
NTTドコモ Advent Calendar 2024 10日目、Kaggle Advent Calendar 2024の12日目の記事です。
はじめに
NTTドコモ クロステック開発部 鈴木明作です!
こちらの記事では、地理空間分野のトップカンファレンスであるSIGSPATIAL 2024(シグスペーシャル)のワークショップとして開催された、人間の移動予測コンペHumob 2024(ヒューモブ) の上位3チーム解法を紹介します。 ドコモもHumob 2024に参加しており、ドコモの3位入賞解法 & アメリカ現地参加の様子は、別記事にありますのでそちらを参照ください。
国内外のデータ分析コンペ(Kaggleやatmacupなど)と異なり、学会コンペの上位解法が紹介されることは比較的に少ないと思いますので、アメリカ現地聴講と上位チームの論文をもとにHumob 2024の上位3チーム解法を紹介していきます。
Humob 2024コンペ概要
Humob2024のコンペ概要は以前の別記事に記載していますが、改めて簡単にコンペ概要を記載すると、お題は”複数都市における人間の未来の移動予測”です。
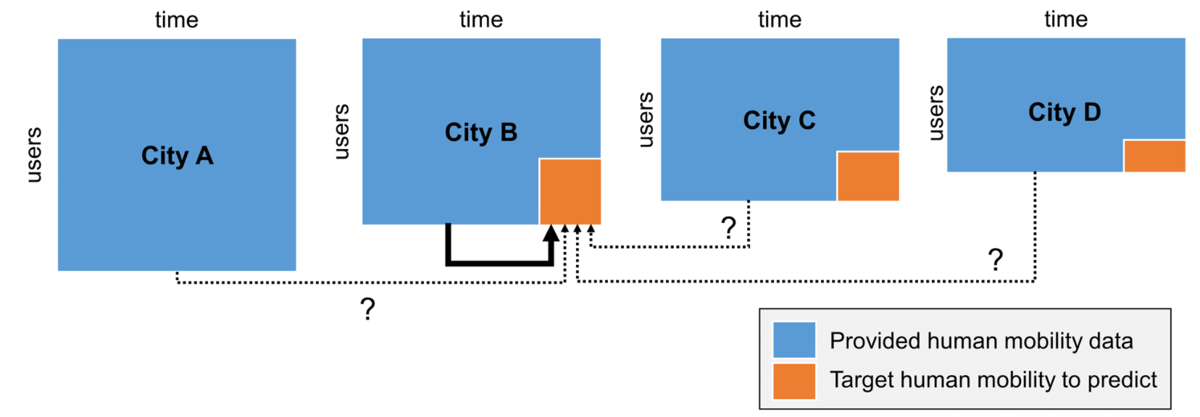
日本の4都市の位置履歴データセット*1が提供され、ユーザごとの過去60日間(1~60日目)の位置データから、未来の15日間(61~75日目)の位置予測を行います。
Humob 2024ではGEO-BLEU、DTWの2つの評価指標があり、それぞれで順位が決定されるため、2つの評価指標の上位3チーム(計:6チーム)の解法を紹介します。
評価指標
まずは、2つの評価指標であるGEO-BLEU、DTWを簡単に説明します。
評価指標1. GEO-BLEU
GEO-BLEU*2とは、自然言語分野の翻訳タスクで利用される評価指標であるBLEU*3を位置情報分野にも適用した評価指標です。 GEO-BLEUでは、BLEUと同様に2つの位置データ(正解位置と予測位置)のn-gramによる類似度を測りますが、BLEUとは異なり、正解位置と予測位置が完全一致していなくても近い位置を予測できればスコアが加算される特徴があります。 GEO-BLEUは値が高いほど予測が良好であることを⽰し、正解位置と予測位置が完全に⼀致する場合、GEO-BLEUは 1.0 になります。
GEO-BLEUは、地理空間上のn-gram(特定範囲内の連続した位置データ)での一致率を評価するため、位置予測における”局所的な評価指標”となります。
