
はじめまして。R&D戦略部社会実装推進担当の天沼です。普段の業務ではLLMを活用した業務改善の検討などを実施しております。
さて、2024年もあと1週間ほどで終幕というフェーズを迎えておりますが、皆様いかがお過ごしでしょうか。本日この記事ではテーブルデータ×LLMという領域に絞って、論文の紹介をしていきたいと思います。
1. この記事の想定読者
- csvファイルだったり、エクセルファイルなどの表形式データをLLMで取り扱う方法についてざっくり知りたい。
- 普段SQLなどを書く業務を行っており、LLMで自動化できないか考えている。
2. なぜテーブルデータ×LLMを扱うのか?
私自身もこれまでの業務の中で企業のデータを扱って推論や分析をしてきており、その中で2つの疑問を持っていました。
LLMやVLMによる推論に関して、画像や言語などの所謂非構造データの扱いについては日進月歩で進化しているが、テーブルデータだと結局LightGBMなどの木構造のモデルが未だに根強い印象
Q1 LLMでのテーブルデータの推論手法は出てきているのだろうか?LLM agentなどLLM自身が判断をしながらタスクをこなす手法が多く出てきている
Q2 LLMでデータベースを操作したり、データベースを設計するような手法はあるのか?
ということでAdvent Calenderを機にしっかり調べてみようと思い、今回まとめてみることにしました。
3. テーブルデータ×LLMの領域の全体感とこの記事が扱う領域
テーブルデータとLLMの組み合わせで実施できると考えられるタスクは大きく①予測 ②データ生成 ③テーブル理解の3つにカテゴライズされます。( Xi Fang et al, 2024 [1] )
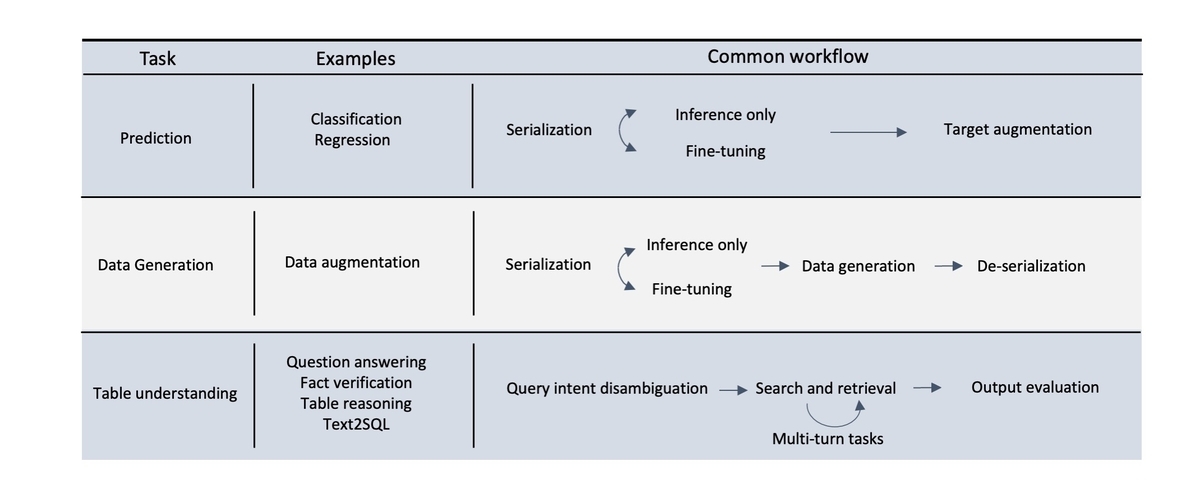
①の予測は機械学習とテーブルデータによる分類や回帰の問題が該当します。
②のデータ生成は例えば欠損値補完であったり、合成データの生成などが該当します。
③のテーブル理解はテーブルデータの情報に基づいた
- QA(商品に関する質問に対して商品スキーマ上の情報を基に回答する)
- テーブルデータによる事実確認(クレジットカードの本人確認でパスワードが実際の情報と一致するかの検証)
- text2SQL (自然言語の指令をSQL文に変換する)
などが該当します。
今回は特に③のテーブル理解に狙いを定めて論文紹介をさせて頂ければと思います!
