
TL;DR
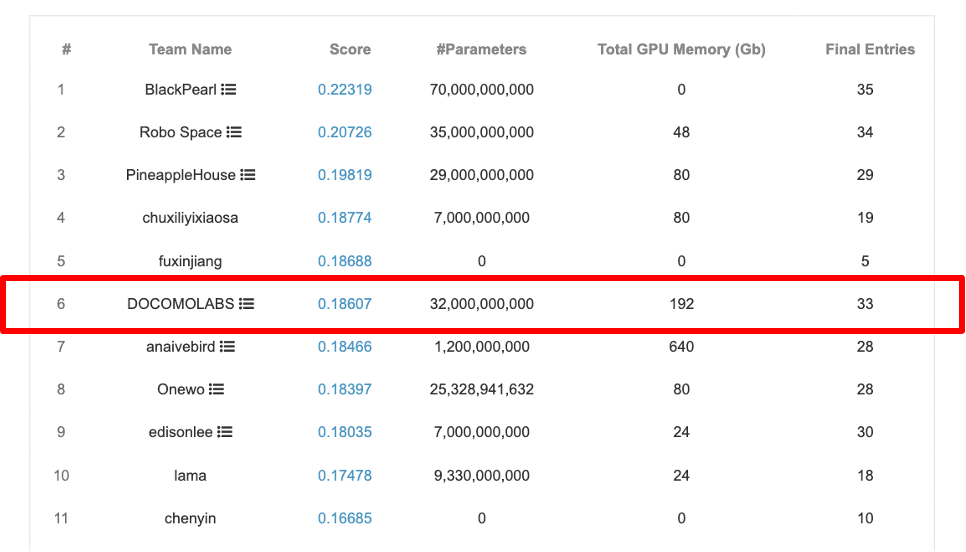
- データ分析コンペであるKDDCUP 2024 OAG-AQA にて6位 入賞したので、入賞解法を紹介します。
- KDD概要と現地参加した発表の様子はこちらの記事をご覧下さい。
はじめに
NTTドコモ クロステック開発部の鈴木明作です!
ドコモR&Dでは、データマイニング国際学術会議であるKDDで開催されているKDDCUPに毎年参加しており、 KDDCUP 2024 OAG-Challengeの一つであるOAG-AQA(Open Academic Graph - Academic Question Answering)にて、約300チームの中で6位入賞することができました。 この記事では、ドコモの入賞解法を紹介します。
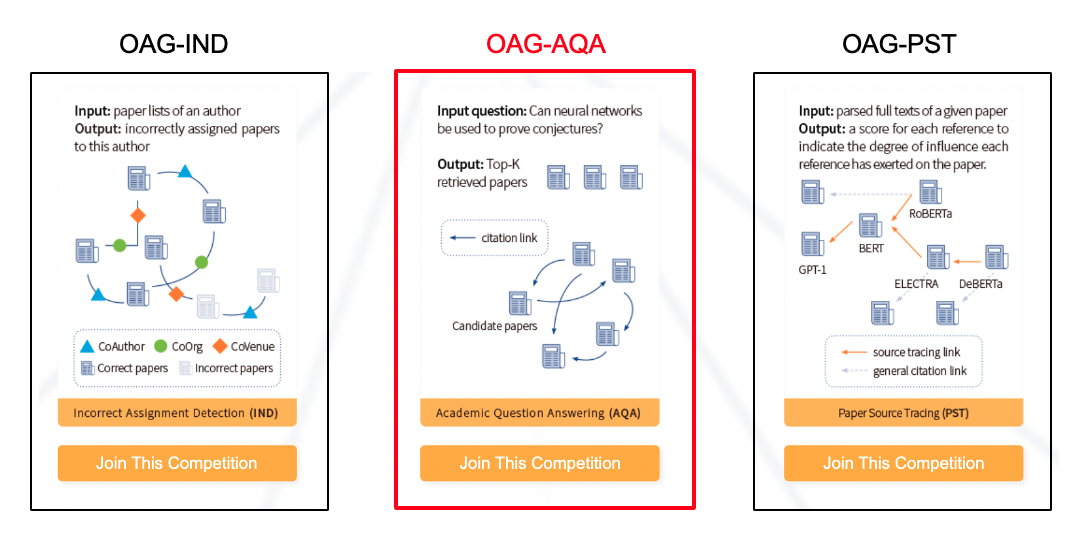
OAG-Challengeでは、学術グラフ マイニングに関する3つのコンペ(OAG-IND, OAG-AQA, OAG-PST)が開催され、
その中で、OAG-AQAは、"インターネットサイト上の専門的な質問に対して最も関連する論文20件の予測精度を競う"コンペでした。
評価指標はMAP@20で、20件の論文を予測結果とし、正解となる論文が20件の中で上位にあるほどスコアが高くなる評価指標です。