※ w_n : n-gramごとの重み、P_n : n-gram一致率、BP (Brevity Penalty) : 二つの系列長の違いを考慮するための補正項。数式の詳細は元論文*4を参照ください。
評価指標2. DTW
DTW(Dynamic Time Warping:動的時間伸縮)*5は、2つの系列データ同士の類似度を測る評価指標です。 DTWは地理空間データだけでなく、音声データをはじめとして様々な時系列データで利用されている評価指標です。 DTWは値が低いほど予測が良好であることを⽰し、正解位置と予測位置が完全に⼀致する場合、DTWは0.0になります。
DTWは、正解位置と予測位置の累積距離を評価するため、位置予測における"大局的な評価指標"となります。
GEO-BLEU論文*6を参考にすると、2つの時系列データ𝑋=[𝑥𝑖1,𝑥𝑖2,…,𝑥𝑖l], 𝑌=[𝑦𝑗1,𝑦𝑗2,…,𝑦𝑗l]があるとき、アライメント 𝑃 (2つの系列データの長さを揃える操作)のコストは、ペアごとの距離 の合計として計算されます。
このコストを使用して、DTW は以下のように最適なアライメント 𝑃 による最小コストとして表されます。 ここで、dは通常、2点間のユークリッド距離を使用し、最小コストは一般的に動的計画法により計算されます。
Humob 2024 上位3チーム解法の紹介
それでは、ここからGEO-BLEU部門、DTW部門の上位3チーム解法(論文名<所属チーム>)を紹介していきます。 上位チームの論文はHumob 2024のサイト*7からアクセスできます。
GEO-BLEU部門
1位. Time-series Stay Frequency for Multi-City Next Location Prediction using Multiple BERTs<名古屋大学チーム>
- 概要
- 昨年開催されたHumob 2023の優勝チームである名古屋大学チームの解法です。
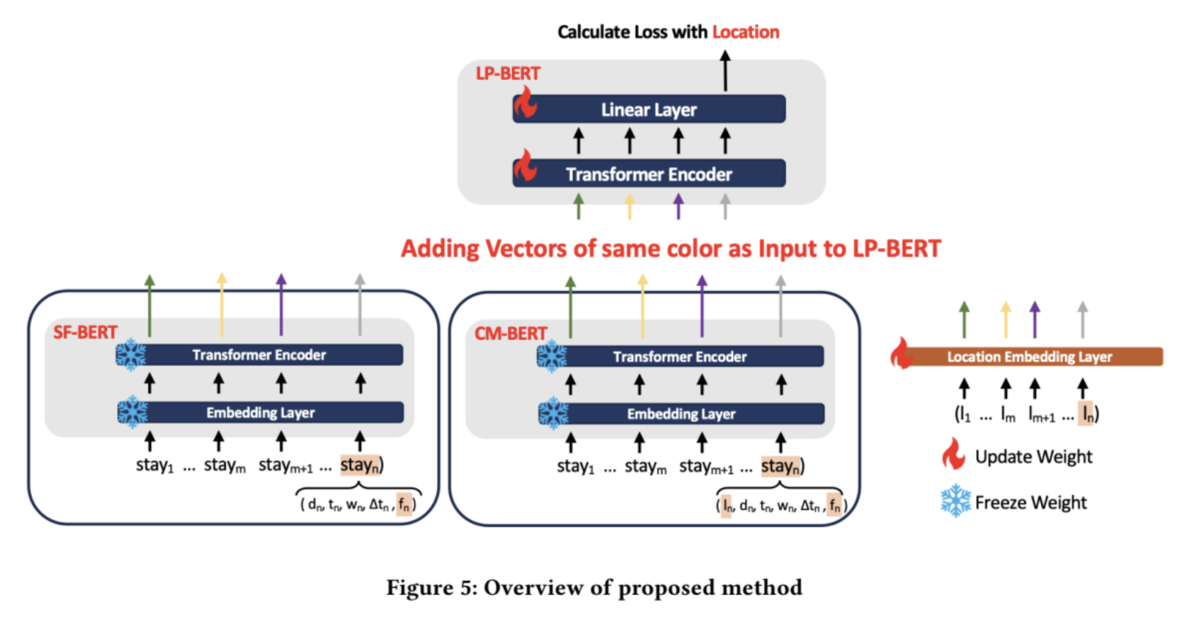
- 主にSF-BERT、CM-BERT、LP-BERTの3つで構成される解法です。
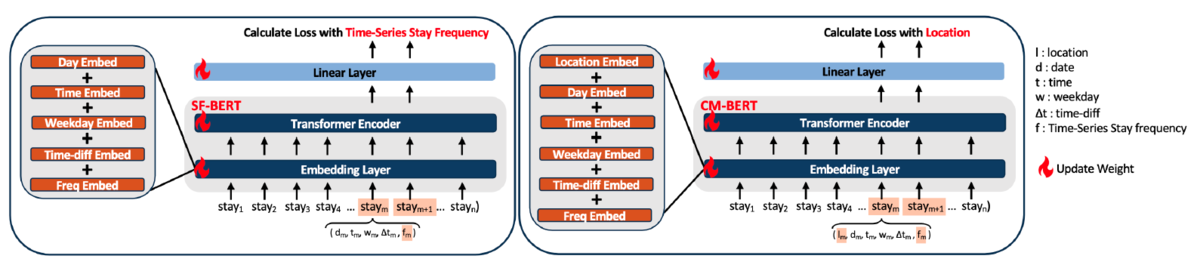
- SF-BERT(Time-Series Stay Frequency BERT):「滞在頻度」を予測するBERT
