
TL;DR
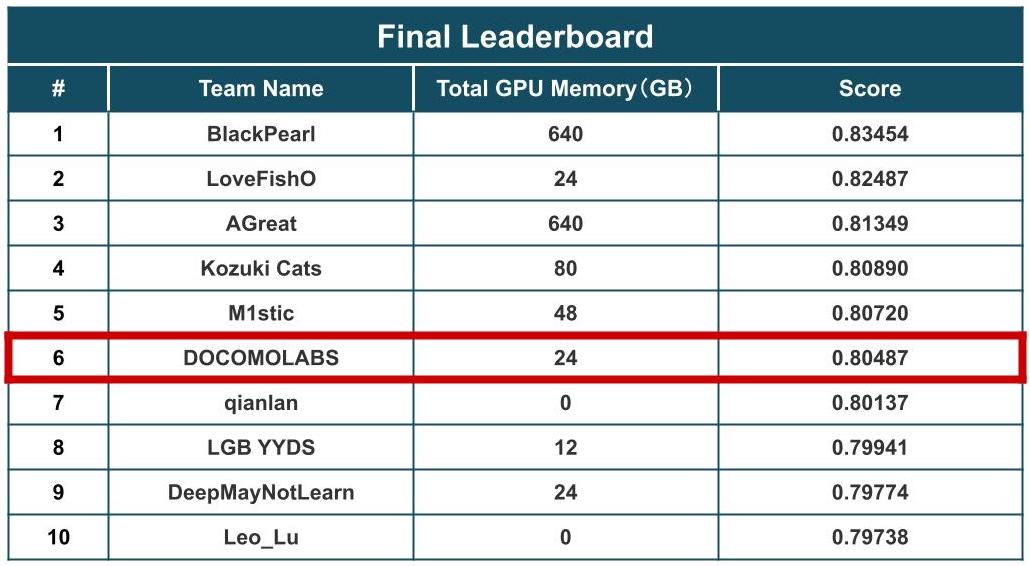
- NTT DOCOMO R&Dは,KDDCUP2024 OAG-INDタスクにおいて380チーム中6位入賞しました.
- KDD2024/KDDCUP2024に関する情報及び現地レポートについては,こちらの記事をご覧ください.
- 本記事では,OAG-INDタスクにおけるNTT DOCOMO R&Dの解法をご紹介します.
- NTT DOCOMO R&Dの解法をより詳細に知りたい方は,ソースコード及び論文をご参照ください.
はじめに
NTT DOCOMO R&D サービスイノベーション部 Principal Data Scientist 宮木健一郎です.
普段は,ドコモサービス内のレコメンドエンジン開発やプロファイリングツール開発に従事しております.
毎年NTT DOCOMO R&Dは,データマイニング国際学術会議 ACM KDD主催のデータ分析コンペティションKDDCUPに参加しており,今年も例年通りKDDCUP2024に参加しました.
また,その結果として本コンペティションの1つのタスクであるOAG-IND(Open Academic Graph - Incorrect Assignment Detection)タスクにおいて,380チーム中6位入賞することができました.
本記事では,OAG-INDタスクにおいてNTT DOCOMO R&Dが採用した解法をご紹介します.
コンペティション概要
OAG-INDとは?
KDDCUP2024 OAG-Challengeでは,学術グラフマイニングに関する3つのタスク(OAG-IND, OAG-AQA, OAG-PST)が課されていました.本記事でご紹介するOAG-INDは、"特定の著者に誤って紐付けられた論文の検知精度を競う"タスクです.他の2タスクに関してもNTT DOCOMO R&Dは入賞しており,解法を公開しておりますので気になる方は是非ご覧ください.
データセット・評価指標
データセット
OAG-INDタスクでは,以下の2種類のデータセットが提供されている.
- 1つ目:各著者に紐付く正しい論文ID群と誤って紐付けられた論文ID群をまとめたデータ
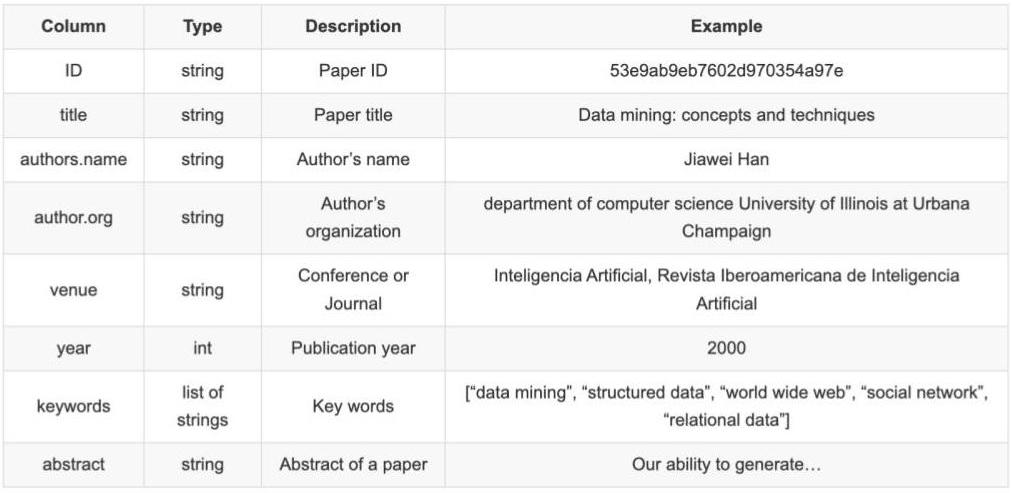
- 2つ目:各論文IDに紐付く,論文タイトルや著者名,論文概要などの論文メタデータ
論文メタデータ
評価指標
OAG-INDタスクの評価指標は,異常検知で広く採用されているAUC(Area Under the Curve)に対して,
著者毎に算出した重みを考慮したWeightedAUCでした.
