
はじめに
こんにちは、NTTドコモ サービスイノベーション部の内藤(@dcm_naitou)です。
普段はマーケティング分野へのAI技術の導入・運用業務に携わっています。
今回は、Spotify ChartsとSpotify APIから2023年の人気楽曲データを取得し、日本と世界で音楽の嗜好の違いについて分析してみました。
分析の目的
今回のSpotifyデータの分析の目的は、日本と世界で音楽の聴き方がどのように違っているかを分析することにあります。
ビジネス的なインサイトを得たいというよりは、単純に興味本位での分析という側面が強いです。
個人的に前々から日本人の音楽に対する向き合い方に興味があり、今回この場を借りて実際にデータ分析を行ってみました。
データセット
データセットはSpotify Charts と Spotify API を用いて作成しました。 *1
まずはデータセットをどのようにして作成したかご説明します。
準備
- Spotifyのアカウントを作成します。
- Spotify for Developersに作成したアカウントでログインします。
- 右上のアカウントアイコンからDashboardを開きます。
- "CREATE AN APP" を押下し、必要事項を入力の上、"CREATE APP" を押下します。
- Client IDとClient Secretが表示されれば準備完了です。
Daily Top Songsのデータを取得
日本及びグローバルのDaily Top Songsデータの取得方法です。
はじめにお伝えしておくと、かなり力技な方法となっております。
他にもっと上手い方法があったかもしれないですが、今回限りのデータのため力技で押し切りました。
Spotify Charts のDaily Top Songsを開きます。
すると、グローバルの今日のtop200曲が羅列されているページが開かれます。
日本のデータを見たい場合は、右上のGlobalと表示されているボタンをクリックして、Japanに変更します。
それから今日の日付が書かれているボタンをクリックして、取得したい日付に飛びます。
あとは右上の下矢印(↓)マークをクリックすれば、指定した日付・地域のTop200曲のデータがダウンロードできます。
今回は2023年1月1日から12月31日までの日本・グローバルそれぞれのデータをひたすらポチポチしてダウンロードし、テーブルを作成しました。
ダウンロードしたデータは次のコードで結合しました。