- 滞在頻度クラス、⽇付、時刻、曜⽇、滞在間の時間差をモデルに⼊⼒し、モデルはマスクされた連続する100件の「滞在頻度」から、「滞在頻度」を予測するように学習します。
- CM-BERT(City Movement BERT):「滞在位置」を予測するBERT
- 滞在位置、⽇付、時間、曜⽇、滞在間の時間差、滞在頻度クラスをモデルに入力し、モデルはマスクされた連続する100件の「滞在頻度」と「滞在位置」から、「滞在位置」を予測するように学習します。
- LP-BERT(Location Prediction BERT):「滞在位置」を予測するBERT
- SF-BERT、CM-BERT、位置埋め込み(Location Embedding Layer)の3つの出力の各次元(下図の同じ色の矢印同士)を加算してLP-BERTに入力し、モデルはマスクされた連続する15日間の「滞在頻度」と「滞在位置」から、「滞在位置」を予測するように学習します。
- SF-BERT(Time-Series Stay Frequency BERT):「滞在頻度」を予測するBERT
- 学習&推論方法
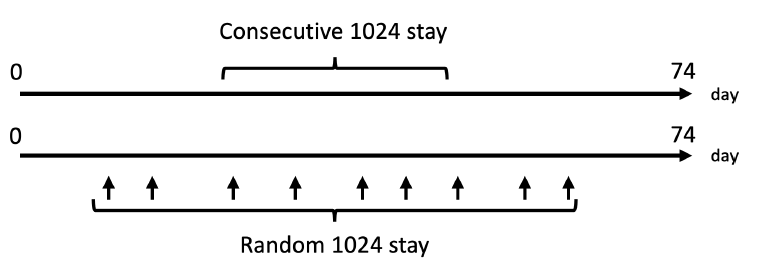
- まず、SF-BERTとCM-BERTを学習させます。SF-BERT、CM-BERTの学習時は、ユーザーごとに連続した移動軌跡(下図のConsecutive 1024 stay)と、ランダムに抽出された移動軌跡(下図のRandom 1024 stay)を学習データとして使用されます。連続した移動は短期的な移動傾向を捉え、ランダムに抽出された移動は⻑期的な移動傾向を捉えると期待されます。
- 次に、先ほど事前学習したSF-BERT、CM-BERTを使って、今度はLP-BERTを学習します。LP-BERT の学習中、事前学習したSF‑BERT、CM-BERTのパラメーターは更新しないようにします(Freeze weight)。SF-BERT、CM-BERT、LP-BERTの学習時の損失関数はクロスエントロピーです。
- SF‑BERTは、複数の都市にわたる大規模な移動履歴から学習した時系列の滞在頻度パターンを考慮して予測することで、学習データが不⼗分な都市で⽋落している移動傾向を補完することが期待され、CM-BERTはユーザー情報を⼊⼒として使⽤しないため、各都市の⼀般的な移動傾向を学習できるとのことです。