4. 論文紹介
今回は「LLMによるテーブル理解」の領域に絞って2つ論文を紹介します。
Table Meets LLM [4]
この論文では、プロンプトベースでテーブルデータを扱う方法の網羅的な調査と、CoTに類似したプロンプト手法の提案をしています。プロンプトに限定しているが故に「まずはちょっと試してみよう」という段階で非常に参考になる論文だと思い選定しています!
[論文の特徴(主観)]
| 項目 | 評価 |
|---|---|
| 新規性 | ★ |
| 手軽さ | ★★★ |
この論文が扱う研究課題
[問題]
これまでの研究ではテーブルデータをLLMの入力として入れることで情報処理ができる点は確認されていましたが、LLMにテーブルデータの情報を入れる際のプロンプトデザインは論文ごとに異なっており、どの手法が有効なのか評価するのが難しいです。
例えば以下のようなデータテーブルがあるとします。
| name | age |
|---|---|
| Taro | 22 |
| Jiro | 23 |
このテーブルをもとに「今22才の人の名前を教えて」という質問をLLMに聞こうとしたとき、3つほど代表的な手法を取り上げると、プロンプトは以下のようになります。
- Markdown(HTML, XML, JSON)など所定の書式でテーブル情報を入力する。
# question Please tell me the name of someone who is 22 years old ,based on the information in the table data. # Table | name | age | | Taro | 22 | | Jiro | 23 |
- TAPEX [2] 特殊トークンを定義し、指定する。
# question Please tell me the name of someone who is 22 years old ,based on the information in the table data. # table [HEAD] name | age [ROW] 1 : Taro| 22 [ROW] 2 : Jiro | 23
- TableGPT [3]