from datetime import datetime as dt from datetime import timedelta origin_dir = "/data/spotify_top200_daily_2024_global/" start_date = dt.strptime("2023-01-01", '%Y-%m-%d') str_start_date = start_date.strftime("%Y-%m-%d") tmp_file = f"regional-global-daily-{str_start_date}.csv" df = pd.read_csv(origin_dir + tmp_file) df["date"] = start_date for i in range(1,365): tmp_date = start_date + timedelta(days=i) str_tmp_date = tmp_date.strftime("%Y-%m-%d") tmp_file = f"regional-global-daily-{str_tmp_date}.csv" tmp_df = pd.read_csv(origin_dir + tmp_file) tmp_df["date"] = tmp_date df = pd.concat([df, tmp_df], ignore_index=True)
作成されたテーブルは下のようになっています。
楽曲の情報をAPIを叩いて取得
このままでは楽曲の詳細情報がないため、SpotifyのAPIを叩いて楽曲情報を取得します。
まずはSpotify APIを叩くための下準備を行います。
client_id, client_secretにはSpotify for Developersで作成したClient ID, Client Secretを貼り付けてください。
! pip install spotipy import spotipy from spotipy.oauth2 import SpotifyClientCredentials import json client_id = '******************************' client_secret = '******************************' client_credentials_manager = spotipy.oauth2.SpotifyClientCredentials(client_id, client_secret) spotify = spotipy.Spotify(client_credentials_manager=client_credentials_manager)