ルール
本コンペティションは,2024/03/20〜2024/06/07の約3ヶ月間開催されました.更に,3ヶ月間が3つのステージ(検証ステージ/テストステージ/防衛ステージ)に分かれており,テストステージ終了時の上位11チームのみが防衛ステージに参加できる仕組みとなってました.防衛ステージでは,利用したソースコード及びハードウェアの詳細情報の提出が求められ,再現性がない場合は容赦なく失格となる仕組みでした.順位決定後は,OAG-INDタスクにおいて採用した解法に関する論文の提出及び現地発表が求められました.
ドコモ解法
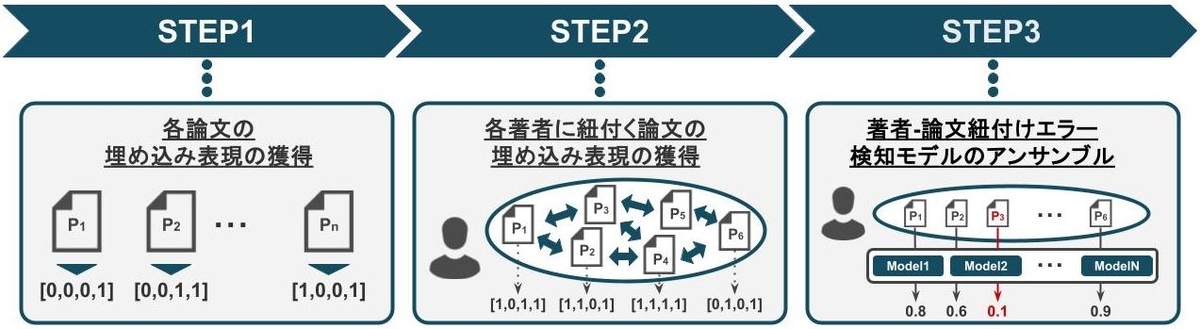
NTT DOCOMO R&Dは,各著者に誤って紐付けられた論文の検知モデルを3つのSTEPで構成しました.
各STEPの概要は以下の通りであり,各STEPの詳細については次章以降でご説明します.
- STEP1:各論文の埋め込み表現の獲得
- STEP2:各著者に紐付く論文の埋め込み表現の獲得
- STEP3:著者-論文紐付けエラー検知モデルのアンサンブル
NTT DOCOMO R&D Solution:Overview
STEP1:各論文の埋め込み表現の獲得
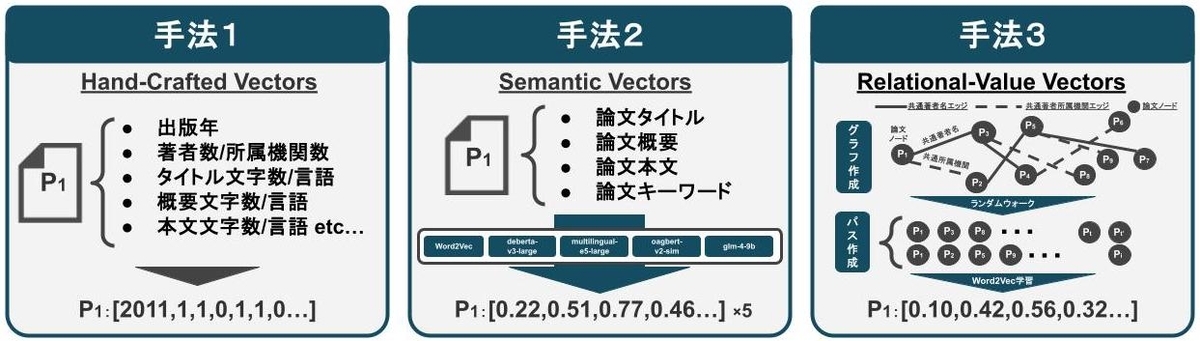
本STEPの目的は,「各論文を同一空間上に表現することで,論文間の距離を計算可能な状態にすること」です. 実装としては,以下の大きく3つの手法で論文の埋め込み表現を獲得し,結合することで多種多様な論文表現の獲得を目指しました.
