
NTTドコモ サービスイノベーション部
ビッグデータ担当 2年目社員の小澤です.
学生時代は, 機械学習分野の研究に取り組んでいましたがドコモでは, 膨大な通信に関するデータの加工を担うデータエンジニア的な業務に携わっております. 昨年は, 自身の業務に関連するロードバランサ関連技術やOSSについてまとめました.(https://qiita.com/dcm_ozawa/items/e09ab30b38aae5aa72ed)
普段の業務では, アプリケーション寄りの開発の機会が少ないことや自信で取り組んでみたいこととして, 「東京ディズニーシー」に関する分析を行ってみたいと思います.
東京ディズニーシーへ行く際に気になること
社会人になってから, 息抜きとして東京ディズニーランド / ディズニーシーへ行く機会が増えました. ちなみに弊社は, 「東京ディズニーランド」「東京ディズニーシー」のオフィシャルスポンサーです. (https://www.docomo.ne.jp/corporate/sponsorship/tdr/)
皆さんは, 東京ディズニーリゾートへ行く際に気にされるポイントは何でしょうか?
各季節のイベント
観たいパレード
人が少なくゆっくりしたい
とにかくアトラクションを楽しむ
限定グッズの入手
気にされるポイントは, 人それぞれだと思いますが, 私はアトラクションを楽しみたいので, アトラクションの待ち時間が少ない, つまり入園者数が少ない日を狙って有給を取得して行くことが多いです. そんな中, 入園者数についての分析をしてくれると, たいへん有用であると感じるようになりました. 私は, この分析結果を利用してセンター・オブ・ジ・アースとタワー・オブ・テラーにたくさん乗りたいです.
取り組み概要
東京ディズニーシーのアトラクション別の混雑具合の分析してみます. 私自身も東京ディズニーリゾートへ行く際には, ある程度の混雑を予測して日程を選定します. そして, 大体は当たります. 予測する際に特に確認している項目は, 過去の混雑実績です. 一方で, ディズニー公式サイトや民間のサイトでは個々の日程の混雑状況は確認可能であるものの, 指定期間全体をグラフ等で表示してくれるようなサイトは見つかりませんでした. この状態では, 過去の混雑実績の分析に手間が掛かり過ぎてしまいます. また, 分析に必要なデータの収集も必要です. そこで, 今回, Webスクレイピングを用いてアトラクション別の混雑状況の分析を行うこととします.
東京ディズニーシーの混雑度データの取得
東京ディズニーシーの混雑分析をするにあたって, 以下のWebサイトを使用させていただきました. (https://urtrip.jp/tds-past-info/?rm=20221205#page_top)
こちらのサイトには, 過去のアトラクション別の待ち時間のデータが, 保持されていますのでPythonによるWebスクレイピングを用いてデータを収集し, ファイル化することで分析可能な状態にしました. 今回, 分析に必要な情報は以下のような人気アトラクションの情報です. 期間は2022年5月から2022年12月13日分を収集して, csvファイル化します. 2022年の5月からにした理由ですが, これより以前は新型コロナウイルス感染症による入園者制限に伴いスタンバイパスという特殊な運用をしており, 通常のアトラクションの混雑傾向とは大きく異なるためです.
必要情報は, 全てテーブルに格納されていることが確認できます.
以下のように, アトラクション名は, thから始まるクラスを指定して, 要素から取得できました.
<tr class="t_cool_h"> <th class="t_cool_h_top t_plan date_width t_date">時間</th> <th class="t_h t_h_0"><nobr>ソアリン</nobr></th><th class="t_h t_h_1"><nobr>トイ・<br> ストーリ<br> ・マニア</nobr></th><th class="t_h t_h_2"><nobr>タワー・<br> オブ・<br> テラー</nobr></th><th class="t_h t_h_0"><nobr>センター<br> ・オブ・<br> ジアース</nobr></th><th class="t_h t_h_1"><nobr>インディ<br> ジョー<br> ンズ</nobr></th><th class="t_h t_h_2"><nobr>レイジング<br> スピリッツ</nobr></th><th class="t_h t_h_0"><nobr>マジック<br> ランプ<br> シアター</nobr></th><th class="t_h t_h_1"><nobr>タートル<br> ・トーク</nobr></th> </tr>
アトラクション毎の15分毎の待ち時間についても, thタグのdata_lineクラス毎に要素を取得することで対応可能でした.