- 推論時は、学習済みのSF-BERT、CM-BERT、位置埋め込み(Location Embedding Layer)、LP-BERTを使って位置予測を行います。
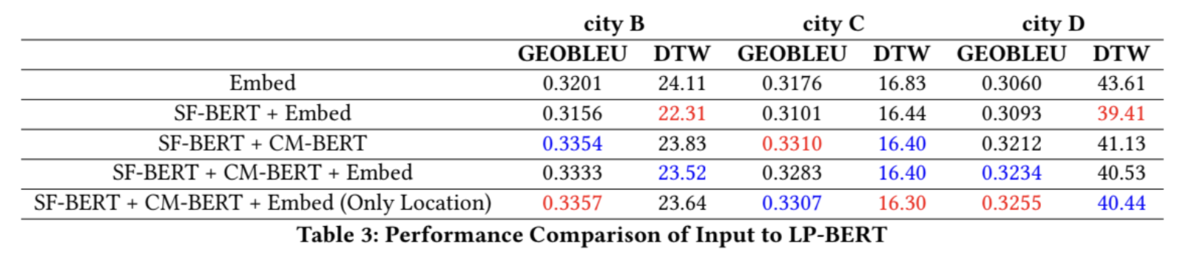
- 検証結果
- LP-BERTへの5つの入力パターンごとに検証スコアを⽐較しています。⾚色が各都市の最⾼スコアで、⻘色が2番⽬に良いスコアです。
- 評価実験の結果、 提案手法であるSF‑BERT、CM‑ BERT、LP‑BERTのモデルを全て組み合わせることで最高スコアとなっています。
2位. Instruction-Tuning Llama-3-8B Excels in City-Scale Mobility Prediction*8<東京大学チーム>
概要
- Llama-3-8B(Meta社が公開しているLLM)をInstruction-Tuningする"Llama-3-8B-Mob"を提案している解法です。
- GPT-3.5 / 4 APIによるzero shot推論を試したところAPI費用がかかるだけでなく良好な出力を得ることができなかったため、Llama-3-8Bを使ったInstruction-Tuningを行ったとのことです。
学習&推論方法
- 学習データセットからユーザの⼀部をサンプリングし、Q&AタスクとしてLoRA*9(LOW-RANK ADAPTATION)を使ったInstruction-Tuningを行っています。
- Llama-3-8B-Mobに入力するプロンプトは以下のように、指示プロンプト、ユーザごとの日付(学習時は0-74日)、時間(24時間×30分間隔=48)、位置x、位置y の4つの情報を入力して、日付、時間、位置x、位置yの4つを出力させるように学習させています。

Llama-3-8B-Mobへの入力プロンプト
検証結果
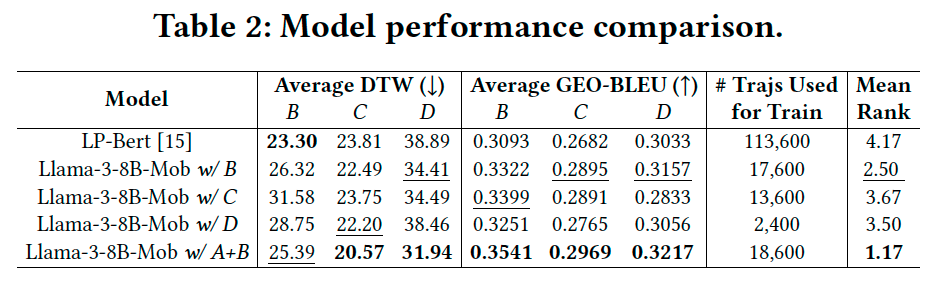
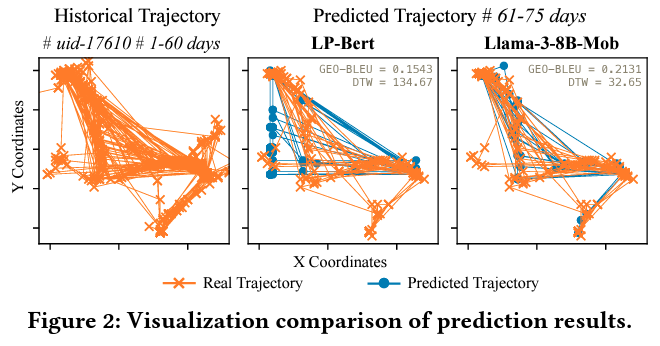
- 全都市City A~Dを学習したLP-BERTと Llama-3-8B-Mobを比較したところ、Llama-3-8B-MobのスコアがLP-BERTを上回っているとのことです(下図のTable2)。また、LP-BERTが苦手とする「規則ではない移動予測」においても、Llama-3-8B-Mobでは予測が出来ているようです(下図のFigure2のLP-BERT, Llama-3-8B-Mobの比較)
