
はじめに
こんにちは。NTTドコモ データプラットフォーム部所属の髙橋です。 我々データ基盤のチームでは、一元的にKPI指標を定義でき、自然言語での問い合わせが可能になるセマンティックレイヤーの導入に力を入れています。 なぜなら、社内では「このサービスの売上高はどうやって抽出すればいい?」←→「こういう定義で抽出して」といった会話の往復をSlack上でよく目撃し、データ活用に関わる全ての人を、こういった会話から解放したい、本質的な業務に専念できる環境を整えたいという思いがあるからです。
セマンティックレイヤーは、指標定義の統一とSQLへの意味の付与を実現し、SQLを知らない人でも自然言語でデータにアクセスできる環境を提供します。これは、データ活用の裾野を広げ、組織全体で「定義の不一致による議論」から解放され、本質的な分析に集中できる世界をつくるために不可欠な技術です。
Semantic Viewの課題
セマンティックレイヤーの主な候補に挙がっている製品はSnowflakeのSemantic Viewです。社内でSnowflakeを使っているため、指標定義の統一のプラットフォームとしては申し分ありません。一方で自然言語での問い合わせが可能になる点については、Semantic ViewはCortex Analyst経由で使わないといけない点で、2つの社内課題があります。
社内課題1: 大規模利用を想定した場合にコストハードルが高い
セマンティックレイヤーの機能として「自然言語での問い合わせが可能になる」点は非常に魅力的です。SnowflakeのSemantic ViewはCortex Analyst経由でこの機能を提供しており、技術的な障壁は低いものの、当社が想定する全社数千人規模でのデータ活用を見据えた場合、コスト面で導入のハードルが高くなると考えました。
自然言語で問い合わせできるという体験は非常に革新的ですが、数千に及ぶユーザーが日常的にクエリを実行する状況においては、ランニングコストが無視できない検討事項となります。探索的な分析を行うとなれば、数多くのクエリを実行することもよくあることでしょう。Snowflakeから提供されている料金表(2025/12/8時点)に記載されていますが、Cortex Analystは1,000メッセージ当たり67クレジットの料金が掛かります。利用するクラウドプラットフォームとそのリージョン、及び料金プラン次第ですが、1回問い合わせ当たりのコストは、$0.14~$0.38程度は掛かると推定されます。数千人が(全てのクエリではないにせよ)日々のクエリ実行をCortex Analystで行うとすると、相当な金額になることは想像に難くありません。
社内課題2: ロール単位でCortex利用権限が管理されている
こちらも同じく社内都合ですが、組織毎にロールが分かれていること、Cortexの利用権限はロール毎に管理されていることから、Cortexを全社的に使うことは難しい状態です(デフォルトでは利用権限なし。申請ベースで権限開放)。
実際のところ「Cortex?なにそれおいしいの?」という部署もたくさんあります。データ分析以外にも日々たくさんの業務を抱えている方々にとって、Cortexにキャッチアップして、さらにはCortexを利用するための社内申請フローを見つけるとなると到底辿り着けるものではない、というのが正直なところです。
課題解消のために
KPI指標定義の管理場所としてだけでもSemantic Viewは役に立つものと思われますが、せっかくYAMLファイルにコンテキストを埋め込めるのであれば、自然言語で問い合わせできる環境も整えたいものです。
そこでCortex Analystを経由せずに自然言語でSemantic Viewにアクセスできるかを以下の手順で検証してみました。
- Semantic Viewを作成する
- Semantic Viewに自然言語で問い合わせできるアプリを作る
- StreamlitでUIを作る
- LLMのAPIをアプリに組み込む
- Semantic ViewのYAMLをシステムプロンプトに組み込む
- アプリから自然言語で問い合わせる
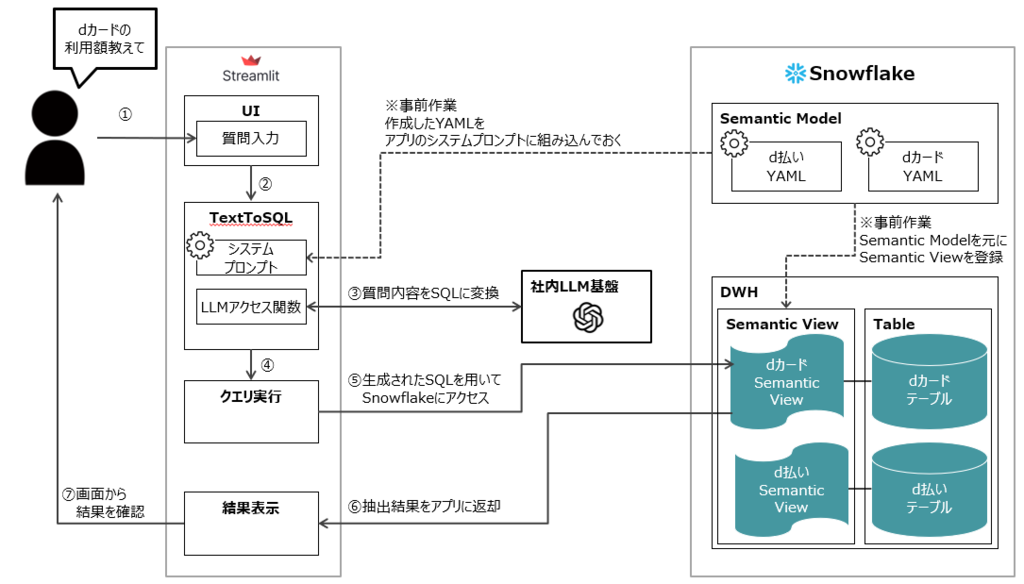
作成したStreamlitアプリの構成図
実装
Semantic Viewを作成する
- テーブルを作成する
今回はQRコード決済サービスの「d払い」とクレジットカードサービスの「dカード」、それぞれの地域別の利用金額を算出するというテーマにしてダミーのデータを作ってみたいと思います。
基本的には利用年月日、顧客ID、利用都道府県、利用金額という構成とし、自然言語での問い合わせの難易度を上げるために以下の設定を加えます。- 個別のカラムを追加する
- d払いテーブル: 年代を追加する(
10代以下,20代,30代, ・・・) - dカードテーブル: カードグレードを追加する(