<tr class="t_cool_b date_width"><th class="date_line">09:00</th><td class="level_5_1"><nobr>150</nobr></td><td class="level_5_1"><nobr>110</nobr></td><td class="level_5_1"><nobr>100</nobr></td><td class="level_0"><nobr>-</nobr></td><td class="level_1_1"><nobr>5</nobr></td><td class="level_1_1"><nobr>25</nobr></td><td class="level_0"><nobr>-</nobr></td><td class="level_1_1"><nobr>25</nobr></td></tr><tr class="t_cool_b date_width"><th class="date_line">
データ取得のために, 実装したPythonスクリプトは以下になります. global変数を用いている等, イケていない部分も多いのですが, 共有します・・・
import csv import pandas as pd import requests from bs4 import BeautifulSoup from bs4.element import NavigableString, Tag import re import datetime import time import jpholiday df = pd.DataFrame() cols = [] #最初のループでしか, 機能させない. カラム定義 def define_dataframe_colms(tables): global cols check_columns = [] for tr in tables: if type(tr) is not NavigableString: for factor in tr: if type(factor) is not NavigableString: check_columns = factor.find_all('th', attrs={'class': re.compile(r'^t_.*$') }) #カラム情報 for check_column in check_columns: cols.append(check_column.get_text()) if len(check_columns) > 0 : df = pd.DataFrame(columns=cols) #アトラクション別-待ち時間の追加 def add_attraction_timedata(attraction_time_datas, date): global df #global変数排除すべき tmp_list = [] tmp_df = pd.DataFrame() print(attraction_time_datas) for attraction_time_data in attraction_time_datas: if (attraction_time_data.get_text()) != "時間": tmp_list.append(attraction_time_data.get_text()) if len(tmp_list) > 0 : tmp_df = pd.DataFrame(tmp_list).T tmp_df.columns = cols #tmp_dfに日毎の処理追加. 日付 + 時刻 date = datetime.datetime.strptime(str(date), '%Y%m%d') date = date.strftime('%Y-%m-%d') tmp_df['時間'] = date + " " + tmp_df["時間"] df = pd.concat([df, tmp_df]) #テーブルをparseし, 必要情報の取得 def parse_tables(tables, date): for tr in tables: if type(tr) is not NavigableString: for factor in tr: if type(factor) is not NavigableString: attraction_time_datas = factor.find_all(["th", "td"], attrs={'class': re.compile(r'^(?!t_).*$')}) add_attraction_timedata(attraction_time_datas, date) def main(): global df #日付は月ごと指定 initial_value = 20220501 cnt = initial_value for date in range (initial_value, 20220531): urlName = "https://urtrip.jp/tds-past-info/?rm=" + str(date) + "#page_top" time.sleep(0.1) #サーバ処理負荷軽減のため, 各アクセス0.1秒は空ける url = requests.get(urlName) soup = BeautifulSoup(url.content, "html.parser") try: tables = soup.findAll("table", "t_cool")[1] if date == initial_value: define_dataframe_colms(tables) parse_tables(tables, date) except: pass print("------------Finish!!-------------------") # datetimeへ変換 df['時間'] = pd.to_datetime(df["時間"]) # 月曜日=0, 日曜日=6 df['曜日_数値'] = df["時間"].dt.weekday df['曜日'] = df["時間"].dt.day_name() #休日判定 df['休日'] = df.時間.map(jpholiday.is_holiday) #運休 / 案内終了は0分とする for df_col in cols: if df_col != "時間": df.loc[(df[df_col] == '案内終了') | (df[df_col] =='-') | (df[df_col] =='一時運休') | (df[df_col] == '計画運休'), [df_col]] = 0 df[df_col]= df[df_col].astype('int') print(df) print(df.dtypes) df.to_csv('202205_DisneySea.csv') if __name__ == "__main__": main()
※Webサイトのスクレイピングを実施する際には, スクレイピング先のサイト規約をご確認いただくとともに, 相手サーバに負荷をかけないようご注意ください.