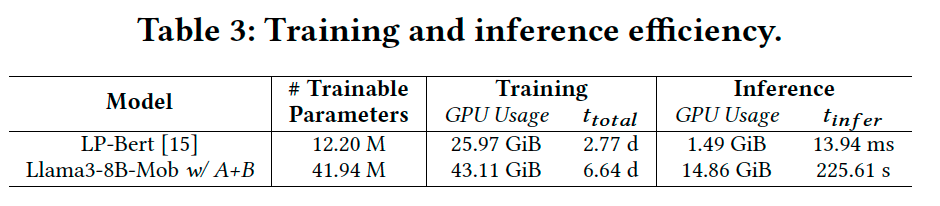
- 一方で、LP-BERT vs Llama-3-8B-Mobにおける、学習時と推論時のGPUメモリ使用量および計算速度を比較すると、例えばLlama-3-8B-Mobの推論速度はLP-BERTよりも16000倍を要するようです(下図のTable3。但し、LLM推論の高速化技術も発展しているため将来的には制約が緩和する可能性があるかと思います)
こちらのGithubにコードが公開されています。
3位. Cross-city-aware Spatiotemporal BERT<NTTドコモチーム>
NTTドコモチームの解法です。別記事にて解法の詳細を紹介しているため、ぜひそちらを参照してください。
DTW部門
1位. ST-MoE-BERT: A Spatial-Temporal Mixture-of-Experts Framework for Long-Term Cross-City Mobility Prediction*10<ノースイースタン大学チーム>
- 概要
- Mixture-of-Expertsを移動予測に適用した"ST-MoE-BERT"を提案した解法です。Mixture-of-Experts(MoE)は特定のタスクに特化したExpertを複数用意し、入力データに対してExpertを切り替えることで性能を上げる手法です。LLMのパラメータサイズを抑えながら、予測精度を向上をする手法として活用されています(例:Mistral AI社が公開しているMixtral 8x7Bなど)
- ノースイースタン大学チームのHumob 2024解法では、人間の移動は複数のパターンに分類されるという仮説から、移動パターンごとのExpertsを切り替えることで最適な予測を行っているようです。
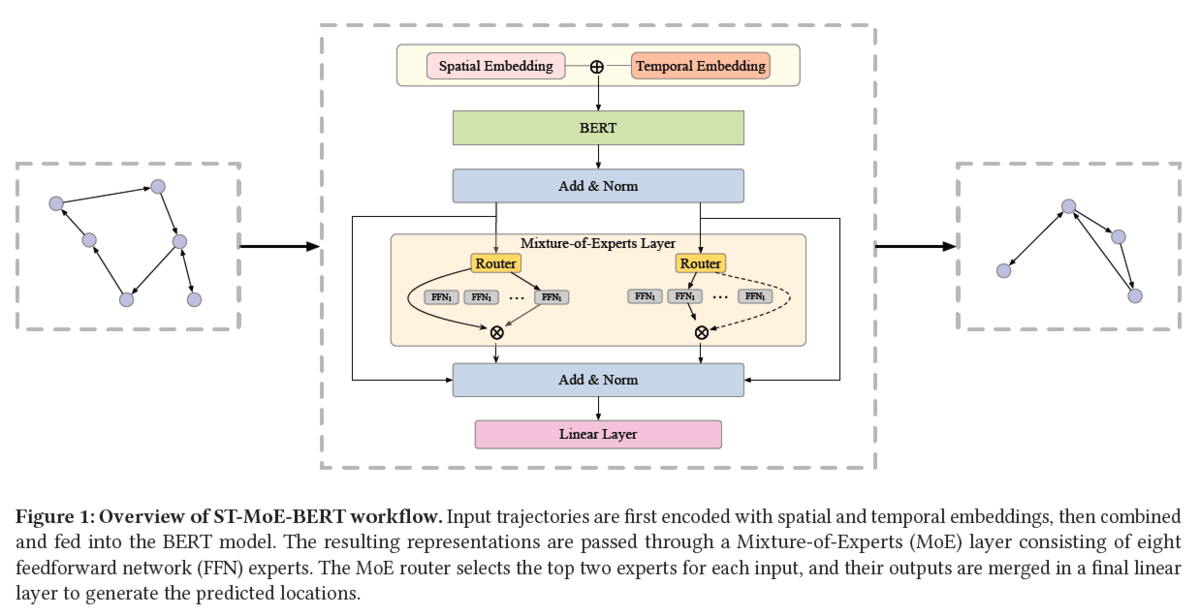
学習&推論方法
- まず過去位置履歴データを系列データに変換し、空間および時間埋め込み(上図のSpatial Embedding, Temporal Embedding)を結合してBERT モデルに入力されます。
- その後に、8 つの Expert(8 つのFeed-Forward Network:FFN)で構成される MoE Layerを通過します。
