
TL;DR
- 機械学習のモデル解釈手法SHAPを拡張した、SHAP-IQ (Interaction Quantification) が提案された
- 単一の特徴量だけでなく、複数の特徴量間の交互作用も近似して、モデルの解釈性を深めることが可能
- pythonライブラリ
shapiqで利用可能。NeurIPS2024 (Datasets and Benchmarks Track) に採択 - SHAPと同様に、ローカル・グローバル両方の解釈が得られ、可視化の各種メソッドも実装されている

はじめに
DOCOMO Innovations, Inc. (DII) の出水です。 NTTドコモのグローバルR&D拠点の一つであるDIIにて、Principal Data Scientistとして機械学習の研究開発に従事しています。
機械学習を用いた分析で、モデルの説明可能性(解釈性)にSHAPを使う方は非常に多いと思います。
SHAPでは、主に各特徴量における単一の寄与をShapley value (SV) の近似で算出し、 交互作用は2変数までの取得で、部分依存グラフ (Partial Dependence Plot) 等でのみの可視化に限ります。
これに対してSHAP-IQでは、任意の次数での特徴量の組合せも含めた寄与を、Shapley interactions (SIs) の近似で算出できるようになっています。
また、pythonライブラリのshapiqとして実装されていて、特徴量の組合せによる寄与を可視化する豊富なメソッドも用意されています。
本手法とライブラリ内容は、以下著者らによってAI・機械学習分野の最難関国際会議NeurIPS2023及びNeurIPS2024にも採択されています。
- Muschalik et al. (2024). shapiq: Shapley interactions for machine learning In. NeurIPS'2024 https://openreview.net/forum?id=knxGmi6SJi
- Fumagalli et al. (2023). SHAP-IQ: Unified Approximation of any-order Shapley Interactions In. NeurIPS’2023 https://openreview.net/forum?id=eX73tYK3RV
本記事では、SHAP-IQ概要やLightGBMへの適用例を紹介してきます。
具体例
SHAP-IQによるモデル解釈の例として、データ種類別(表形式、テキスト、画像)に見ていきましょう。
1. 表形式データ
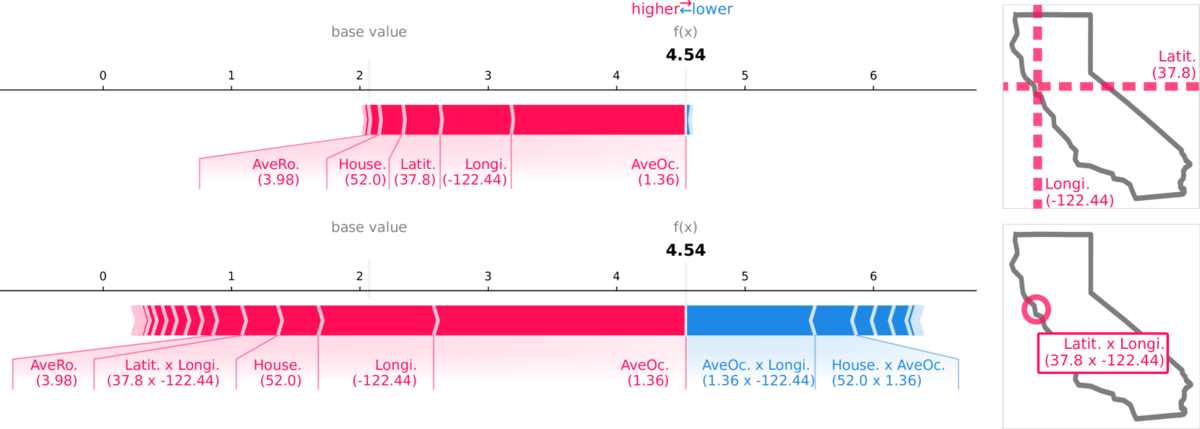
California housing dataset(カリフォルニア州の住宅価格データ)での、価格予測のSVとSIsの比較例です。
上段はSVのみの結果で、緯度Latit.と経度Longi.の両方が上位の寄与ですが、解釈としては各々独立したものです(上段右の地図イメージ)。