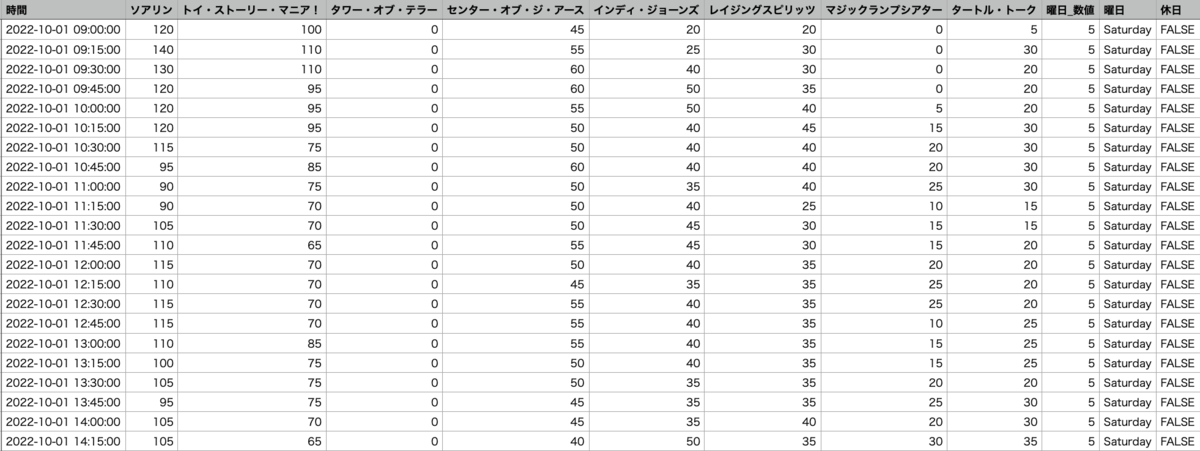
csvファイル化した中身は以下の通りです. (一部抜粋)
日付, 時間帯別のアトラクション毎の待ち時間, 曜日, 休日判定項目を取り入れました. アトラクションの混雑状況は自身の経験上, これらの項目が大きく関係するのではないかという仮説を立てて, 取り入れました.
休日か否かの判定方法ですが, jpholidayというライブラリ(https://pypi.org/project/jpholiday/)を利用しました.
アトラクション情報を保持しているdataframeに対して, 以下のように処理を加えるだけで判定可能です.
df['休日'] = df.時間.map(jpholiday.is_holiday)
アトラクションの待ち時間ですが, 運休, 案内終了である場合は0分として加工しております.
アトラクション別-混雑状況の分析 (対象期間)
前述の通りスクレイピングによって得られたデータを用いて, データの加工まで行いました. 期間は2022年5月から2022年12月13日分になります. 平日, 土日, 休日に分割してアトラクション別の平均待ち時間を算出し, 可視化しました. マジックランプシアターについては, 待ち時間が30分未満であることが大半で分析の必要がないと判断したため, 除外しました. また, アトラクションには突発的な運休が生じることがあり, その際の待ち時間は0分として設定しております. 案内終了時間については, 各日でバラバラであるため, こちらについても待ち時間を0分として設定しております
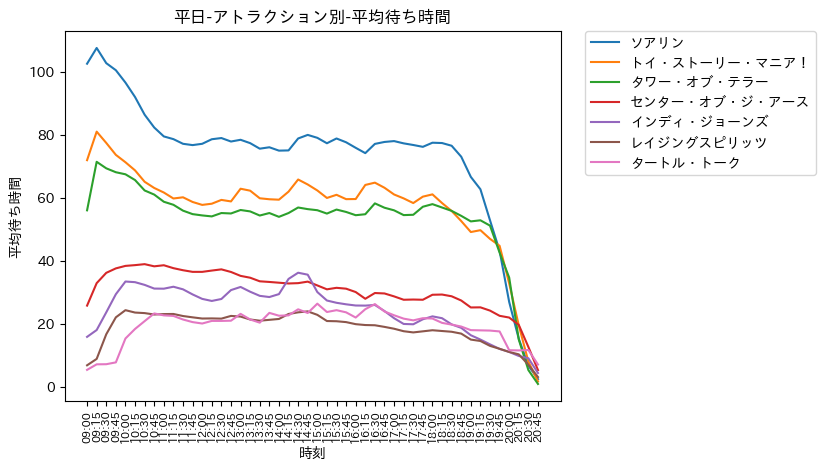
- ソアリン, トイ・ストーリー・マニア!, タワー・オブ・テラー (超人気アトラクション)
- 平日にも関わらず, 混雑している
- 営業開始時刻直後が最も混雑
- 超人気アトラクションであるため, 早く乗りたいという気持ちが働くのでしょうか ?