下準備が完了したら、いよいよAPIを叩きます。
# 取得したい楽曲のリストを作成 unique_tracks = df[['artist_names', 'track_name', 'uri']].drop_duplicates() print(len(unique_tracks)) unique_tracks.head()
# APIを叩いて楽曲情報を取得 import time track_info = pd.DataFrame() track_id_lst = unique_tracks["uri"].tolist() chunk_size = 100 chunks = [track_id_lst[i:i + chunk_size] for i in range(0, len(track_id_lst), chunk_size)] print([len(c) for c in chunks]) for i in range(len(chunks)): chunk = chunks[i] try: audio_features = spotify.audio_features(chunk) for af in audio_features: tmp_df = pd.DataFrame(af,index=[0]) track_info = pd.concat([track_info, tmp_df]) time.sleep(1) except spotipy.SpotifyException as e: if e.http_status == 429: # If rate limit is hit, wait and retry retry_after = int(e.headers.get('Retry-After', 1)) print(f"Rate limit hit. Retrying after {retry_after} seconds...") time.sleep(retry_after+1) # Retry the request continue else: # If it's a different error, raise it raise track_info = track_info.reset_index(drop=True) track_info.head()
注意点として、1曲ごとにリクエストを送信すると429エラー(リクエストが多すぎる)が返され、24時間ほどAPIが叩けなくなってしまいます。