対して下段は2次のSIsを含めた結果で、Latit.が無くなり、緯度経度の組合せLatit. x Longi.が上位の寄与に入っています。つまり、下段右の地図イメージの通り、ピンポイントな地点における寄与として表現できています。
2. テキストデータ
映画のレビューテキストにおけるセンチメント分析で、単語の次数別のSIsについての算出・可視化の例です。
1次は単語別のポジティブ・ネガティブの寄与を示し、forgotがネガティブ (スコア: -1.30) と判断されています。対して2次のnever forgotでは強くポジティブ(スコア: +1.993) に、また2次の残りの組合せではネガティブと判断されています。このように、単語の組合せにおける自然な解釈と合う結果となっています。

3. 画像データ
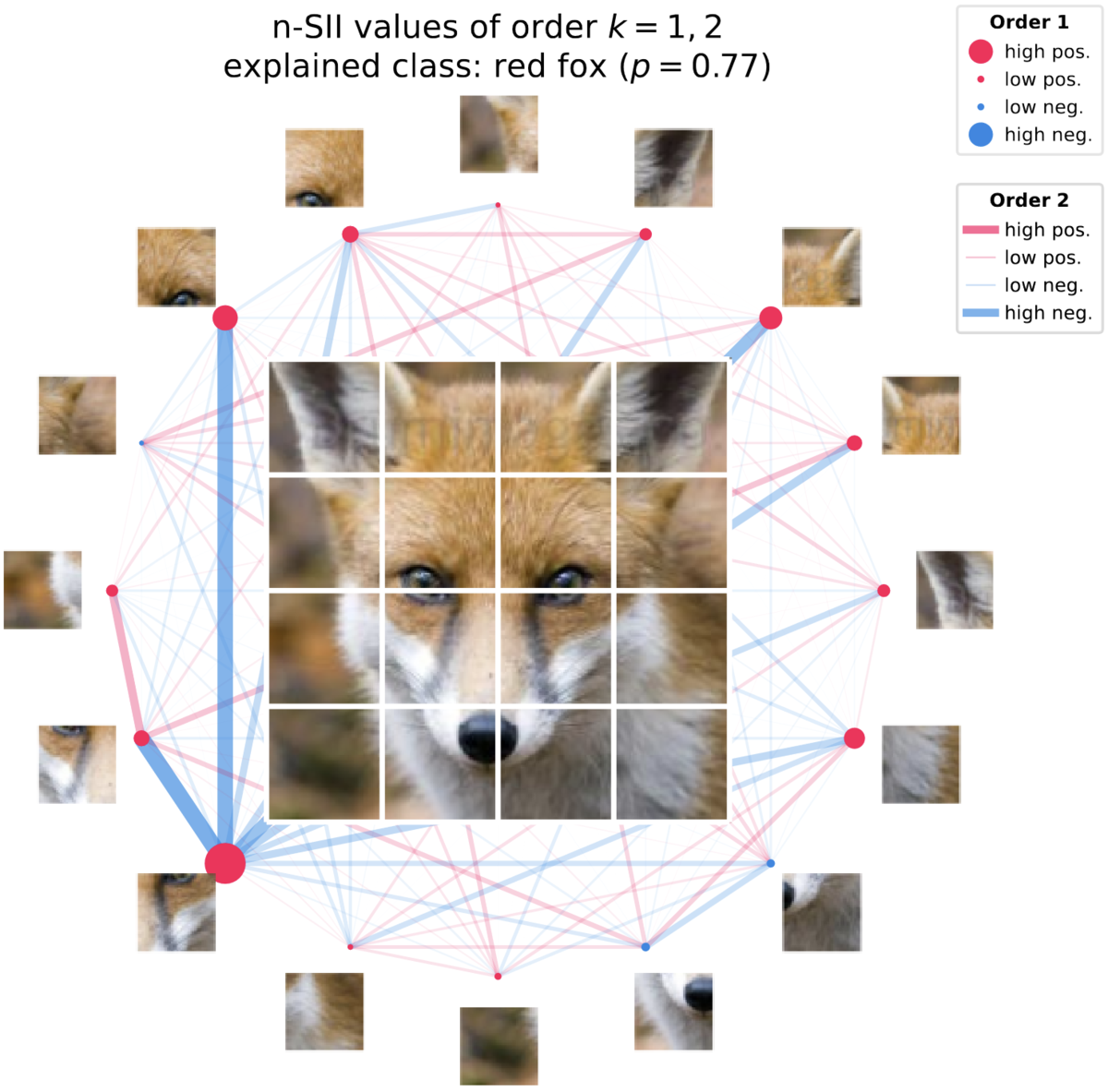
Vision Transformer (ViT) による画像分類で、予測結果 (red fox) の判断根拠の説明例です。
画像データを複数のパッチ (図では4×4) に区分し、ネットワーク図を使って判断根拠を可視化しています。 1次(パッチ単体)の寄与をノード、2次(パッチのペア)の寄与をエッジで表現しています。 つまり、
- 赤色のノードが大きいほど、そのパッチ単体で
red foxに寄与している - 赤色のエッジが太いほど、そのパッチのペアが
red foxに寄与している
という解釈になっています。
手法概要
SHAP (SHapley Additive exPlanations)
ゲーム理論(特に協力ゲーム理論)におけるShapley valueを導入し、特徴量単体の寄与(貢献度)を算出する手法です。 用いる近似方法の違いによって、Kernel SHAPやTree SHAPといったバリエーションも存在します。NeurIPS2017で採択された以降、代表的なモデル解釈手法の一つとなっています。
SHAP-IQ (SHAPley Interaction Quantification)
対してSHAP-IQでは、特徴量間の交互作用をShapley interactionsとして算出することを考えます。
このShapley interactionsの定義や近似手法は、これまで複数提案されていましたが、統一的な方法はありませんでした。 そこで、このSHAP-IQでは、複数の定義を包括するCardinal Interaction Index (CII) を対象に、その効率的な近似を可能にしたサンプリングベースの手法です。 理論的内容はNeurIPS2023論文に詳細がありますが、発表スライドをまず見ていただくの分かりやすいです。
shapiqライブラリでは、SHAP-IQによるExplainerや可視化メソッドが利用可能です。
また、Shapley value, Shapley interactions以外にも、Möbius interactions (全ての特徴量間の交互作用を考慮した場合) といったゲーム理論に基づく他の手法も使用できます。