- MoE Layerでは、Routerが上位 2 つのExpertを選択し、それらの出力を最終的な線形レイヤーにマージして、位置予測を得ます。
- また、City Aで事前学習(マスク言語モデル:Masked Language Model)して、その後に各都市でファインチューニングする転移学習を行なっています。ファインチューニングの際に、位置埋め込みの学習率は10倍に設定することで都市固有のパターンを上手く学習できるとのことです。
検証結果
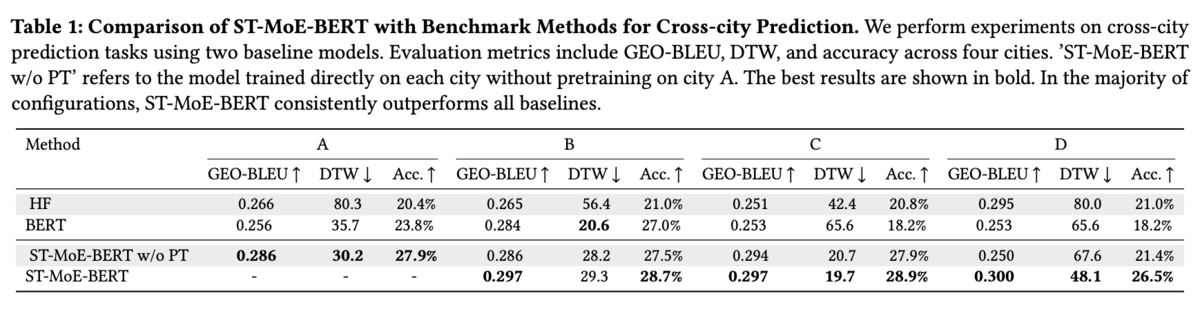
- 2つのベースラインである履歴頻度ルールベースHistorical Frequency (HF) & BERTと、提案手法である ST-MoE-BERTの合計3つの手法を比較しています。City Dを除いては、提案手法ST-MoE-BERTの予測スコアが優れていることがわかります。
- 転移学習では、City BのDTWを除いて事前学習済みST-MoE-BERTがGEO-BLEU & DTWで良好な結果となっています。
こちらのGithubにコードが公開されています。
2位. Urban Human Mobility Prediction Using Support Vector Regression: A Classical Data-Driven Approach<株式会社ARISE analyticsチーム>
概要
- 古典的な機械学習手法であるSVR(Support Vector Regression)を用いた解法です。
- 他チームの上位解法であるTransformer系とは異なり、計算リソース&計算時間の短縮が狙え、解釈性も向上する手法であり、実運用の観点でも有用と考えれます。
学習&推論方法
- 前処理
- コンペデータには欠損値が多くあるため、線形補間(Linear Interpolation)により欠損値補完しています。前時間の観測位置と次時間の観測位置の間に、欠損がN時間以上続く場合(Nは8~12時間に設定することで最も高い予測精度が得られるとのこと)に欠損補完しています。
- 特徴量エンジニアリング
- 主に、時間特徴量(「日付と時刻」「活動時間」「曜日」「平日か祝日か」「午前か午後か」)と移動特徴量(「移動回数」「平均移動距離」「移動距離の標準偏差」「平均移動角度」)の2つの 特徴量を作成しています。
- モデリング
- 非線形カーネルを用いたSVRを使って学習&予測を行います。
