
はじめに
こんにちは。NTTドコモ サービスデザイン部 @dcm_koshikawa です。 スクラム開発でプロダクトオーナーを担当しており、サービスデザイン部にJoinしてから2年半が経ちます。
サービスデザイン部では、各種ドコモサービスを動かす基盤を提供しており、基盤設計、構築、運用をしています。
代表的なサービス
- d menu:https://smt.docomo.ne.jp/
- docomo Online shop:https://onlineshop.smt.docomo.ne.jp/
各種WebサービスはAWS上で構築しています。 サービスデザイン部ではQCD向上のため、AWSで提供されているサービスを積極的に活用し、各種作業の自動化やリリースのパイプライン化を進めています。
本記事では、AWSサービスであるCloudWatch+Lambda+SQSと、監視ツールであるZabbixを組み合わせた、アラート時の自動復旧対応についてご紹介します。
課題 - 改善したいこと
提供中のWebサービス基盤の一つに、大量のコンテンツ(記事)を抱えており、アクセス数も多く、コンテンツを格納しているDBに高い負荷がかかりやすい状況となっている基盤があります。
DBへの高負荷が継続し、DBリソースが高騰したことで、下記のような課題が発生しました。
- サイトアクセス時の応答が遅くなる等で、提供サービスの品質に影響した
- リソース使用率が閾値を超えると監視アラートが発砲される仕組みであり、アラート発砲のたびに運用チームの復旧対応が必要となる。そのため、運用チームに稼働負荷がかかっている状況であった
運用チームによる、これまでの運用フローは下記の通りです。
- 何らかの理由で、DBリソースが高騰
- CloudWatchアラーム + Zabbix により、監視アラートが発砲される
- DBがオートスケールする
- 運用チームは30分待機し、リソースの高騰が収まっているかを目視で確認する
・収まっている場合 ⇒ 対処無し。完了。
・収まっていない場合 ⇒ 手動で該当インスタンスを再起動する。
特に4に関し、結果的にリソース高騰が収まったとしても30分の待機時間を必要とします。 待機中に他の監視アラートが発砲された場合は、そちらの対応も必要となりますし、運用チーム側の心理的負荷も無視できません。
解決案
DBのCPUメトリクス高負荷状態をトリガーとして、自動的に復旧(DB再起動)する仕組みを適用する
期待する効果
事象発生時、運用チームのアラート発砲と並行して即時復旧が動作するため、サービス影響を極小化することができる
自動復旧するため、運用チームの稼働負荷を削減することができる
設定したゴール
課題解決のため、何を満たせば充足するかを整理しました。
- DBの再起動中でも、サービス提供に影響がないこと
大前提です。 具体的には、DB再起動中でも通常通り外部からのアクセスができることが条件です。
- DBのCPU高負荷アラート発生時、該当インスタンスのみ即時再起動が走るようにする
すべてのインスタンスを再起動させる必要はありません。 サービスを通常通り継続させる意味でも、該当インスタンスのみの再起動で十分です。
- 複数インスタンスでアラートが発生した時は、シーケンシャルに再起動が行われること(全台同時再起動しないこと)
すべてのインスタンスを同時に再起動させてしまうとサービス提供ができなくなります。 そのため、複数台のリソース高騰が継続した状態の際は、順番に再起動するような仕組みとしました。
- 同一インスタンスで連続アラーム発報時は、再起動は1回とすること
仮に再起動してもCPU高騰状態が解消しなかった場合は、単なる高負荷状態ではなく別の原因が考えられます。 その状態で再起動をかけ続けてもエンドレスループするだけですので、再起動は1回と定義しました。
- ライターインスタンスは対象外とする
これまでの実績上、CPU高負荷が発生するのはリーダーインスタンスのみです。
また、ライターは一台構成であるため、ライターを再起動対象として実際に再起動が走ってしまうとサービスや運用に影響をきたしてしまうためです。
仕組みの検討
まず、現状がどのような構成となっているか、機能としてどのように修正すべきかを下記のように整理しました。