さらにshapiqでは、これら数々のモデル解釈手法に対しての詳細なベンチマークも用意しています。
ベンチマークは、機械学習ドメインにおける11個の観点 (Local explanation, Data valuation, Uncertainty explanation等) に基づいています。
各ベンチマークでの特徴量(プレイヤー)数や機械学習モデルの設定の違いを含めて、全部で100個のベンチマーク問題があります。
このことから、NeurIPS2024論文はDatasets and Benchmarks Trackに入っていると考えられます。

LightGBMへのSHAP-IQ適用例
分類タスクにおけるLightGBMの判断根拠を、SHAP-IQを用いて算出・可視化するコードを紹介していきます。
利用ライブラリとバージョンは次の通りです。
import numpy as np import pandas as pd import lightgbm as lgb from sklearn.model_selection import train_test_split import shapiq {"shapiq": shapiq.__version__, "lightgbm": lgb.__version__} # {'shapiq': '1.1.1', 'lightgbm': '4.5.0'}
利用データはAdult census incomeで、二値の分類タスクとしてLightGBMにより学習します。
# Adult censusデータのロード X, y = shapiq.load_adult_census() # データのスプリット X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.25, random_state=42 ) # 特徴量の数、カラム名を取得 n_features = X_train.shape[1] col_features = X_train.columns # LightGBMのハイパーパラメータ設定と学習実行 lgb_params = { 'objective':'binary', 'metric':'binary_logloss', 'seed':42, 'max_depth': n_features, } model = lgb.train( lgb_params, lgb.Dataset(X_train, y_train), num_boost_round=100, )
以降、特徴量間の交互作用も含めたモデル解釈を、SHAP-IQを使って確認してきます。
Shapley interactionsの算出
SHAP-IQはSHAPと同様に、機械学習モデルに依存しない (model-agnostic) 手法ですが、ツリーベースのモデルに対してShapley interactions (SIs)を効率的に算出できるTreeSHAP-IQが提案されいて、shapiq.TreeExplainerで実行可能です。