# question Please tell me the name of someone who is 22 years old ,based on the information in the table data. # table Tara is 22 years old. Jiro is 23 years old
上記のように入力方法が色々とあり、実際に我々がLLMでテーブルデータを扱おうとするとどの手法が良いのか判断に困ってしまいます。 そのためこの論文では次の問いに答えることを目的に研究を実施しています。
[課題]
LLMがテーブルデータを理解するのに最も適切なプロンプトデザインは何か?
論文の提案手法
プロンプトデザインを最適化するにはまずプロンプトデザインを評価する指標が必要になります。そのためこの論文ではまずSUC(Structual Understanding Capabilities) BENCHMARKというLLMがテーブルデータの構造的な情報をどの程度理解しているのかを測定するための指標を定義しています。その上でこの指標及び評価データセットに基づいてより良いプロンプトデザイン方法(STRUCTURAL PROMPTING)を提案しています。
SUC BENCHMARK
SUCはLLMのテーブルデータ構造の理解力を評価する枠組みで、大きく7つのタスクで評価します。
| index | タスク | 概要 |
|---|---|---|
| 1 | Table Partition | プロンプトの中で実際のテーブルデータの情報に該当するtokenを正確に把握する。例えば、表題や補足情報などがテーブルデータとは別情報であることを正確に識別するタスクなどを含む。 |
| 2 | Cell Loolup | 指定した値が存在するセルの位置情報を抜き出すタスク。例えば、商品レコード上で「料金が1000円」という条件に合致するセルの行と列番号のタプル |
| 3 | Reverse Lookup | セルのレコード(行) |
| 4 | Column Retrieval | 与えられたタスクを解くのに必要なカラムを特定するタスク。例えば「2024年12月の売り上げを算出して」というタスクに対して、「売上、日付」の2つのカラムを使えば良いと判断するなど。 |