ドコモ解法
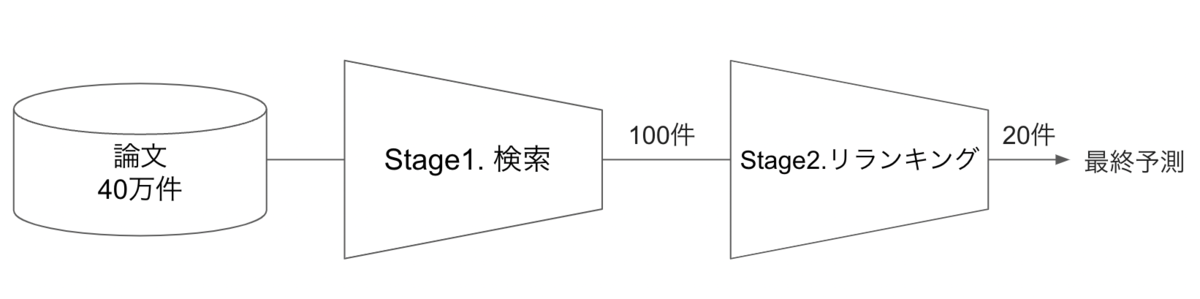
ドコモ解法のベースは2ステージランキングです。
2ステージランキングとは、stage1.検索、stage2.リランキング、の2段階に分けて予測を行います。 今回のコンペでは、stage1.検索にて、40万件の論文から候補となる論文を100件に絞り、stage2.リランキングにて、100件の候補論文を並べ替えて最終的に20件を予測とすることで、予測精度向上を図ります。
2ステージランキングは、Youtube, Twitterなどの大規模コンテンツをレコメンドするサービスでよく使われる手法です[1],[2]。今回のコンペにおいても、質問のマッチング対象である論文が40万件以上あり、「大規模コンテンツレコメンド」と似た問題設定であったため、2ステージランキングを採用しました。
stage1.検索
まず、stage1.検索において、40万件以上の論文から論文候補を100件絞り込みます。 この際に、以下の2つの工夫をすることで検索精度を向上させています。
① 対照学習
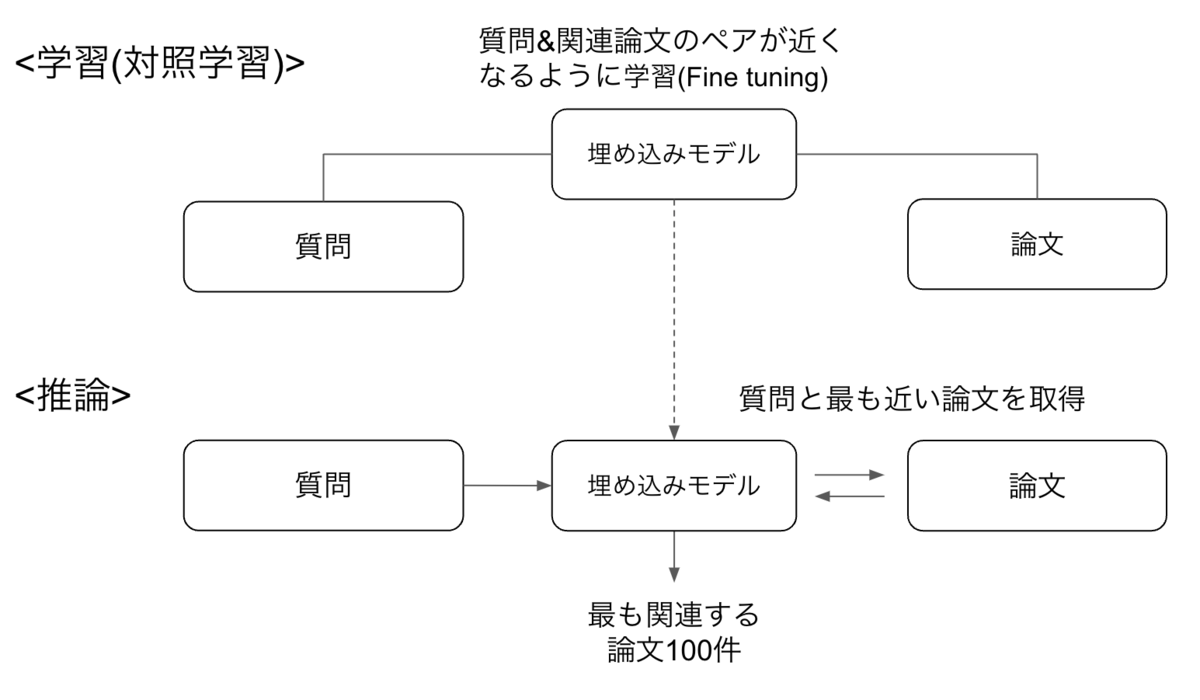
対照学習は「似たデータは近く、異なるデータは遠く」になるように学習する方法です。
