像にあるように以下のように与えました.
The seller lives in San Diego, and I would like you to total up the total number of tickets sold in 2008 by seller ID, user name, name, city, and total number of tickets sold, and show the top 5 tickets sold in order of the total number of tickets sold. (日本語訳: 売主の居住地域はサンディエゴで, 2008年のチケットの合計売り上げ数について, 売主ID, ユーザー名, 氏名, 都市名, 合計売り上げ数を集計し, 合計売り上げ数の多い順に上位5件を表示して欲しい.)
生成されたSQLは, 添付画像に示すように以下のようになりました.
SELECT s.sellerid, u.username, u.firstname, u.lastname, u.city, SUM(s.qtysold) AS total_tickets_sold FROM tickit.sales s JOIN tickit.users u ON s.sellerid = u.userid JOIN tickit.event e ON s.eventid = e.eventid JOIN tickit.date d ON e.dateid = d.dateid WHERE d.year = 2008 AND u.city = 'San Diego' GROUP BY s.sellerid, u.username, u.firstname, u.lastname, u.city ORDER BY total_tickets_sold DESC LIMIT 5
- JOIN句が含まれている
- 意味のない内部結合(JOIN)
元のSQLクエリには, JOIN句が含まれておりませんでしたね. また, 以下のJOINはクエリ生成の際に指示を与えておりませんし, 全く意味のないJOIN句になってしまっています.
JOIN tickit.event e ON s.eventid = e.eventid
生成されたSQLクエリ自体は, 異なるものの意味は同じとなりクエリ結果も同じになりました. 自然言語で目的のクエリを生成してくれており, すごいと感じました. それなりに複雑なクエリだと感じますが, 複数のデータやカラムを参照してクエリを生成してくれている点に感激しております!

考察と注意事項
今まで述べた自然言語からSQLの生成ですが, 必ずしも上手くいくとは限りません. 上手くいった場合の結果を載せております. 注意すべき点と気になった特徴としては, 以下が挙げられます.
- 最低限扱うデータベースの構造とカラムの意味くらいは理解しなければならない
- JOINでのアプローチで, SQLクエリを生成しようとするため, 条件によって期待するものとは異なるものが複数回得られた
- 売主の住所, 「サンディエゴ」をJOIN Keyとすべきがイベントの会場をKeyとしてしまう