| 5 | Row Retrieval | 与えられたタスクを解くのに必要なレコード(行)を特定するタスク。例えば「2024年12月の売り上げを算出して」というタスクに対して、日付列が"2024-12-01" ~ "2024-12-31"に該当するレコード(行)だけあれば十分であると判断するなど。 |
| 6 | Size Detection | テーブルデータの行と列の数を正確に判定する。 |
| 7 | Merged Cell Detection | 結合されたセルを正確に把握、理解する。 |
結果
以下に示す図が今定義した7つのタスクに関する精度を調べた結果になります。
1つ目の表はテーブルデータをプロンプトに記載する際のフォーマットの違いによる7つのタスクに実行精度を包括的に調べた結果を、2つ目はプロンプトを作る際のテクニックの有無で精度がどう変動するかを調べた結果になっています。
ここでは細かい表の説明は割愛させて頂いて、結論のみ述べさせて頂きます。
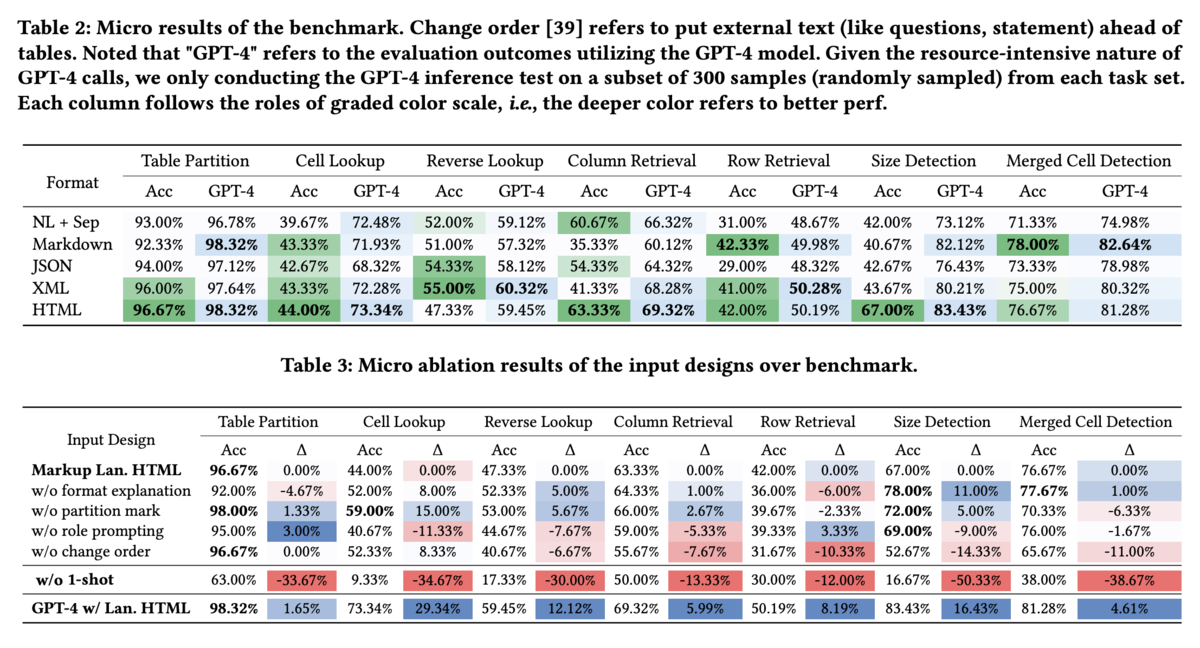
- HTMLフォーマットが最もLLMにとってテーブル構造を理解できます。
- Table2は様々なデータフォーマットごとに7つのタスクの実行精度を示しています。
- HTML形式が全体的に精度が高く、テーブルデータをLLMに与える際にはHTML形式が有効であると考えられます。
- SUCに関しては0-shot promptだと非常に精度が落ちます。
- Table 3のw/o 1-shotはプロンプトを作成する際にタスクの具体的な実行例の記載をしなかった場合の精度低下を検証しています。
- タスク平均して30.38%ほど精度が低下しており、LLMがテーブルデータを正確に把握するにはタスクに関する事前情報をICL的に学習させる必要があると言えます。
- プロンプト作成の際は質問などのタスクをテーブルデータ情報の手前においた方が精度が高くなる。
- Table 3のw/o change orderではプロンプト上で質問などのタスクをテーブルの後ろに記載した場合の精度を調べています。
- 各タスクの $\Delta$ が基本的にマイナスになっていることからタスクはテーブルの手前に記載する方が良いと言えます。
self-augmented prompting (SA)
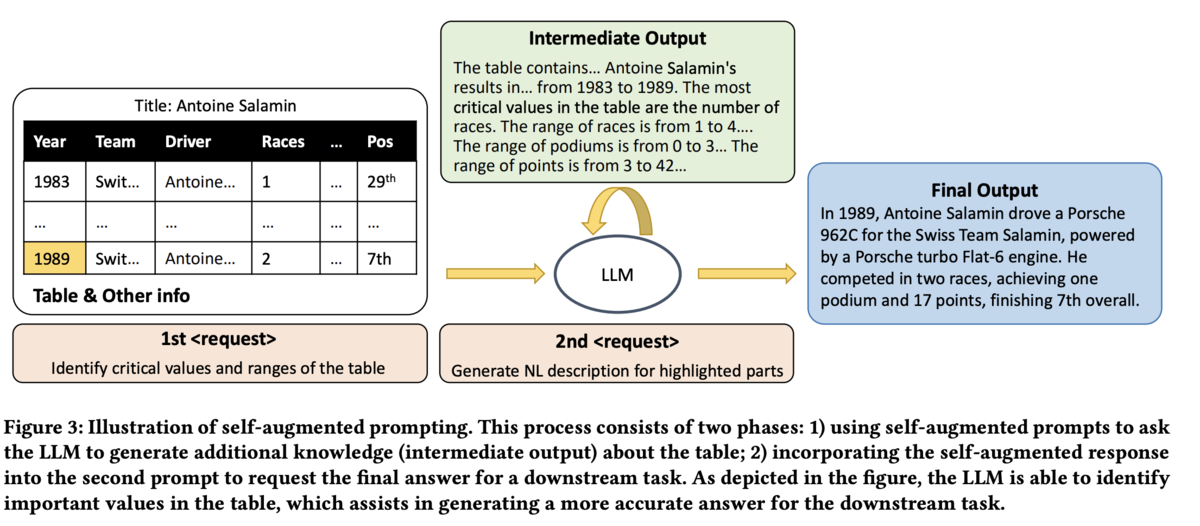