今回のコンペでは”質問”と”最も関連する論文”の正解ペアが与えられるため、これらの正解ペアの類似度が高くなるように埋め込みモデルを学習(Fine tuning)します。その後に、学習したモデルを使って、質問と類似度が高い論文をベクトル検索することで検索精度向上を図りました。対照学習は、実装がシンプルである点からSimCSE[3]という手法を用いました。
② HyDE(Hypothetical Document Embeddings)
HyDE[4]はRAG(Retrieval Augmented Generation)の精度向上で活用される手法です。
HyDEは、質問(クエリ)を大規模言語モデル(LLM)で回答してもらい、その回答結果を質問(クエリ)に加えて再度検索を行うことで、検索精度向上を図ります。ドコモ解法では、「質問の回答」、「質問の要約」という2つでHyDEを実装することで、検索精度の向上を図りました。
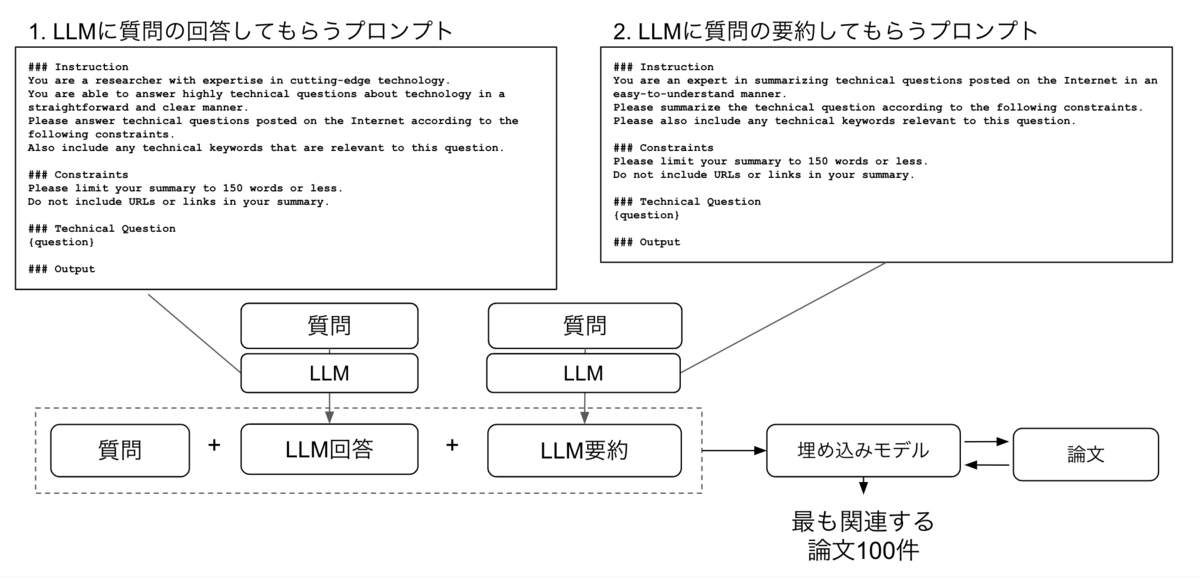
stage2.リランキング
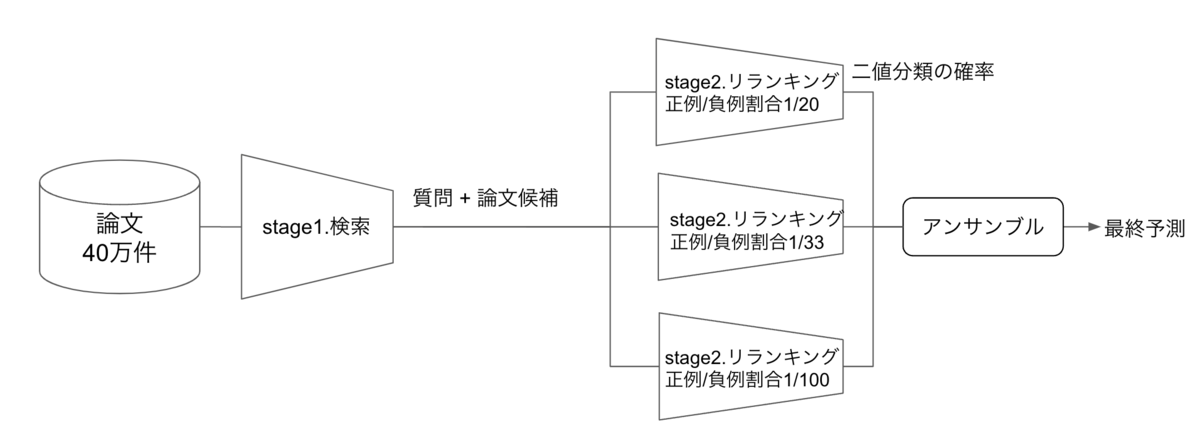
stage2.リランキングでは、stage1で絞り込んだ100件の候補論文に対して、言語モデルを用いて正解 or 不正解の二値分類を行います。最後にsoftmaxを通すことで0~1の予測確率値として、それらの確率値が最も高い20件の論文を最終予測とします。
