
NTTドコモ R&Dイノベーション本部 サービスイノベーション部 ビッグデータ基盤担当 4年目社員の小澤です。
2023年に続いて2年連続で、ラスベガス現地にて2024 AWS re:Inventに参加させていただきました。このような機会を作っていただいた、会社や自組織、チームのメンバーにはたいへん、感謝しております。期間中に発表されたアップデートの中でも、特に注目しているS3 Tablesと中身を深く理解するために、Apache Icebergの解説記事を投稿します。
AWS利用の若手エンジニア代表である2024 Japan AWS Jr. Championsと全資格保有者である2024 Japan AWS All Certifications Engineersとして、任期1年の活動にも取り組んでいます。
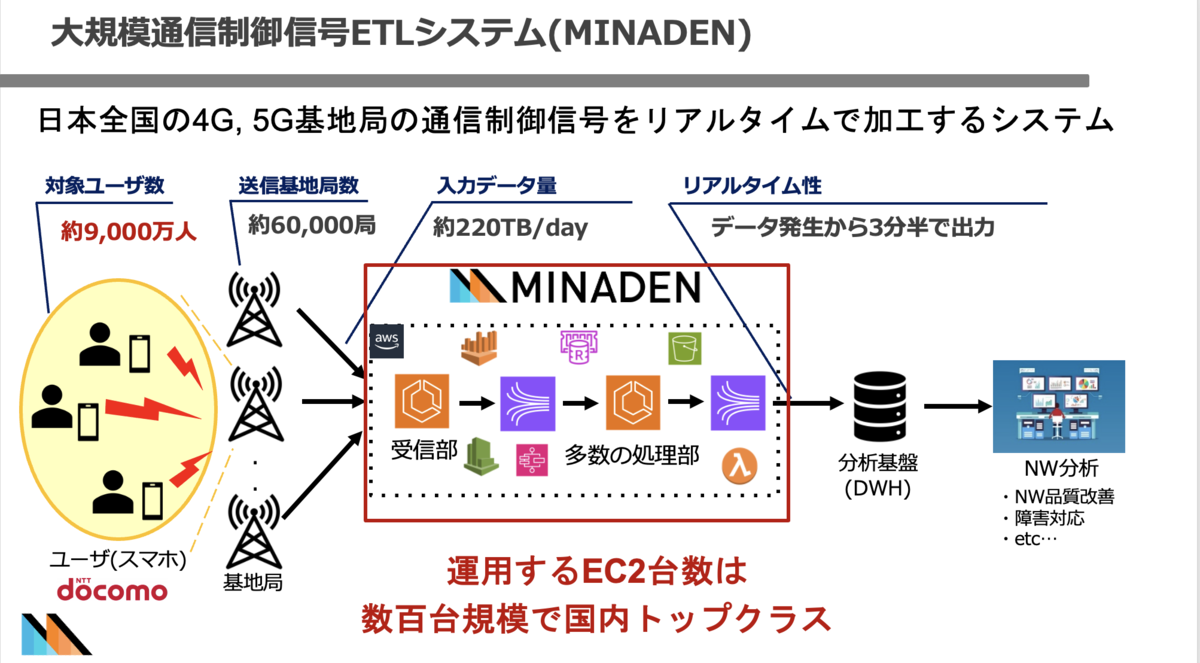
普段の業務では、1日数百TBにわたる弊社の4G、5G基地局の通信制御信信号をリアルタイムで分析可能とし、 ネットワークエリア品質向上に役立つデータへ変換するシステムの研究開発業務に携わっており、いわゆるデータエンジニア的な業務に携わっております。

- 普段の業務
- Amazon S3 Tables
- Apache Icebergとは?