SUC BENCHMARKの結果からLLMはある程度はテーブルデータを理解できることが確認できたものの、例えばテーブルデータのサイズ検知などの簡単なタスクでも間違えるケースがそれなりにあることが分かります。そこで本論文ではCoT(Chain of Thought)から着想を得てself-augmented promptingという手法を提唱しています。
以下の図2. がこの手法の概要を示しており、2段階の推論を実行します。1段階目ではテーブル上の重要な情報の収集にフォーカスし、2段階目で実際に依頼したいタスクをLLMに与えます。
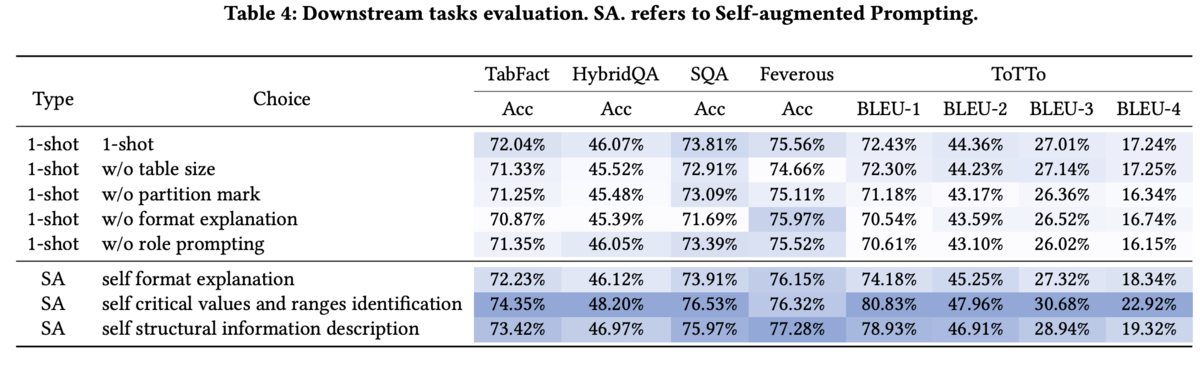
また表3が様々なデータテーブルタスクのデータセットに本手法を適用した際の結果を示しており、SAと記載されている本手法がどの評価データセットでも軒並み良い性能を出していることが確認できます。また論文中では例えばデータテーブルのサイズなどの情報を明示的に加えることで更に精度向上が可能である旨も報告されていました。
まとめ
本論文ではシンプルなプロンプトエンジニアリングではあるものの、LLMでテーブルデータを扱うことに関してかなり包括的に調べてあり、「まずは手元で試してみよう」という段階においてかなり参考になる論文だと思います。
TableRAG [5]
この論文ではテーブルデータ向けのRAG手法を提案しています。先ほど紹介した論文のようにプロンプトにテーブルデータ情報を全て埋め込むとプロンプト長が長くなってしまい、精度やコストの観点で問題になります。そこで必要な情報だけに絞り込む為に本論文ではTableRAGという手法を提案しています。
[論文の特徴(主観)]
| 項目 | 評価 |
|---|---|
| 新規性 | ★★ |
| 手軽さ | ★★ |
この論文が扱う研究課題
[問題]
LLMでテーブルデータを扱う手法の多くはテーブルデータの情報を全てプロンプトに入れる形になっていました。
一方でLLMには
- token長の制限
- ポジションバイアス(promptの順序がLLMの出力に影響を与えてしまう)
- lost-in-the-middle(プロンプトのtoken長が長い場合、中間の情報がLLMの推論に反映されなくなってしまう。)