- 12:00のお昼にかけて, 徐々に落ち着き, 定常的になり, 営業終了時刻に近づくと更に落ち着く
- 12:00以降に乗るか, 営業終了時刻間際に乗ると待ち時間が短い可能性が高い. (実際は19:00-20:00. それ以降は案内終了の可能性が高い. )
- 今回案内終了は待ち時間を0分として設定しており, 案内終了でない場合の待ち時間(0分でない場合)を用いて平均値を算出している
- 閉園時刻直前に案内終了でない場合は, 待ち時間がかなり短い可能性が高い
- センター・オブ・ジ・アース, インディ・ジョーンズ, レイジングスピリッツ
- 営業開始時刻直後, 閉業終了時刻直前が最も空いている
- 上記を除き, 定常的な待ち時間
- 開園直後は, 特に人気のあるアトラクションへの一極集中となり, 想定的に空くのではないか ?
- 効率良く, アトラクションに乗るためには開園直後に, これら2つのアトラクションに乗るのが良さそう
- 超人気アトラクションは, 混雑ピーク後の昼以降に乗るのが良さそう
- タートル・トーク
- どの時間帯も, 定常的に同じような待ち時間
- 混雑の観点では, 好きな時間帯に乗れば良いと思います
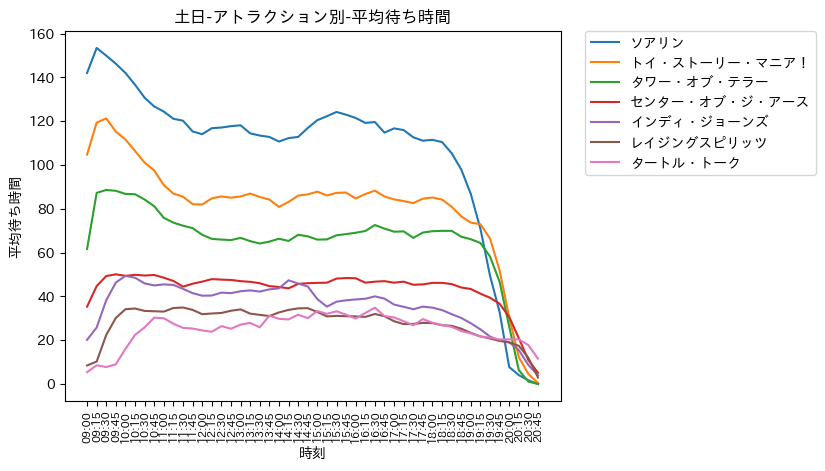
- ソアリン, トイ・ストーリー・マニア!, タワー・オブ・テラー (超人気アトラクション)
- 平日と同様の傾向
- 平日よりも混雑具合は激しい
- センター・オブ・ジ・アース, インディ・ジョーンズ, レイジングスピリッツ
- 平日と同様の傾向
- 平日よりも若干であるが, 混雑
- タートル・トーク
- 平日と同様の傾向
- 平日よりも若干であるが, 混雑