また、stage1では、1つの質問に対して100件の候補論文を得ることにより、学習データの負例が多くなってしまうため、学習時にはネガティブダウンサンプリングを行いました。最後に、3つの異なるネガティブダウンサンプリングレートで学習させた言語モデルの推論結果を単純平均アンサンブルすることで、最終的に6位となるスコアを得ることができました 。
ドコモ解法は以下の論文とGitHubにまとめっているため、詳細はこちらを参照してください。
- ドコモチーム論文 Two-Stage Ranking Using HyDE and SimCSE for Paper Retrieval
- ドコモチーム GitHub
優勝解法
優勝チームは中国の"美団"というフードデリバリー大手企業で、優勝チームも2ステージランキングを採用していました。
優勝チームの解法では、stage1.検索において、最初に埋め込みモデルで類似度が高い論文200件を取得し、次に、200件の論文を使って埋め込みモデルの学習を行います。再度、埋め込みモデルを使って類似度が高い論文200件を取得しますが、その時の埋め込みモデルは先ほど学習したモデルを使うことで、逐次的に検索精度向上を図っている手法になります。モデルに対して、徐々に難易度の高いタスクを解かせることで、モデルの精度を高めていくユニークな手法でした。
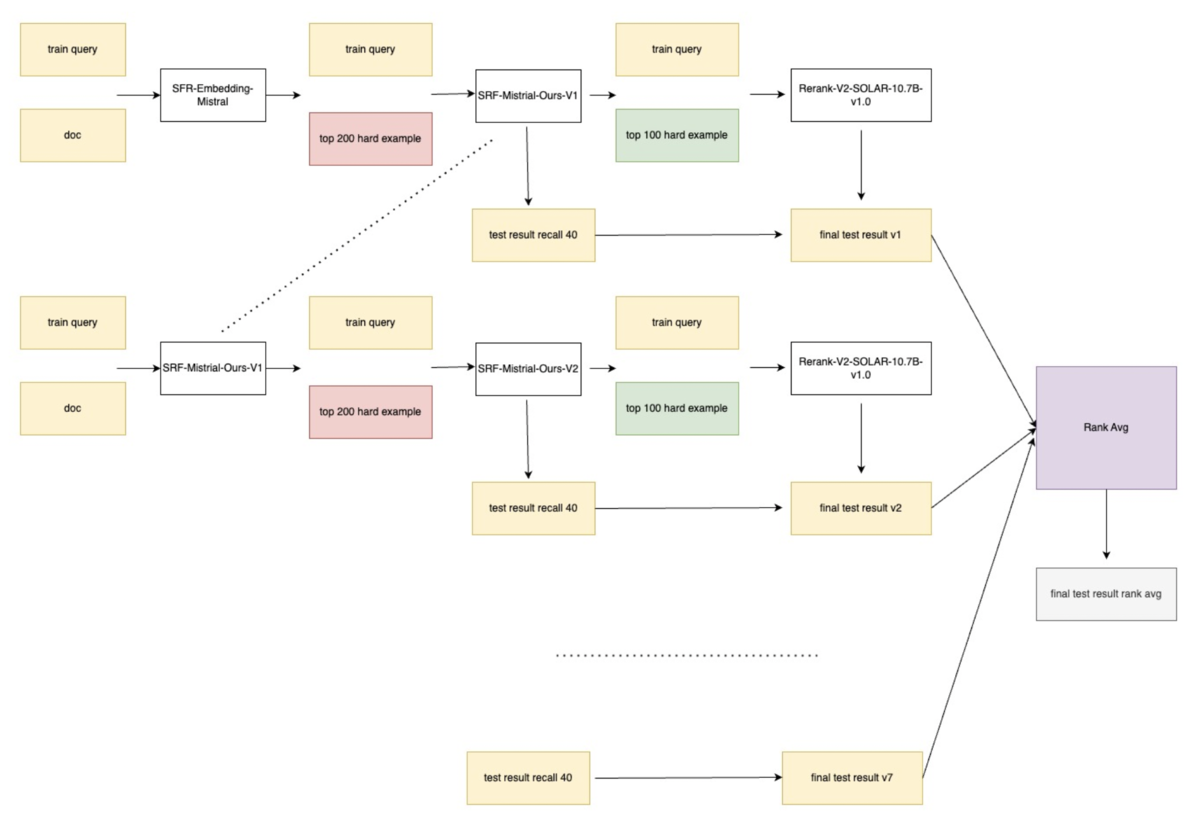
優勝解法を実行するには、GPU A100(80GBメモリ) を8枚備えたコンピュートリソースが必要で、実行完了するには約40時間かかるとのことでした。 近年のコンペでは、モデリング技術だけでなく、インフラ(主にGPUリソース)の実行環境も重要であることがわかります。
- 優勝チーム 論文 LLM-Based Iterative Hard Example Mining with Boosting for Academic Question Answering
- 優勝チーム GitHub
最後に
ドコモR&Dでは、KDDCUPのようなコンペにチャレンジできる風土と、コンペ参加時に利用可能なクラウド分析環境があり、今回の結果を得ることができました。この場を借りて感謝します。
また、KDDCUP2024参加を通して、対照学習やLLM技術など多く技術習得することができたため、これらの知見を今後の事業貢献活動に活かしていきたいと思います。
参考文献
[1] https://dl.acm.org/doi/10.1145/2959100.2959190
[2] https://blog.x.com/engineering/en_us/topics/open-source/2023/twitter-recommendation-algorithm