- Glue Data CatalogによるApache Iceberg tableのストレージ最適化機能との違い
- Amazon SageMaker Unified Studio
- Bedrock Knowledge Basesが構造化データをサポート(Chalk Talkに参加)
- Bedrock Knowledge Basesが構造化データをサポート(利用例と考察)
- Get Started building ML models with natural language (workshop)
- AWS Jam: DevOps and modernization with Jr.Champions (番外編)
- まとめ & 今後の意気込み
普段の業務
1日数百TBにわたる弊社の4G、5G基地局の通信制御信信号をリアルタイムで分析可能とし、 ネットワークエリア品質向上に役立つデータへ変換するシステム(=MINADEN)の研究、開発、運用業務に携わっており、いわゆるデータエンジニア的な業務に携わっております。チームでの取り組みは社外勉強会でも発表しておりますので、興味のある方はご覧ください!
「社外勉強会資料」
大規模通信制御信号 ETL システムにおける 大幅なコスト削減・意識改革の取り組み
大規模な通信制御信号処理の環境下における Athena のパフォーマンス比較
Introduction of "Minaden", Which Processes 200TB of Japanese Cell Phone Base Station Data Per Day
大規模データ処理基盤における MLOps について
Amazon S3 Tables
- Apache Iceberg形式に対して最適化されたストレージ
- Redshift、Athena、EMR、Apache Sparkなどからクエリ可能 (Iceberg形式自体は、元々対応)
- 従来ストレージと比較して、最大3倍のクエリ性能と10倍のトランザクション処理が可能
- Glue, Athena等で通常S3にIcebergテーブルを作成しても上記の効果は得られない
- ガベージコレクションをサポート
- 古いスナップショット、古いスナップショットで参照されていたデータファイル(ParquetやORC、Avtoなどのファイル形式)、古いメタデータファイル等を自動で削除
- 結果的に、ディスクスペースの効率化やパフォーマンスの向上に繋がる模様

S3 Tablesの登場は、データウェアハウス(Redshift等)は不要で、S3(データレイク)に取り合えず入れて、クエリをしましょう!というAWS側のメッセージなのでしょうか?
Apache Icebergとは?
Apache Icebergとは、大規模なデータの効率的な管理とクエリ性能を向上させる設計となっているOpen Table Format(OTF)です。ファイル形式のことを指している訳ではありません。データレイクやクラウドベースのデータストレージの世界で、標準として採用される可能性が非常に高いことから、概要を理解しておくことが必要と感じ、まとめました。タイムトラベル機能、3層構造や高度なメタデータ管理によって効率的なクエリ実行が可能となっております。Icebergでは、効率的にデータを管理するために以下の図に示すように、カタログ層、メタデータ層、データ層の3層から成り立ちます。
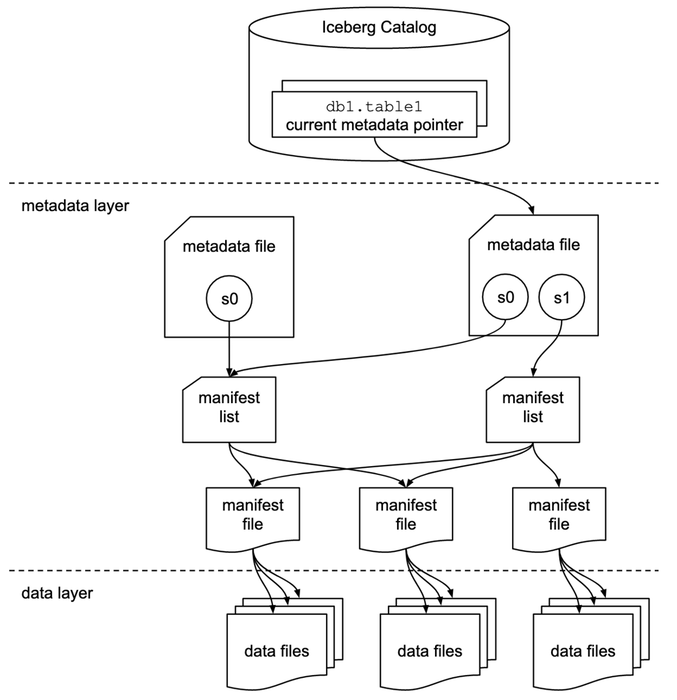
出典: Iceberg Table Spec (Spec - Apache Iceberg™)
タイムトラベル (Time Travel)
過去のデータに対する変更履歴をスナップショットとして保存し、過去の状態にアクセス可能にする機能のことを指します。 データが更新されても、過去のデータを容易に参照できるため、分析や監査に有効的です。
カタログ層
Icebergテーブルの管理に必要な情報を保持するカタログのことを指します。具体的には、テーブル名やスキーマを含む全体的なテーブル構造が管理されます。Hive MetaStore、AWS Glue Data Catalog等が該当します。AWS環境で利用する場合には、Glue Data Catalogが使いやすく運用負荷が高いためGlue Data Catalog=カタログ層の理解で問題ないかと思います。
メタデータ層