- どの時間帯も, 定常的に同じような待ち時間
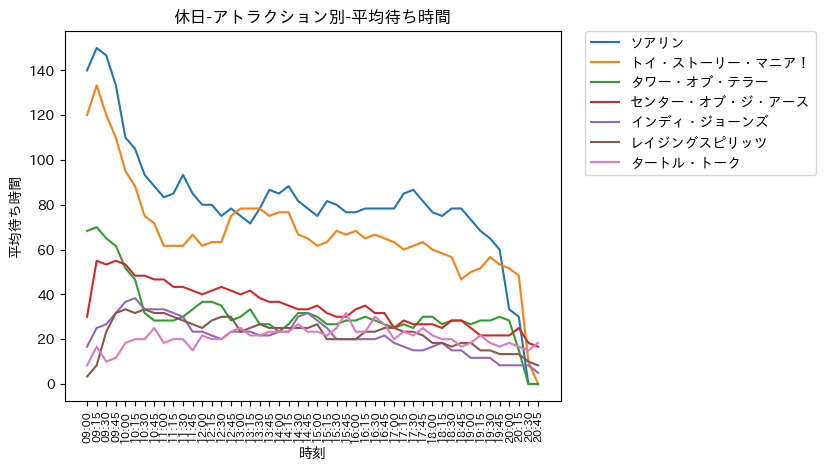
- ソアリン, トイ・ストーリー・マニア!, タワー・オブ・テラー (超人気アトラクション)
- 平日, 土日と同様の傾向
- 土日よりも混雑具合は激しく, 特に開園直後は凄まじい
- 開園直後から12:00のお昼にかけて混雑は落ち着く
- 12:00-13:00にかけて, 再び混雑してくる. お昼ご飯を済ませたゲストが集中するのでしょうか ?
- センター・オブ・ジ・アース, インディ・ジョーンズ, レイジングスピリッツ
- 平日, 土日と同様の傾向
- 開園直後に並ぶと, すぐに乗れそう +センター・オブ・ジ・アースは, 時間が経過するにつれて混雑が緩和されている傾向
- タートル・トーク
- 開園直後が最も混雑
- 開園直後以外は, 定常的な待ち時間
アトラクション別-混雑状況の分析 (旅行割前後)
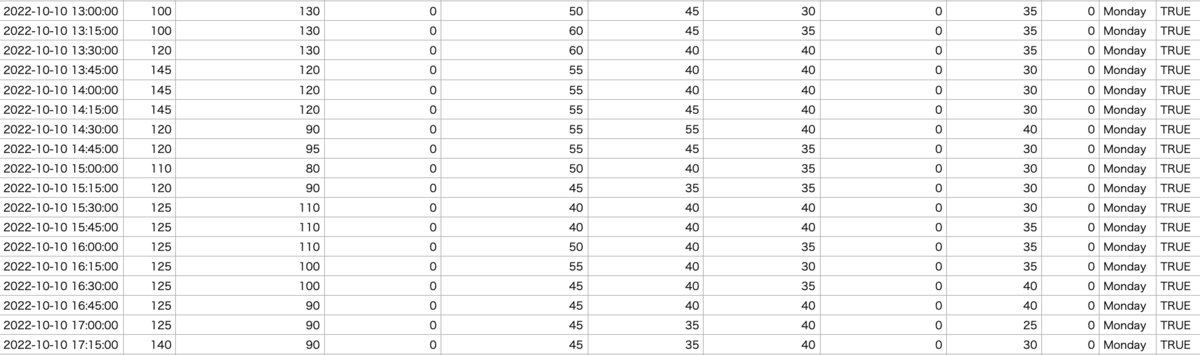
今までは, 対象期間におけるアトラクションの混雑状況を可視化しました. 分析結果と最近の混雑状況を比較すると, 分析結果の平日は空いていますが, 最近の平日は混雑している, 分析結果の土日よりも最近の土日の方が更に混雑している等の違いが確認できました. 2022年10月11日より政府による全国旅行支援(旅行割), イベント割が影響している可能性が高いと考えられます. 従って, 旅行割前を2022/5/1〜2022/10/10, 旅行割後を2022/10/11〜2022/12/13として, 旅行割前後の混雑状況の可視化も行いました.