現在の構成

SNS ⇒ SQSの場合、メッセージ毎にランダムなグループIDが自動発行される
今後の構成
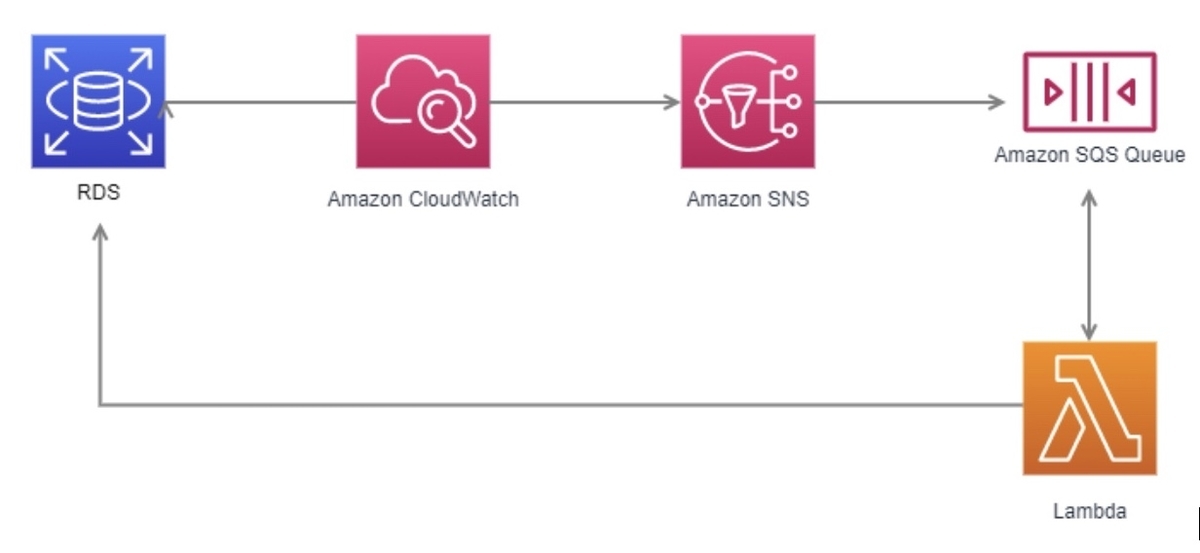
<参考> https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/with-sqs.html
FIFO キューの場合、Lambda は、受信した順序でメッセージを関数に送信します。FIFO キューにメッセージを送信する場合、メッセージグループ ID を指定します。Amazon SQS は、同じグループ内のメッセージが Lambda に順番に配信されるようにします。Lambda はメッセージをグループにソートし、グループに対して一度に 1 つのバッチのみを送信します。関数がエラーを返す場合、その関数は、Lambda が同じグループから追加のメッセージを受信する前に、対象メッセージですべての再試行を試みます。 関数は、アクティブなメッセージグループの数に並行してスケールできます。詳細については、AWS コンピューティングブログの「イベントソースとしての SQS FIFO」を参照してください。
SQSの前段でグループIDを固定することで、すべてのメッセージを同グループにする必要があります。
関連するAWSサービス
| AWSサービス | 役割 | 備考 |
| Aurora MySQL5.7 | コンテンツを格納。今回の対象。 | ライターインスタンス:1台 リーダーインスタンス:3台 ※オートスケール構成 |
| CloudWatchアラーム | ・Zabbix連携用(既存) ・SQS連携用(新規) 既存アラーム(RDSのCPU監視)と同メトリクス、同閾値(90%)の新規アラームを作成自動再起動連携用SNSへの通知をアラームアクションに追加し、Zabbix連携はしない | |
| SQS | ・SQSQueue メッセージの重複排除のためFIFOキューに設定 ・DLQueue Lambdaリトライ失敗時にメッセージを受信しアラーム通知する | |
| SNS | サブスクリプションのエンドポイントにSQS転送用Lambdaを指定 | |
| Lambda | ・グループID固定してメッセージをSQSに転送 ・SQSをトリガーにRDS再起動 |
仕組みの適用
下記構成図のように設計し、環境を構築しました。
再起動自動化の機構
処理の流れは下記の通りです。
- DBの負荷が高騰する
- 既存のZabbix連携用のCloudWatchアラームに連携され、監視が発砲される(運用チーム確認用)
- 並行して新規作成したDB再起動用CloudWatchアラームに連携される
- SQSにて監視状態がキューイングされ、Lambdaを呼び出す
- Lambdaをトリガーとして該当DBを再起動させる
【補足:Lambda処理概要】
メッセージがインスタンス名を取得
DBにインスタンス識別を問合せ
問合せ結果より
┣「Writer」だった場合 ⇒ 正常終了
┗「Reader」だった場合 ⇒ 処理継続
DBに再起動要求
以下繰り返し
┣DBのインスタンス状態を問合せ
┗問合せ結果より
┣「Active」だった場合 ⇒ 正常終了
┗「Active」以外だった場合 ⇒ 処理継続
Lambda - rds-restart.py (DB再起動用 Lambda)
import traceback
import boto3
import json
import logging
import time
logger = logging.getLogger()
logger.setLevel(logging.INFO)
rds = boto3.client('rds')
def lambda_handler(event, context):
try:
print('event:')
print(event)
body = json.loads(event['Records'][0]['body'])
records = body['Records'][0]['Sns']
message = json.loads(records['Message'])