などの問題があり、現時点ではプロンプトに含めるテーブルデータの情報は少ない方が好ましいと言えます。一方で現実で扱うテーブルデータは非常に大きいため、データテーブルの情報をそのままLLMに入れるのは得策ではありません。 そこで本研究では以下の課題に対して解決先を提示しています。
[課題]
LLMでtableデータを操作する場合に特化したRAG手法の提案し次の2点を実現する
- lost-in-the-middleなどの問題を軽減し、タスク精度を向上させる。
- 大きなデータセットも対応できるようにする。
論文の提案手法
TableRAGのコアとなるコンセプトはクエリに回答するのに必要な情報をLLMに判断させ、プロンプトに組み込む情報量を削減する になります。 例えば商品情報が格納されている以下のデータに対して「ブランドAが販売している財布の平均価格を教えて」という質問をするケースを考えてみます。
| 商品カテゴリ | 価格 | 商品id | ブランド |
|---|---|---|---|
| 財布 | 1万 | wallet-1 | A |
| 財布 | 2万 | wallet-2 | B |
| 財布 | 5000円 | wallet-3 | A |
| バッグ | 5万 | bag-a | A |
この時上記の質問に回答するのに必要な情報を考えると
- カラム:"価格"
- レコード(行) :
- 商品カテゴリが"財布"
- ブランドがA
であることが分かります。
ここまで情報が特定できれば、最後の計算部分は既存のLLM-Agent (論文中ではReActが採用されています) やtext to SQLなどに適用することで実行可能になります。そのためこの論文ではクエリコストを抑えながらテーブルデータと質問から上記のような情報を引き出す具体的なワークフローとして以下の図で示す手順を提案しています。
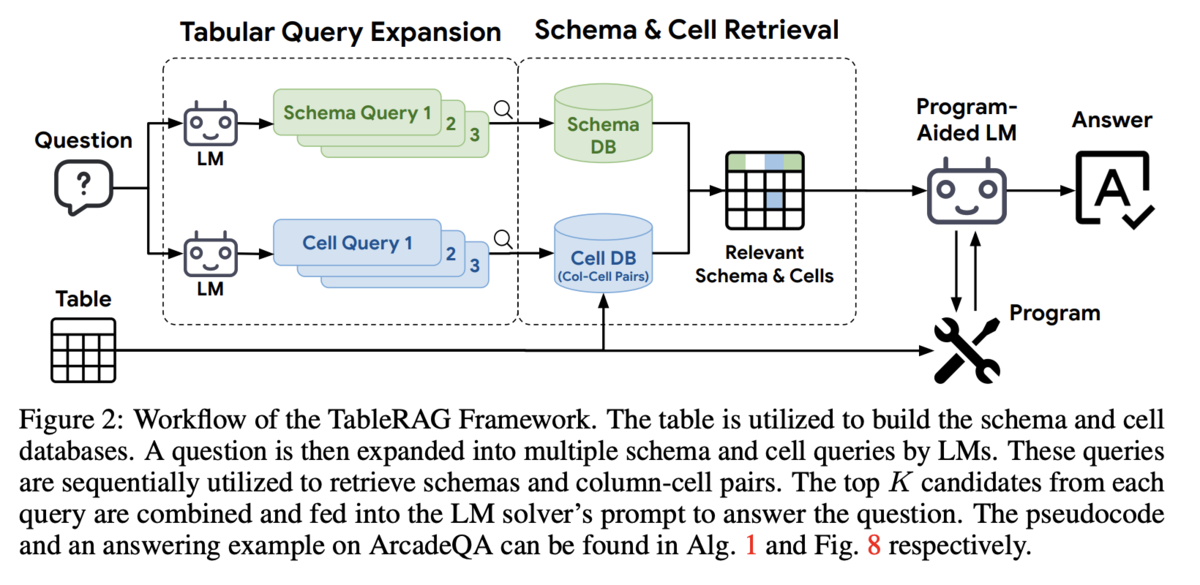
ワークフロー自体は今まで説明してきた内容をシンプルに実装しており、ユーザーからの質問に対して回答に使うカラムを特定する処理と、レコードの絞り込みに使う情報の特定を行い、それを別のProgram-Aided LM (text2SQLエージェントなど)に受け渡すことで回答を得るという流れになります。