学習済みのLightGBMモデルmodelでの、あるサンプルの予測結果に対するSIs (1次から3次まで) を算出してみましょう。
# TreeExplainerを用い、1次から3次までのSIを対象に設定 explainer = shapiq.TreeExplainer(model=model, index="k-SII", min_order=1, max_order=3) # ローカル (特定の1サンプル) のSIsを計算 x = X_test.iloc[5] interaction_values = explainer.explain(x) # 上位10個までの寄与を表示 print(interaction_values.get_top_k(10, as_interaction_values=True))
結果:
InteractionValues(
index=k-SII, max_order=3, min_order=0, estimated=False, estimation_budget=None,
n_players=14, baseline_value=-2.1806992555365743,
Top 10 interactions:
(2,): 2.284707905252978 # index 2 の特徴量単体の寄与
(0,): 0.9068227710223482
(9,): 0.7575161755378431
(7,): 0.7234984008942696
(2, 7): 0.6730851357924119 # index 2と7の特徴量の交互作用の寄与
(3,): 0.4985956402546689
(2, 9): 0.4961198065997948 # index 2と9の特徴量の交互作用の寄与
(13,): -0.4078871841238996
(8,): -0.6112266712386575
(): -2.1806992555365743
)
Shapley interactionsの可視化
TreeSHAP-IQで算出した交互作用も含めたSIsを可視化する、各種のメソッドを紹介します。
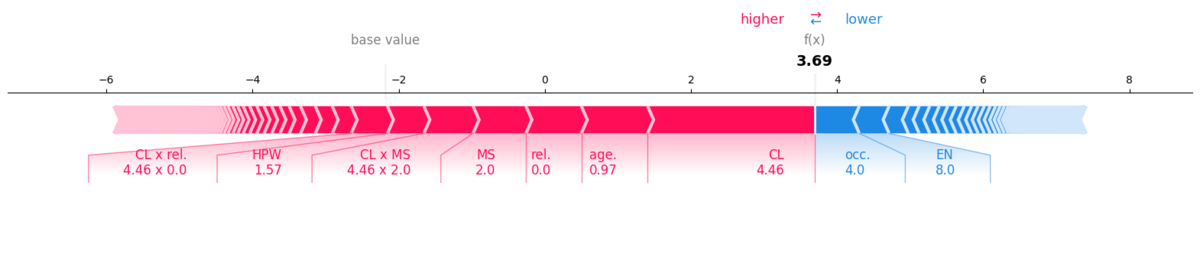
Force Plot
SHAPライクな描画が可能で、以下図でも交互作用のCL x MSやCL x rel.を含んでいることが分かります。
interaction_values.plot_force(
feature_names=col_features, feature_values=x, contribution_threshold=0.03
)
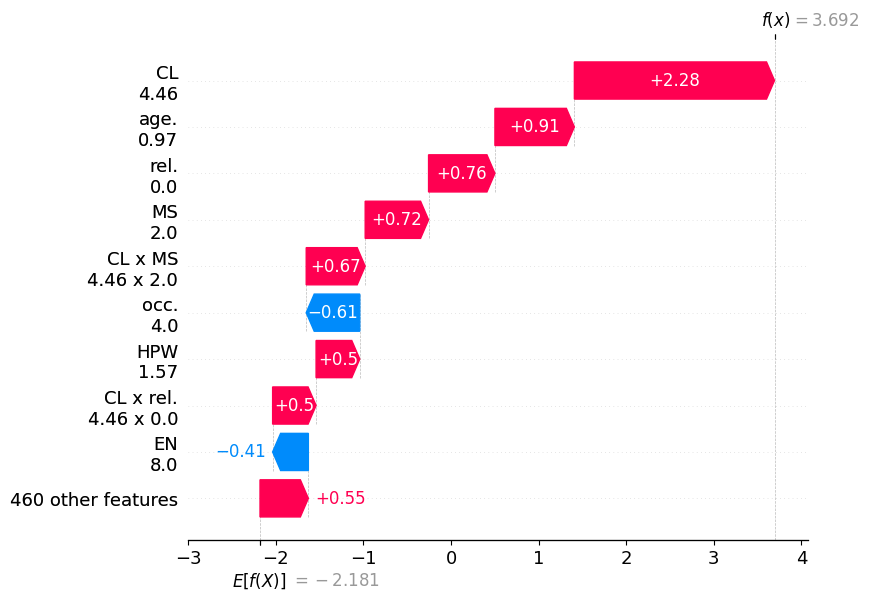
Waterfall Plot
同様に、特徴量や交互作用をY軸に配置したwaterfall plotも描画可能です。