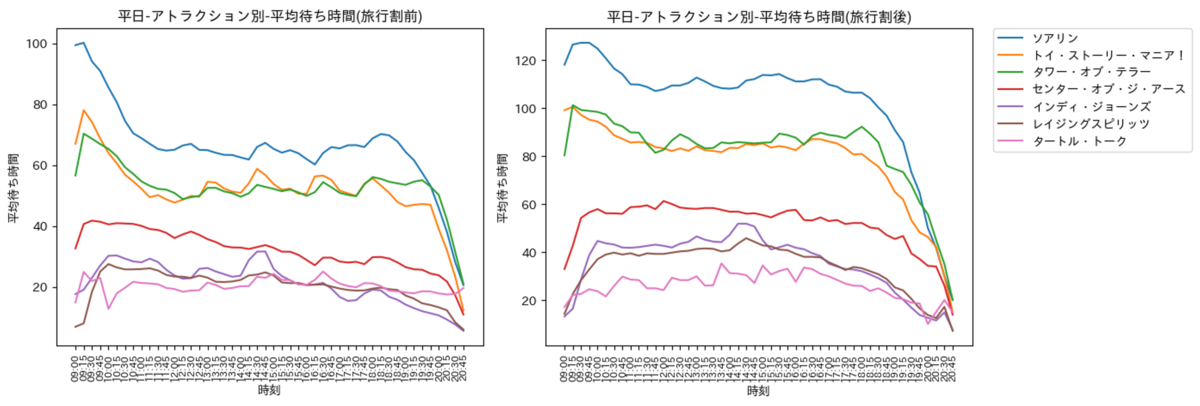
平日
平日の可視化結果は以下の通りです. 傾向は旅行割前後を区別しなかった際と同様であるものの, 旅行割前後で明確な差が生じておりますね. 旅行割前であれば, 時間帯を上手く選択することで待ち時間を短くすることができます. 一方で旅行割期間では, 平日にも関わらず混雑しており, アトラクションの待ち時間が長くなってしまいます.
- 2回のピーク時間(ソアリン, トイ・ストーリー・マニア!, タワー・オブ・テラー)
- 開園15〜30分後がピーク
- 12:00のお昼にかけて徐々に落ち着く (乗車するチャンス!!)
- 旅行割前は, 14:00-15:00に再び混雑してくる. (お昼ご飯から戻ったゲストの影響か?)
- 旅行割後は, 開園直後の混雑ピークを過ぎると混雑具合は横ばい (パーク内混雑のため, お昼を食べれずアトラクションに乗る ?)
- 混雑が少ないアトラクション
- 前述の3つのアトラクションは, どの時間帯に乗ってもあまり待ち時間は変わらず, 待ち時間も短め
- 混雑の穴場
- どのアトラクションも, 閉園直前は空いている
- インディ・ジョーンズ, レイジングスピリッツ,センター・オブ・ジ・アースは開園直後も空いている
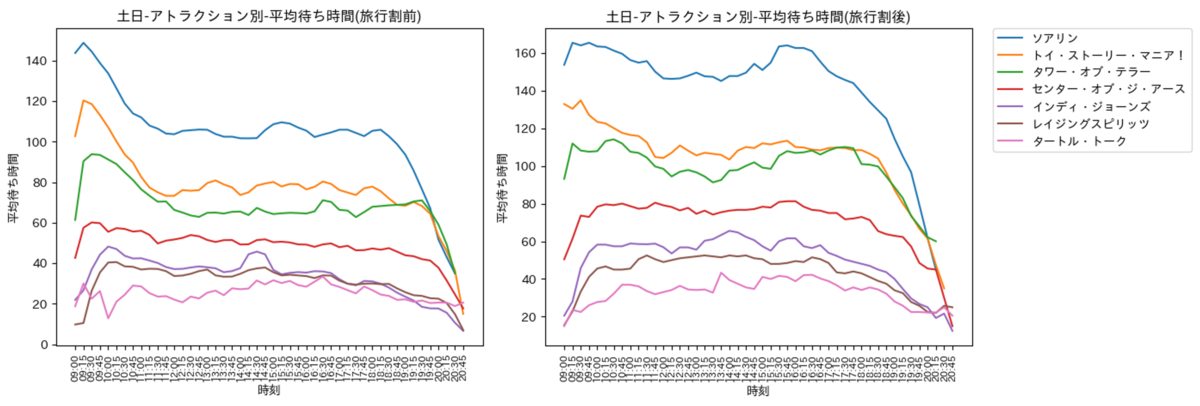
土日
土日の可視化結果は以下の通りです. 傾向は旅行割前後を区別しなかった際と同様であるものの, 平日と同様に旅行割前後で明確な差が生じておりますね.旅行割後の混雑は激しいものの, 旅行割前でも混雑しており, アトラクションをたくさん乗りたい方は, 土日ではなく平日に行くことをおすすめします. また, 平日と同様にアトラクション毎に時間帯に応じた特徴が確認できたため, これを有効的に活かすと, 待ち時間を減らして乗車できるかもしれません.