instance_to_reboot = message['Trigger']['Dimensions'][0]['value']
print('instance_to_reboot:')
print(instance_to_reboot)
dbs = rds.describe_db_instances(
DBInstanceIdentifier = instance_to_reboot,
)
cltsname = dbs['DBInstances'][0]['DBClusterIdentifier']
cltsinfo = rds.describe_db_clusters(
DBClusterIdentifier = cltsname,
)
insinfo = cltsinfo['DBClusters'][0]['DBClusterMembers']
writer = next((writerinfo for writerinfo in insinfo if writerinfo['DBInstanceIdentifier'] == instance_to_reboot), None)
if writer['IsClusterWriter']:
print('writerインスタンスは再起動しません')
return
rds.reboot_db_instance(
DBInstanceIdentifier = instance_to_reboot,
ForceFailover = False
)
dbs = rds.describe_db_instances(
DBInstanceIdentifier = instance_to_reboot,
)
status = dbs['DBInstances'][0]['DBInstanceStatus']
print('status:')
print(status)
while status == 'rebooting':
time.sleep(3)
dbs = rds.describe_db_instances(
DBInstanceIdentifier = instance_to_reboot,
)
status = dbs['DBInstances'][0]['DBInstanceStatus']
else:
print('status:')
print(status)
return
except Exception as e:
logger.error(e)
print(traceback.format_exc())
raise Exception('Something went wrong.')
効果
本対応により、下記の効果が得られたと考えています。
- サービス復旧のQCDの向上
属人性が排除されたことで作業品質が上がり、どのようなケースでも最速で再起動されるため、復旧に要する時間も低減された
- 運用フローの改善
DBオートスケール後、CPUの高騰状態によらずDBの自動再起動が行われるため、30分の待機が不要となり、運用負荷が軽減された (Zabbixの監視発砲も維持するため、事象が発生したこと自体も継続して確認できる)
副次的効果と今後の予定
今回は「DB」の「再起動」に焦点を充てましたが、ベースとなる仕組みが構築できたことで、今後は利用範囲を広げることが可能と思います。 例) アラート対象となるAWSリソースとメトリクスの拡充 DBのメモリ使用率 EC2インスタンスのCPU、メモリ使用率 ECSのCPU、メモリ使用率 等 重大な監視発砲をSlackに連携 高騰となった疑義箇所の調査結果の自動通知 etc…
副次的ではありますが、狙い通りだったかと考えています。
その他よもやま話
Q)DBリソース高騰が理由なら、インスタンスサイズあげるか、台数を増設すれば良いのでは?
A)本環境で提供している各種サービスの特性として、「予期できないバースト」が発生することが挙げられます。その局所的なバーストに対応するためだけにスペックや台数をあげることはコストパフォーマンスが悪いため、今回の対応としました。 先述通り、今後の自動化拡充に向け、ベースとなる仕組みをまず構築したかったことも理由の一つです。