- 販売日をJOIN Keyとすべきところを発売日をKeyとしてしまう
- 明確なカラム名の指定等, クエリ生成の指示を明確にしないとミスが発生しやすい
- 人間でもカラム名のミスは発生しやすいため, カラム名の明確な指示くらいは必要
人間でも誤りが多い部分は, 生成AIでも難しいということが言えるのではないでしょうか. あるデータを扱う以上は分析者がデータベースの中身をしっかりしておくことが必要でありそうです. DWHには大規模なデータが置かれていて, 複数の類似するカラムが存在する場合があるでしょうから, それまで考慮してSQLを自動生成することは, さすがに難しいのかもしれませんね. 実際に, 「2008年のサンディエゴの売り上げ総数を算出して」だけでは, 目的のクエリは生成されにくく, 「 売主の居住地域はサンディエゴで, 2008年のチケットの合計売り上げ数について, 売主ID, ユーザー名, 氏名, 都市名, 合計売り上げ数を集計し, 合計売り上げ数の多い順に上位5件を表示して欲しい」まで指定してあげなければ, 目的のクエリは生成されませんでした. 当たり前と言えば, 当たり前かもしれませんが, 生成AIであれば何でもできるという訳ではないので, 扱うデータの仕様は最低限理解して投げ掛けることが必要そうです. 技術的難易度が高いと思いますが, 何も考えずに自然言語を投げて目的のSQLを生成してもらうには時間が掛かりそうですね・・・
CloudWatch Logs Insigntsでのクエリ自動生成
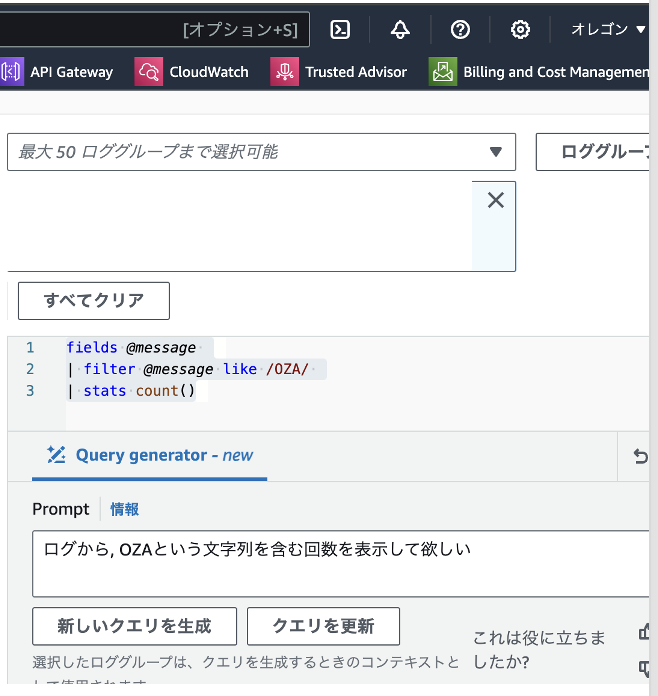
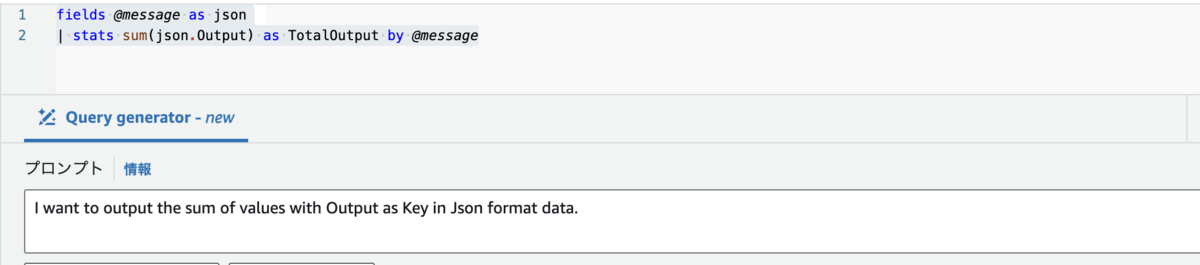
こちらも同様, オレゴン(us-west-2)とバージニア北部(us-east-1)リージョンでのみで利用可能であるためオレゴンリージョンで検証を実施しました. 日本語のリクエストを受け付けてくれる時と失敗する時があるため, 英語と日本語の両方で検証してみます. CloudWatch Logs Insigntsで, ログの分析をする際にはInsignts特有のクエリの記述が必要で, 苦戦することが多々ありました. 自然言語でのクエリ自動生成の対応がどの程度の効果を発揮するのか検証してみます. まずは, ログに「OZA」という文字列が何件含んでいるかを検索するよう指示を与えました.
こちらは, 目的のクエリが生成されていそうです.
まとめ & 今後の意気込み
現地でAWS re:Inventの熱気, 新サービス発表の盛り上がりを体感することができ, とても貴重な経験をさせていただきました. 5日間, 毎日が楽しくあっという間に時過ぎてしまいました・・・日々の業務に一生懸命取り組んで, 技術を習得し, また参加したいと思います. 参加させていただいたことにより, 日々の業務のモチベーションにも繋がりましたので, 以下の3点を目標に頑張っていきたいと思います!!
- AWS資格を全冠すること
- AWSのコミュニティ活動に積極的に参加し, 視野を広げた技術的知見や繋がりを持つこと
- 英語を円滑に話せるようになること・・・