カラム項目の選定については、多くても数百程度候補から選択するタスクになるので、テーブルの情報全てをLLMに含めるよりはプロンプト長が短くなります。
またレコードの絞り込みについては1つのカラムごとにユニークな値を調べるタスクとして扱うことでプロンプト長が短くできます。上記の商品情報のデータで言えば、商品カテゴリ列の絞り込みについては(商品カテゴリ, バッグ), (商品カテゴリ, 財布)の2つのタプルから質問に必要な要素を選定するという処理にするようなイメージになります。
そうすることでプロンプトに直接含めることになるテーブルデータ情報はかなり削減されることはイメージが出来るかと思います。
(論文内では厳密にどの程度のプロンプト削減が可能かについて議論しています。この点に興味のある方は是非原論文を覗いてみてください。)
実験結果
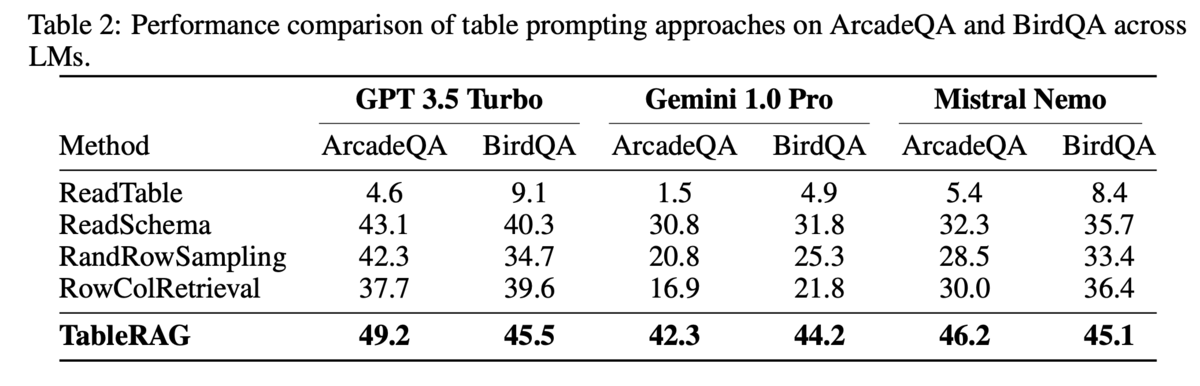
論文の提案手法の効果 (回答精度)
以下が他の既存手法と精度を比較したケースですが利用するLLMモデルによらず、TableRAGの精度が良いことが確認できます。このことからタスクをこなすのに必要な情報をある程度正確に取得できていると考えられます。 またArcadeQAで扱っているデータテーブルはレコード数が約8万行、カラム数が20列程度であるため比較的大きなデータセットも扱える可能性がありそうです。 (とはいえ企業のデータだと数千万とか数億レコードあるので、そこと比較すると小さいですが。。。)
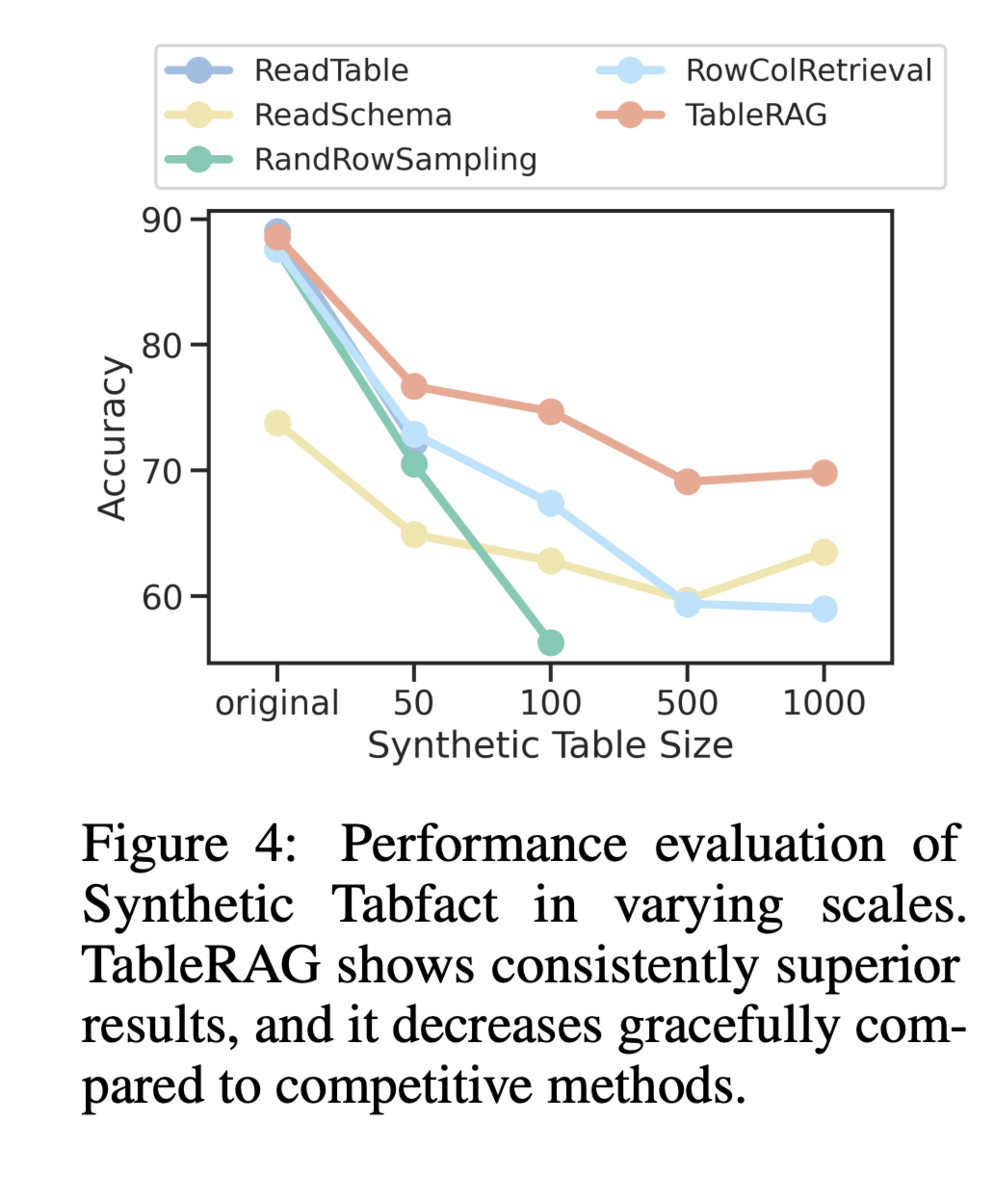
論文の提案手法の効果 (データのスケール対応)
TableRAGの目的の1つに「大規模なデータテーブルにも対応できる」という点がありました。次の図は横軸にデータテーブルのサイズに対する精度の変化を図示したものになります。この結果を見ると赤線で示されるTableRAGの精度はデータサイズの増加と共に減少はしているものの、他の手法と比較すると精度が良いことが確認できます。
まとめ
TableRAGによってテーブルデータに関するタスクをLLMに実行させることが可能になりつつあると思います。この手法の応用先として、お客様からの問い合わせにデータベースの情報を基に幅広に回答するQAボットなど企業としてはかなり応用先の広い技術かと思うので、是非みなさまも今後引き続き注目頂ければと思います。