データの構造やスナップショット、ファイルの位置、スキーマやパーティション情報等のテーブルのメタデータファイルを含む層です。メタデータ層には以下の3つのファイルを含みます。
メタデータファイル (Metadata File)
- テーブル全体の情報(スナップショット、スキーマ、パーティション情報)を保持します。テーブルが更新される毎にメタデータファイルが生成され、前述の図におけるバージョン(s0, s1)として管理されます。
マニフェストファイル (Manifest File)
- 各データファイルの位置、サイズ、ファイルの属するパーティション情報、統計情報等を含みます。必要なファイルに限定してクエリを実行し、処理速度の向上に繋がります。
マニフェストリスト (Manifest List)
- マニフェストファイルを指し示すリストで、スナップショットごとに管理されます。スナップショット間のデータ管理が効率化されることに繋がります。
データ層
実データのこと、つまりファイルのことを指します。一般的には、列指向のParquet、ORCやバイナリ形式のAvroが使用されます。データは物理的にクラウドストレージであるS3やHadoop Distributed File System(HDFS)に保存します。HDFSはEMRを利用したことがある方は、ご存知かもしれませんが、S3と比較すると処理性能の向上が期待できますが、可用性の面では劣ってしまいます。S3は永続用、HDFSは一時領域用に使い分けたりもします。S3 Tablesの理解ためには、HDFSのことは忘れてしまって構いません!
Icebergが高速である理由
不要ファイルの除外
- ユーザの入力するクエリ(例えば、あるカラムの数値を見て判断)に応じてマニフェストファイルに記録されたパーティション情報や統計情報を利用して、必要なファイルだけをクエリ対象とすることが可能となります。結果的に不要なI/O操作を減らすこととなり、パフォーマンスの向上が期待できます。
スナップショットによる管理
- スナップショットごとにデータを管理するため、変更が生じた部分に対して効率的にクエリをすることが可能です。全データをフルスキャンすることなく、最新の状態を取得や変更点に対して操作を行うことが可能となります。
パーティションの自動最適化
- 隠れたパーティショニングとも呼ばれ、パーティションをユーザーに意識させずに最適化します。パーティションに基づいて効率的にデータを整理し、パフォーマンスを大幅に向上させます。RDSにもパーティションの機能はありますが、管理に手間が生じてしまう経験をしているため、このような自動最適化は嬉しい機能ですし、パフォーマンスの向上も期待できます。
コンパクション
- S3 TablesやGlueの機能を用いることによって断片化された小さなデータファイルを統合する「コンパクション」が可能になります。これにより、クエリ時のスキャンファイル数を減らし、パフォーマンスの向上が期待できます。
Glue Data CatalogによるApache Iceberg tableのストレージ最適化機能との違い
Glue Data Catalogにはデータの圧縮、スナップショット、孤立データ等の管理を担うストレージ最適化機能があります。これによってストレージコストの最適化やクエリパフォーマンスの向上が期待できるようです。これだけを読むと、S3 Tablesとの差異があまりないように感じ、しっかりと使いこなせばコスト最適化をしながら、良いパフォーマンスを発揮できるのではないかと考えております。S3 TablesではTPS(Transactions Per Second)が通常のバケットよりも高いことからも、内部的な細かい部分でIceberg用に特化された設計がなされているかもしれません。こちらについては、今後検証を進めていきたい点です。 aws.amazon.com
Amazon SageMaker Unified Studio
- EMR、Glue、Athena、Redshift、Bedrock、MSK、Kinesis、QuickSight等の機能を統合
- 例えば、ストリーミングはKinesis, 機械学習は、SageMakerで分析はRedshift, Athena, EMR等のサービスへ移動しなければならず、使用上の手間が存在
- 用途に応じた機能を1箇所で簡単に使えるようになった (統合のみ?)