- ルールベースや、勾配ブースティング木などの機械学習手法を試した結果、非線形カーネルを用いたSVRが最も高い予測精度を示したとのことでした。
- 前処理
- 検証結果
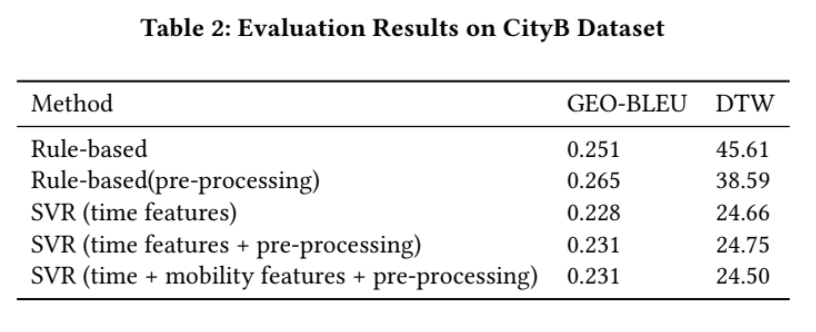
- ルールベースとSVRを前処理と特徴量エンジニアリングの有無でスコアを比較しています。
- 前処理と特徴量エンジニアリングによるSVRでDTWが良好になっています。
3位. Instruction-Tuning Llama-3-8B Excels in City-Scale Mobility Prediction<東京大学チーム>
GEO-BLEU部門2位チームがDTWでも3位になっており、LLM解法の汎用性がわかります。 解法は上記に記載済みのため、省略します。
最後に
Humob 2024では、古典的な機械学習手法〜最先端であるLLMを使ったアプローチまで、多様な解法が上位チームで使われていました。
これまでに学会コンペに馴染みがない方も、問題設定や上位解法から、ぜひ学会コンペのイメージを掴んでもらえれば幸いです。
※ 本記事執筆時点でarxivなどに個別に論文が公開されている場合は論文名にリンクを貼っています。
※ 論文掲載のGEO-BLEU & DTWスコアは検証データ(オフライン評価)によるものですが、検証データの作り方はチームによって異なるため、チーム同士のスコア比較ができないことに注意です。
*1:https://nttdocomo-developers.jp/preview#f-7d141fc1
*2:https://dl.acm.org/doi/10.1145/3557915.3560951
*3:https://dl.acm.org/doi/10.3115/1073083.1073135
*4:https://dl.acm.org/doi/10.1145/3557915.3560951
*5:https://link.springer.com/book/10.1007/978-3-540-74048-3
*6:https://dl.acm.org/doi/10.1145/3557915.3560951
*7:https://wp.nyu.edu/humobchallenge2024/workshop-schedule/
*8:https://arxiv.org/abs/2410.23692