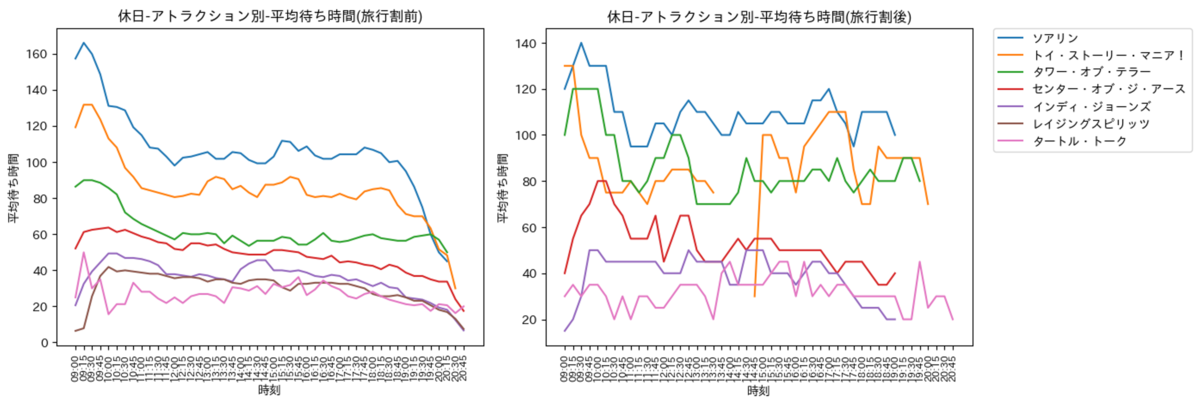
休日
休日の可視化結果は以下の通りです. 傾向は旅行割前後を区別しなかった際と同様でした. 旅行割後の休日は, データ数が少なく一部で欠損値(休止等で平均時間の算出が不可)が生じており, あまり参考にならない可能性があるものの, 旅行割前より混雑していることが確認できます. 一方で, 土日同様に旅行割前でも混雑しており, アトラクションをたくさん乗りたい方は, 平日に行くことをおすすめします. また, 平日, 土日と同様にアトラクション毎に時間帯に応じた特徴が確認できたため, これを有効的に活かすと, 待ち時間を減らして乗車できるかもしれません.
まとめ
本記事では, 東京ディズニーシーにおける人気アトラクションの混雑状況を可視化し, 分析を行いました. 既存のWebサイトでは, 確認できなかったアトラクション別の混雑推移の可視化を実現し, アトラクションを楽しみたい方への来園日の選定に役に立てられたらと思います. アトラクションの混雑傾向として, ソアリン, トイ・ストーリー・マニア!, タワー・オブ・テラーは特に人気があり, 開園直後がピークであり, その後は落ち着くものの, 定常的に混雑していることが確認できました. それ以外のアトラクションは, 開園直後 / 閉園直前が最も空いているものの, それ以外の時間帯では, それなりに待つことになります. 驚きだったのはセンター・オブ・ジ・アースの平均待ち時間が想像よりも短いことでした. 全てのアトラクションにおいて, 閉園直前はかなり空いているので, お気に入りのアトラクションや乗り過ごしたアトラクションは, この時間に乗ると待ち時間が短いのではないでしょうか? 本記事では, 分析に留めましたが, アトラクション間の相関, 天気, SNSへの投稿等のデータも取り入れて分析し, アトラクション別の混雑予測モデルの開発にも取り組んでみたいと考えております. 来園者数のデータが存在すると嬉しいのですが・・・混雑予測モデルにより, 事前に混雑具合を考慮して来園日を選択できるようになれば, 私も嬉しいですし, よりゲストの満足度を高めることができるのではないかと考えております.