interaction_values.plot_waterfall(
feature_names=col_features, feature_values=x
)
Stacked Bar Plot
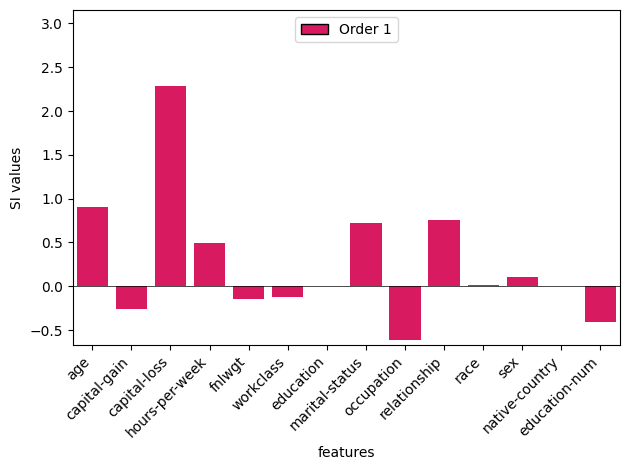
stacked bar plotでは次数を指定して描画することが可能です。まず、1次のみ (通常のSV) の描画です。
# single features (1-order) _ = shapiq.stacked_bar_plot( interaction_values=interaction_values.get_n_order(1), feature_names=col_features, )
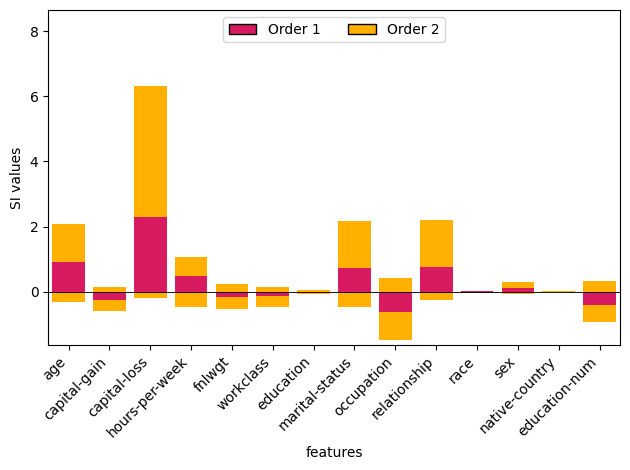
次に、2次の交互作用まで含めて、特徴量別に寄与を積み上げた描画です。例えば、1次の寄与 (赤色) は少ないが、2次での交互作用 (黄色) では大きな寄与がある特徴量を発見できる可能性があります(その意味で、個人的にこの図はとても重要かと思いました)。
# interactions (2-order) _ = shapiq.stacked_bar_plot( interaction_values=interaction_values.get_n_order(2, min_order=1), feature_names=col_features, )
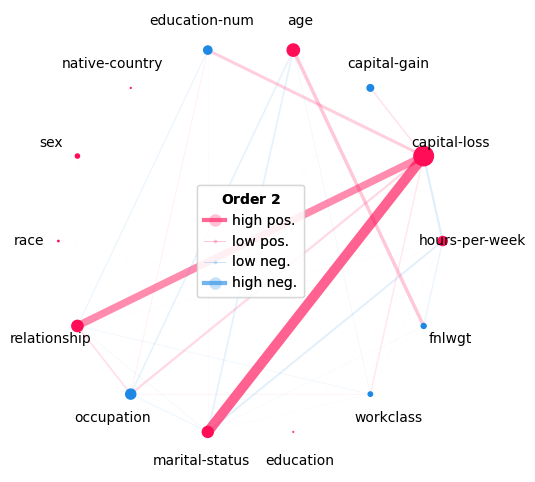
Network Plot
画像データの例でも挙げていた、network plotの例です。ノードの色・大きさで特徴量単体の寄与の方向と強さを、エッジの色・太さで交互作用の方向と強さを表現しています。
shapiq.network_plot(
first_order_values=interaction_values.get_n_order_values(1),
second_order_values=interaction_values.get_n_order_values(2),
feature_names=col_features,
)
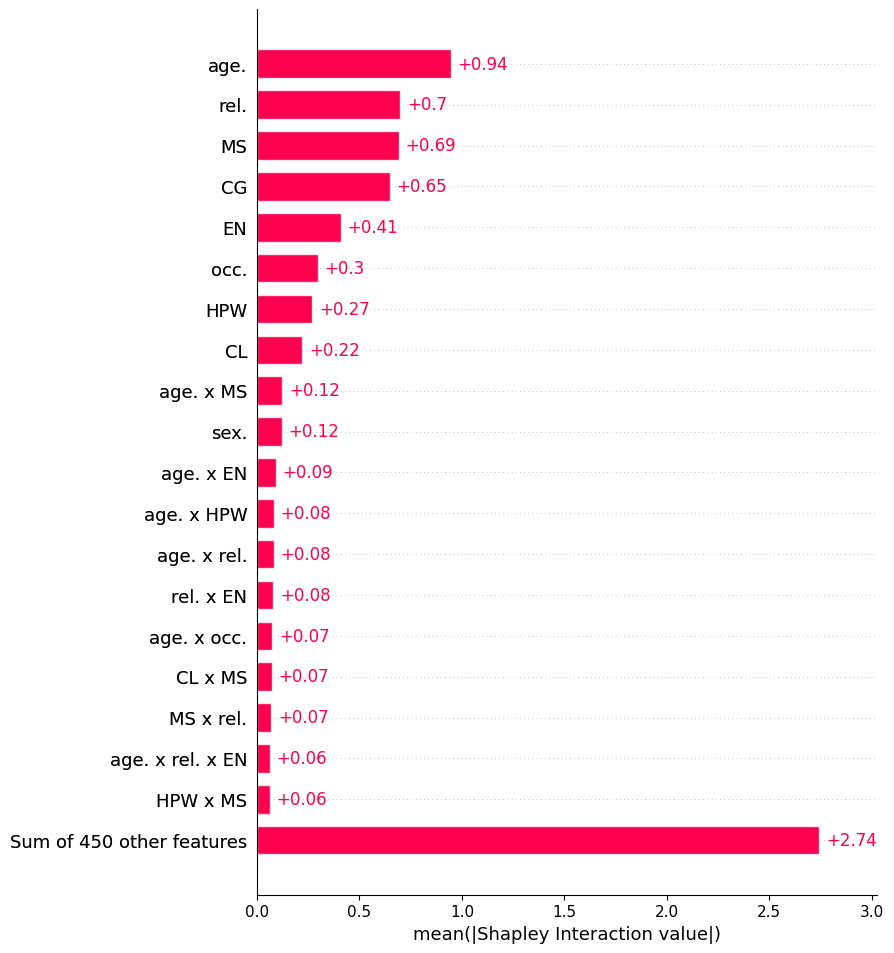
Global Feature (Interaction) Importance
SHAP-IQでもSHAPと同様に、ローカル(それぞれのサンプル)だけでなく、グローバル(サンプルの集合)の解釈へもアクセスできます。
# global feature & interaction importance list_of_interaction_values = explainer.explain_X(X_test.iloc[:50,].values) shapiq.plot.bar_plot(list_of_interaction_values, feature_names=col_features, max_display=20)
さいごに