そのため今回は楽曲情報を100曲ずつ取得しています。 取得できる楽曲情報の要素の一例を以下に列挙します。
acousticness: アコースティック感。どれくらい物理的な楽器で演奏されているかを示す。danceabillty: どれくらいダンスに適している曲かを示す指標。duration_ms: 曲の長さ(ミリ秒単位)。energy: 楽曲のエネルギッシュさ。0~1の値を取り、1に近いほどエネルギッシュな曲であることを示す。liveness: 楽曲のライブ感がどれだけあるかを示す指標。loudness: 楽曲の音量、音圧。speechiness: 楽曲の語り調の強さを示す値。1に近いほど語り調の強い曲。tempo: 楽曲のテンポ(速さ)key: 楽曲のキー。valence: どれくらいポジティブな印象を与えるかの指標。0~1の値を取り、0に近いほどネガティブな印象、1に近いほどポジティブな印象を与える楽曲であることを示す。
日本とグローバルで音楽の嗜好の違いを分析
データセットが作成できたので、いよいよ分析に移っていきます。
ランクインした楽曲の特徴
今回は、energy(エネルギッシュさ), valence(ポジティブさ)に注目して分析を行いました。
2023年の1年間で日本では937曲、グローバルでは1569曲がデイリーtop200にランクインしています。
まずは、それぞれのスコアの分布をピラミッドグラフで比較してみます。
なお、日本とグローバルで曲数が異なるためパーセンテージで表示しています。
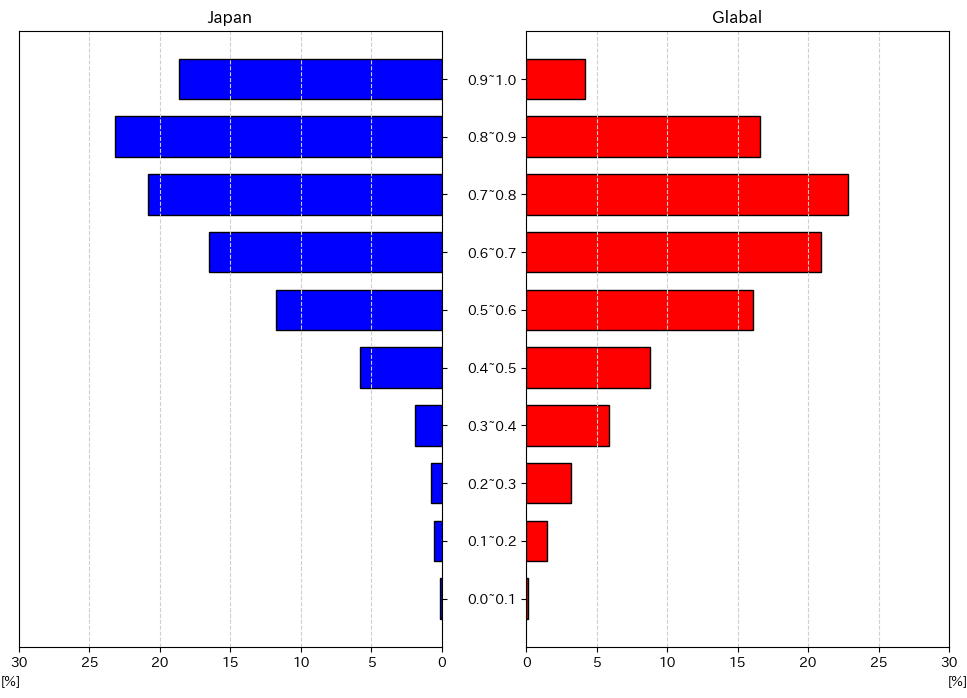
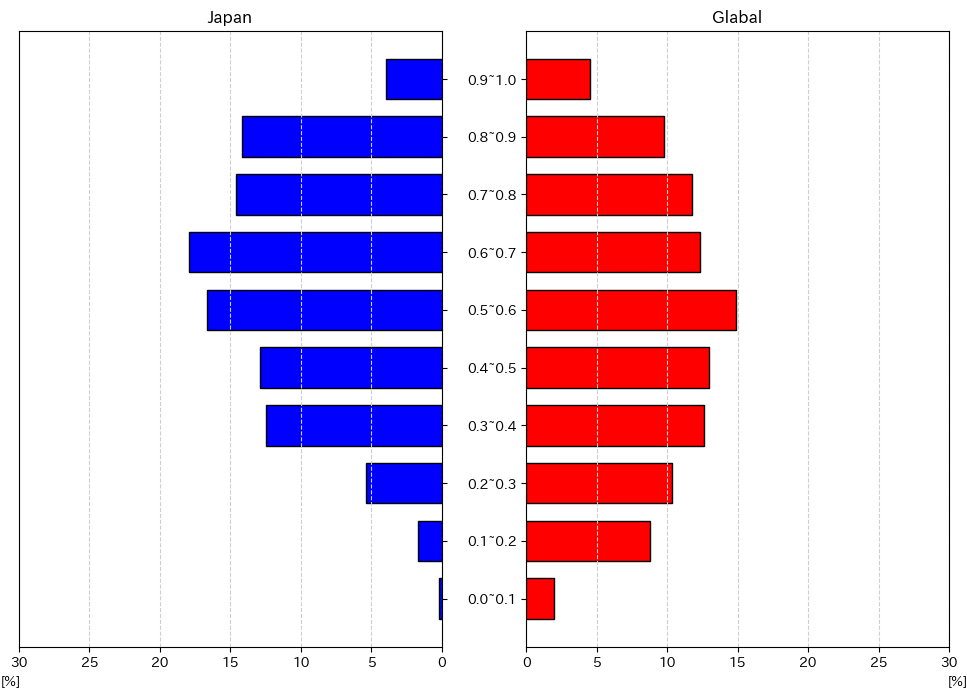
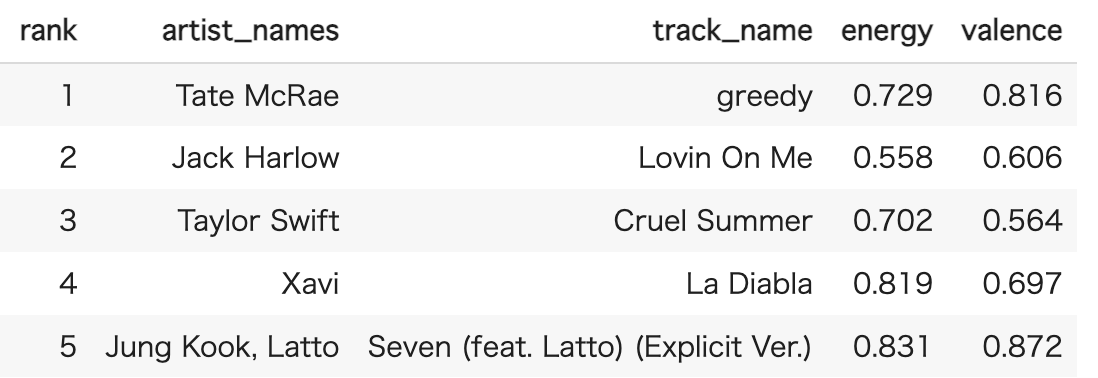
これらのグラフから、日本の方がenergy, valenceどちらも高い傾向にあり、よりエネルギッシュでポジティブな楽曲がランクインしている傾向にあることがわかりました。
個人的には日本の人気楽曲は海外と比較して落ち着いているイメージがあったので、この結果は少し意外でした。