5.今後について
今回はテーブルデータをLLMで扱う方法について紹介させて頂きました。AdventCalenderというイベントが調査のきっかけになったので、今回Advent Calenderに参加してみて良かったなと感じています、 個人的にもこの領域は様々な業務に適用できる可能性を感じており、今回調査した論文手法を中心に検証など進めていきたいなと思っております! 皆様残り1週間やり切って良いお年をお迎えください。それでは。
6. 参考文献
[1] : Xi Fang et al., 2024, Large Language Models(LLMs) on Tabular Data: Prediction, Generation, and Understanding - A Survey,, https://arxiv.org/html/2402.17944v2.
[2] : Qian Liu et al., 2022, TAPEX: TABLE PRE-TRAINING VIA LEARNING A NEURAL SQL EXECUTOR, https://arxiv.org/pdf/2107.07653.
[3] : Heng Gong et al., 2023, TableGPT: Few-shot Table-to-Text Generation with Table Structure Reconstruction and Content Matching, https://aclanthology.org/2020.coling-main.179.pdf.
[4] : Yuan Sui et al., 2024, Table Meets LLM: Can Large Language Models Understand Structured Table Data? A Benchmark and Empirical Study, https://arxiv.org/abs/2305.13062.
[5] : Si-An Chen et al., 2024 ,TableRAG: Million-Token Table Understanding with Language Models, https://arxiv.org/pdf/2410.04739