特徴量の組合せでの交互作用を算出・可視化できるSHAP-IQは、機械学習モデルの説明可能性(解釈性)を更に深める上で興味深い手法だと感じました。 ご興味がある方は、ぜひ論文等をチェックしてください。
また、機械学習モデルの説明可能性(解釈性)についての原先生、TJOさんの資料も大変参考になりますので、ご紹介させていただきます。
参考文献
- Fumagalli et al. (2023). SHAP-IQ: Unified Approximation of any-order Shapley Interactions. In NeurIPS’2023 https://openreview.net/forum?id=eX73tYK3RV
- Muschalik et al. (2024). shapiq: Shapley interactions for machine learning. In NeurIPS'2024 https://openreview.net/forum?id=knxGmi6SJi
- Fumagalli et al. (2024). KernelSHAP-IQ: Weighted Least Square Optimization for Shapley Interactions. In ICML’2024 https://proceedings.mlr.press/v235/fumagalli24a.html
- Muschalik et al. (2024). Beyond TreeSHAP: Efficient Computation of Any-Order Shapley Interactions for Tree Ensembles. In AAAI’2024. https://ojs.aaai.org/index.php/AAAI/article/view/29352
- Lundberg et al. (2017). A unified approach to interpreting model predictions. In NeurIPS'2017 https://arxiv.org/pdf/1705.07874
- https://shapiq.readthedocs.io/en/latest/index.html
DOCOMO Innovations, Inc.の紹介
https://nttdocomo-developers.jp/entry/2024/12/22/090000_4
DOCOMO Innovations, Inc. はシリコンバレーを拠点に、AI/NW/Clouldを中心とした組織に加えて、オープンイノベーション、デバイス、ビジネス連携といった多様な組織で構成されています。ここでの地の利を活かした技術開発・ビジネス開発力をアセットに、NTTドコモやNTTグループ、国内外企業と連携して事業拡大に取り組んでいます。
ご興味ある方、シリコンバレーにお越しの方は、ぜひお気軽にご連絡ください!