- 将来的には、各種機能をマネージド化するプランがあると嬉しい(SnowflakeやDatabricks等の3rd partyツールと同等程度の柔軟な機能があると更に魅力的)

Amazon SageMaker Unified Studio
Bedrock Knowledge Basesが構造化データをサポート(Chalk Talkに参加)
自然言語の入力から、構造化データ(Redshift, SageMaker Lakehouseのみ)を読み込みSQLクエリを自動生成(NL2SQL)
デフォルト設定で上手くいかない場合は、独自のクエリ定義やカラムの説明追加が必要 (結局、設定が増えすぎないのか?)
LLMモデルベースなため、理由は不明だけど何かしらのSQLが応答される

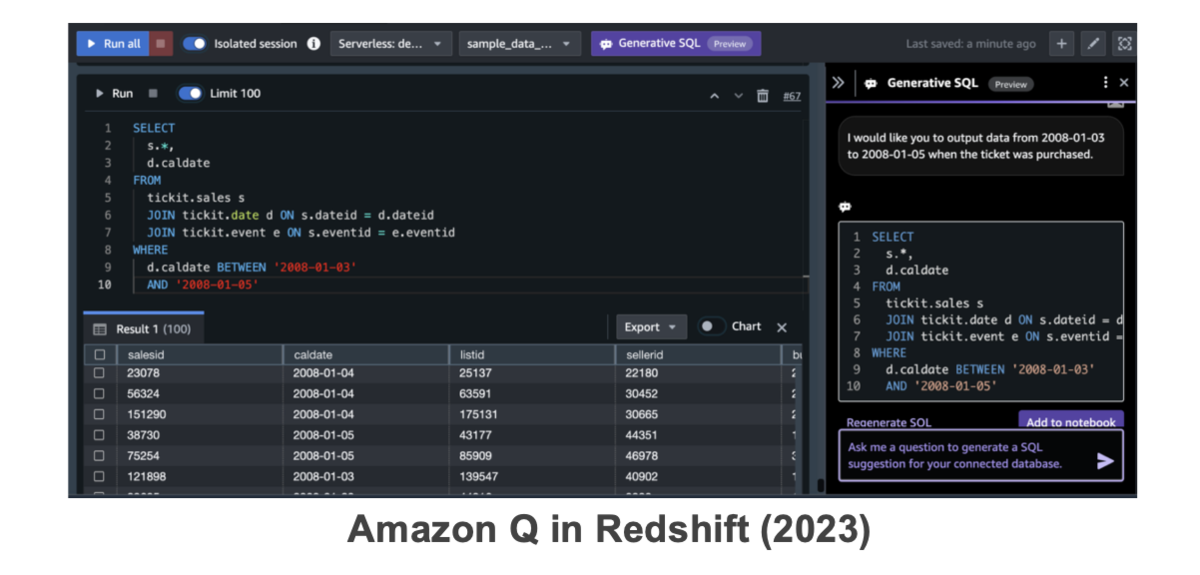
Bedrock Knowledge Basesが構造化データをサポート(利用例と考察)
2023 re:InventでRedshiftにAmazon Qを内包し、SQLクエリを自動生成する機能が展開
前者は、SQLがある程度分かる人、Bedrockの構造化データは全くSQLクエリが分からない人向けの機能である認識
全国のNW分析者からのSQL関連の質問を自動対応できる未来を目指したい
生成結果に対する評価の自動検証と結果に対するアクションを起こす仕組みの構築が課題(難)
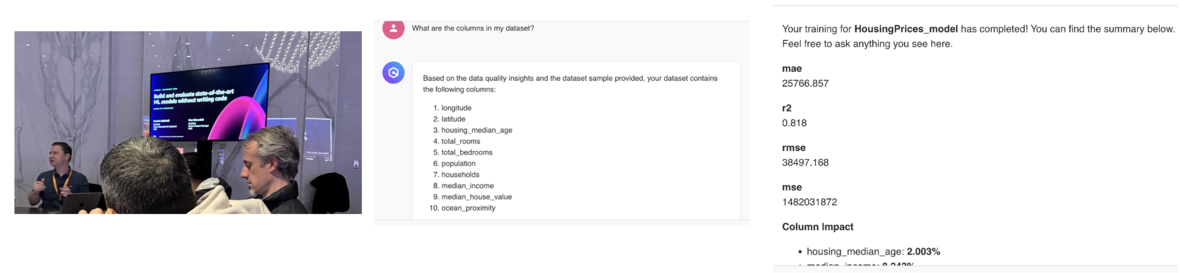
Get Started building ML models with natural language (workshop)
- SageMaker Canvas(ノーコード、AutoML)でAmazonQを用いることで自然言語でモデルの構築ができるようになる
- データセットの中身を読み取り、自然言語で指示を与えるとカラム名や各種統計値まで算出できていた(目的変数も当てていた)
- レスポンス遅い、精度悪い、使い勝手が悪く、DataRobot等の3rd partyより利点があるのか