それぞれの指標がどのように算出されているのかについて、詳細な情報は得られませんでしたが、もしかすると日本の楽曲の方がエネルギッシュさやポジティブさが高く算出される傾向にあるのかもしれません。
時系列でトレンド分析
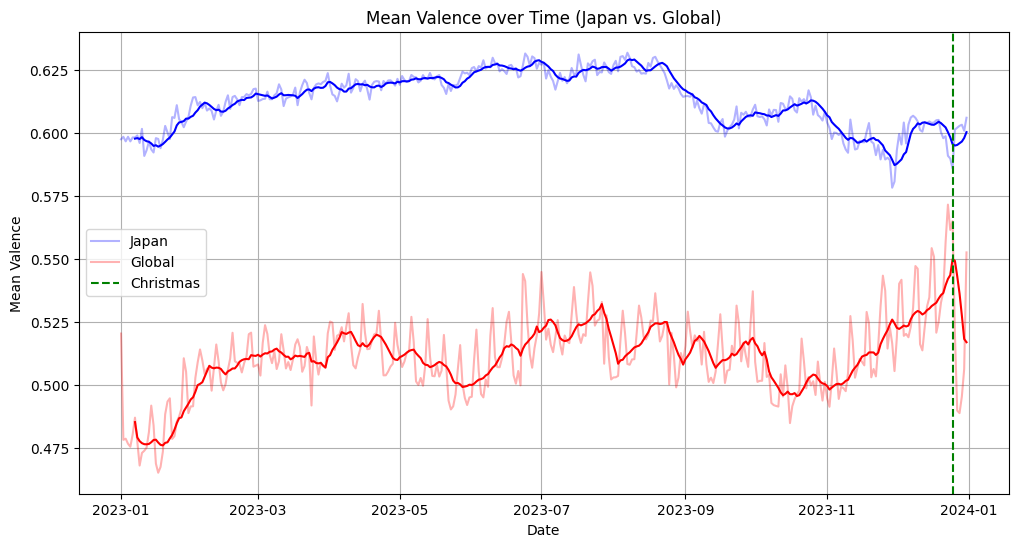
次にenergy, valenceの両方で時系列グラフを作成し,季節ごとにどんなトレンドがあるのかを見てみました。
1日ごとにランクインしている200曲の平均値を取ってプロットしています(薄い折れ線)。
また、トレンドがわかりやすいように移動平均をwindow=7daysとしてとり、プロットしました(濃い折れ線)
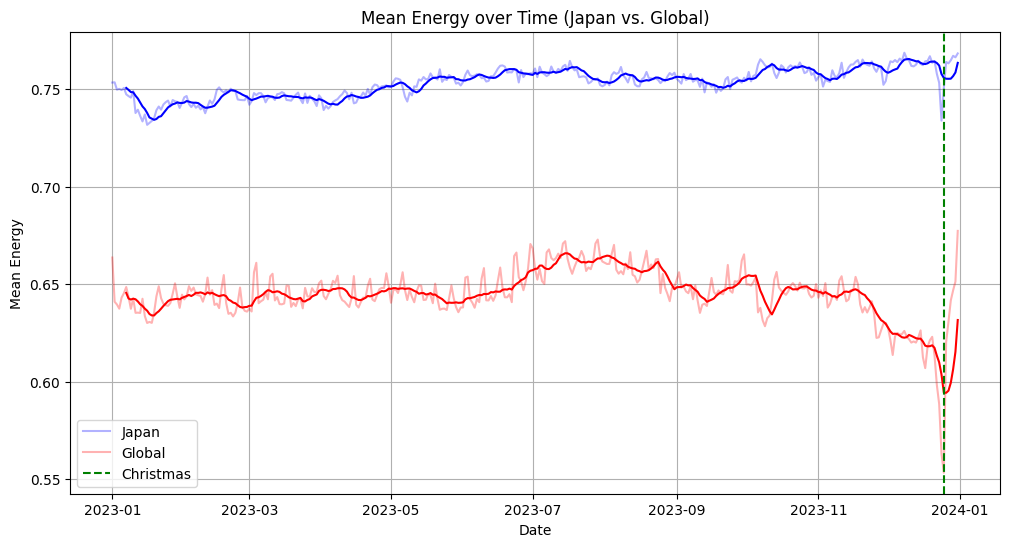
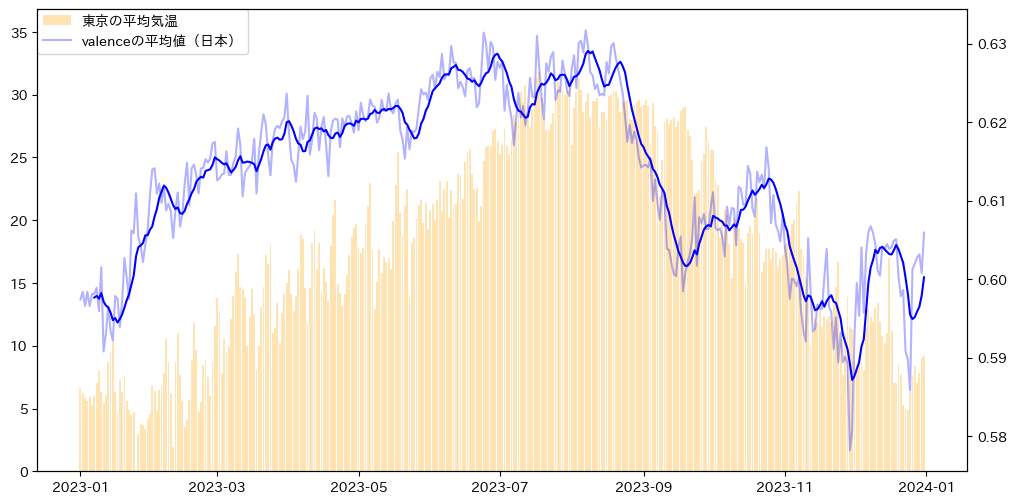
相関係数は0.576となっており、少し弱めですが相関も認められます。
因果関係は不明ですが、日本人は気温が高くなるとポジティブな曲を聞きたくなるようです(?)
「季節外れ」という言葉もありますが、もしかすると日本は世界と比較し、それぞれの季節やイベントを色濃く映し出すような曲が好まれる傾向にあるのかもしれません。
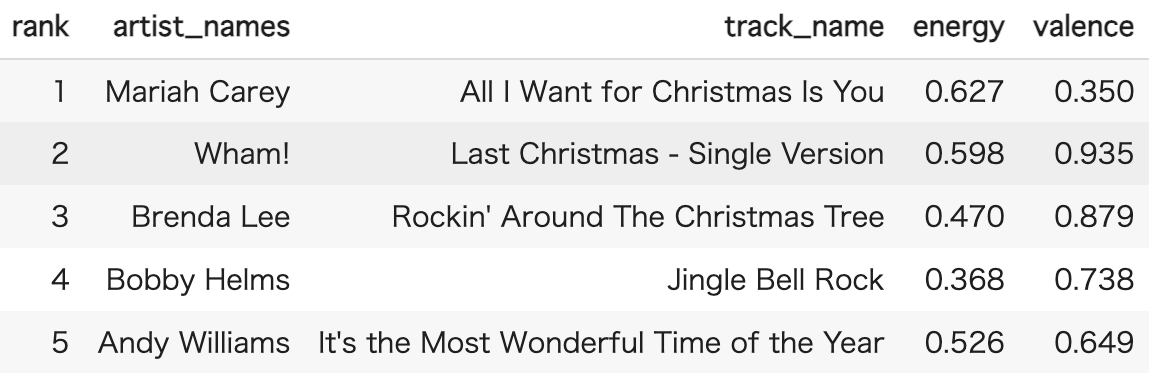
グローバルでは11月から12月にかけての秋から冬への移り変わりの時期に急激にスコアが高くなる傾向が出ています。
クリスマスにかけてはenergyとは逆の動きになっており、曲調は落ち着いているものが多くなっても、曲の伝えるメッセージはポジティブなものが多くなるようです。
最後に
今回はSpotify ChartsおよびSpotify APIからデータを取得して、日本と世界で人気な音楽の傾向にどんな違いがあるのかを分析し、以下のような知見が得られました。
- 日本は世界と比較してよりエネルギッシュでポジティブな楽曲が人気を得ている。
- 世界ではクリスマス付近でクリスマスソングが非常に多く聞かれている。
- 日本では気温が上がるとよりポジティブな曲が人気になる。
イメージ通りの結果もあれば予想外の結果もあり、大変興味深かったです。
イメージと異なる結果が得られるのもデータ分析の醍醐味であり、面白さだと思っています。
今回は2023年のデータを分析対象としましたが、他の年でも同じような傾向があるのかについても調査していきたいです。
この記事を読んでデータ分析の面白さを少しでも実感いただけましたら著者としての冥利に尽きます。 最後まで読んでいただき、ありがとうございました!