- 手法1:Hand-Crafted Vectors
- 出版年や著者数,所属機関数など,各論文に紐付く基本情報を集計して埋め込み表現を獲得
- 手法2:Semantic Vectors
- 以下の単語・文章埋め込みモデルを活用して,論文に紐付くテキスト情報を加味した埋め込み表現を獲得
- Word2Vec
- Bidirectional Encoder Representations from Transformers(BERT)
- Large Language Models(LLM)
- 以下の単語・文章埋め込みモデルを活用して,論文に紐付くテキスト情報を加味した埋め込み表現を獲得
- 手法3:Relational-Value Vectors
- 以下の手順で論文間の関係値を加味した論文の埋め込み表現を獲得
- 手順1:各論文間における共通著者名や共通所属機関を活用して論文間の関係をグラフを用いて表現
- 手順2:手順1で作成したグラフ上で,ランダムウォークを実行し複数の論文パスを作成
- 手順3: 手順2で作成したパスをWord2Vecで学習し,各論文の埋め込み表現を獲得
- 以下の手順で論文間の関係値を加味した論文の埋め込み表現を獲得
STEP2:各著者に紐付く論文の埋め込み表現の獲得
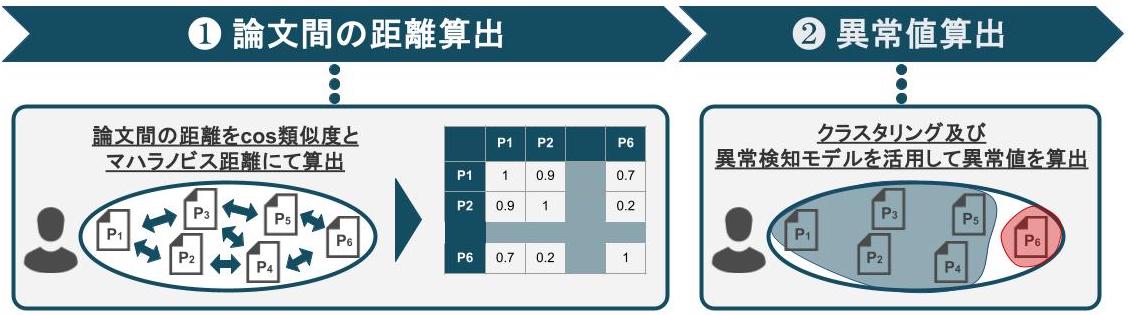
本STEPは,「同一著者が執筆した論文間の距離は近く,著者が異なる論文間の距離は遠い」という仮説の元に組み立てられています.その仮説を立てた上で,本STEPの目的を「同一著者に割り当てられた論文間の関係値を反映した埋め込み表現の獲得」としました.STEP2における実装手順は以下の通りです.
- 手順1:
- 同一著者に割り当てられた全論文間の距離を以下の2種類の手法で算出する
- 埋め込み表現同士を比較する際によく用いられるcos類似度
- 異常検知タスクによく用いられるマハラノビス距離
- 同一著者に割り当てられた全論文間の距離を以下の2種類の手法で算出する
- 手順2:
- 手順1で求められた各論文の埋め込み表現に対して,クラスタリング及び異常検知モデルを適用する
- クラスタリング:DBSCAN/K-Means/Gaussian Mixture Model
- 異常検知モデル:One-Class SVM/Local Outlier Factor/Isolation Forest
- 手順1で求められた各論文の埋め込み表現に対して,クラスタリング及び異常検知モデルを適用する
STEP3: 著者-論文紐付けエラー検知モデルのアンサンブル
最後に,本STEPでは提出フォーマットに従い「著者に誤って紐付けられている論文か否かを0-1のスコアで表現すること」を目的としました.実装としては,著者に正しく紐付けられた論文を1,誤って紐付けられた論文を0と推定するような二値分類モデルを採用しました.また,精度向上のため,kaggle等のコンペティションでよく用いられる複数モデルのアンサンブルを行いました.今回採用した二値分類モデルは以下の通りです.
- 二値分類モデル
- 木構造ベースのモデル:LightGBM / XGBoost / RandomForest
- ニューラルネットワークベースのモデル:7層ニューラルネットワーク / TabNet

最後に
改めて,KDDCUP2024 OAG-Challengeにおいて6位入賞することができ非常に嬉しく思います. また,最後の1週間は,大幅に睡眠時間を削ってスコアを上げ,安心して寝て起きたら順位が下がっていたりと一喜一憂して楽しかったです. コンペティション終了後も「ああすればもう少し順位上がったなあ」といった後悔や,上位のチームの面白い解法を見てモチベーションが上がったりと, とても良い時間を過ごしたなと思います.
今回,NTT DOCOMO R&Dでは,Large Language Models(LLM)をフルに活用した構成は,FineTuningの実行時間や推論時間が長時間であることから不採用としたのですが,上位勢は上手くLLMを活用しており,今後のトレンドとなるのは確実と感じたためLLM修行をしようと思います. 後日,LLMを活用した上位解法の記事も書こうかなと思っているので,そちらもチェックよろしくお願いします.