- DataRobot(総当たりのようにモデル構築)、本機能(ML有識者に質問しながら構築)の違いがあるという理解に至る
AWS Jam: DevOps and modernization with Jr.Champions (番外編)
同じJr.Championsで同期のNTT東日本の豊岡くんと、Jamにも参加してみました!
- API GatewayとLambdaの組み合わせやECS、EKSを用いたアプリのバグを発見して解決していき、得点の高いチーム(4名で1チーム)が勝利
- 他の2名は初対面の方
- Document読んだり、デバッグすればいけると思っていたが苦戦・・・
- 他のチームの方にも聞いたが、難易度は全体的に高かった様子
- 苦戦したからこそ、更に知識を習得するモチベーションが現地で向上
- Analytics以外のサービスに関するスキルが不足していることを強く実感

まとめ & 今後の意気込み
2024年のre:InventではJr.Championsに選出されて現地で多くの知り合いの方と交流でき、楽しみながら参加することができました!イベント自体は5日間、毎日楽しかったのですが、関連するイベント(Jr.ChampionsやNTTの集まり)にも参加し、現地で刺激を受ける機会もいただけました。現状に満足することなく、チームや自組織、ドコモに技術を還元できるように頑張っていきたいと思います!
昨年のアドベントカレンダーで掲げた目標は以下でした。
AWS資格を全冠すること (2024は達成)
AWSのコミュニティ活動に積極的に参加し、視野を広げた技術的知見や繋がりを持つこと (Jr.Champions選出やビッグデータJAWSの運営に参画)
英語を円滑に話せるようになること・・・(継続勉強中で2023 re:Inventよりは少し話せた程度)
上記の結果を踏まえて、2025年までには以下を目標に頑張っていきます!
2025年もAWS資格を全冠すること
他組織に対して自身のAWSスキルを還元し、システムへの盛り込みや設計に貢献
継続的な英語の学習と英語での外部発表の機会を再び作る(2023 JAWS PANKRATIONでは英語発表)