REGULAR,GOLD,GOLD U,PLATINUM)
- d払いテーブル: 年代を追加する(
- 利用都道府県の構成規則を変える
- d払いテーブル: 利用都道府県に都道府県番号をつける(
01_北海道,02_青森, ・・・) - dカードテーブル: 利用都道府県に都道府県番号をつけない(
北海道,青森, ・・・)
- d払いテーブル: 利用都道府県に都道府県番号をつける(
- 個別のカラムを追加する
※重ねてになりますが、データはダミーで作成したものです。ドコモの内部情報に基づいて作成されたものでもなければ、いかなる内部情報を示すものでもありません。
Semantic Viewを作成する
LLMのヒントになるよう、ふんだんにsynonymsとdescriptionが盛り込んでSemantic Viewを作成しました。LLMに確実に理解してほしい内容については、descriptionにコード値の例を書いたり、verified_queriesの中にSemantic Viewを使ったクエリの実例を示したりしました。例えばd払いとdカードで構成規則が異なる利用都道府県では、descriptionとverified_queriesの両方で、利用都道府県の使い方が異なることを強調しています。descriptionでの指示では具体例と構成規則の両方を明記
d払いの場合
description: 購入者の都道府県(例:"01_北海道","24_三重","47_沖縄")。注意:都道府県番号_都道府県名で構成
dカードの場合
description: 購入者の都道府県(例:"北海道","三重","沖縄")。注意:都道府県名のみで構成verified_queriesでの指示では実際の使い方を明記
d払いの場合
AND ph.prefecture = '24_三重'
dカードの場合
AND ph.prefecture = '三重'
作成したYAMLを以下に掲載します。
d払いSemantic ViewのYAML
name: SEMANTIC_VIEW_DBARAI_PURCHASE_HISTORY
description: d払い購入履歴のセマンティックビュー
tables:
- name: PH
synonyms:
- d払い購入履歴
- d払い利用履歴
description: d払いの購入履歴明細
base_table:
database: [DB_NAME]
schema: [SCHEMA_NAME]
table: DBARAI_PURCHASE_HISTORY
dimensions:
- name: AGE_GROUP
synonyms:
- 年代
- 年齢層
description: 購入者の年代(例:"20代","60代")。
expr: AGE_GROUP
data_type: VARCHAR(10)
- name: PREFECTURE
synonyms:
- 地域
- 都道府県
description: 購入者の都道府県(例:"01_北海道","24_三重","47_沖縄")。注意:都道府県番号_都道府県名で構成
expr: PREFECTURE
data_type: VARCHAR(50)
- name: PURCHASE_DATE
synonyms:
- 購入日
- 日
- 利用日
description: 購入が発生した日付。日次集計に利用
expr: PURCHASE_DATE
data_type: DATE
- name: PURCHASE_MONTH
synonyms:
- 月
- 購入月
- 利用
description: 購入が発生した日付をDATE_TRUNCによる月初日で表現。月次集計に利用
expr: DATE_TRUNC('MONTH', PURCHASE_DATE)
data_type: DATE
facts:
- name: PURCHASE_AMOUNT
synonyms:
- 購入金額
- 利用金額
description: 1取引の購入金額
expr: PURCHASE_AMOUNT
data_type: NUMBER(10,0)
access_modifier: public_access
metrics:
- name: TOTAL_PURCHASE_AMOUNT
synonyms:
- 購入金額合計
- 利用金額合計
description: 対象ディメンションでの購入金額合計
expr: SUM(PURCHASE_AMOUNT)
access_modifier: public_access
verified_queries:
- name: 2025年6月の三重県での40代のd払い利用金額を教えて
question: 2025年6月の三重県での40代のd払い利用金額を教えて
sql: |-
SELECT
total_purchase_amount
FROM
SEMANTIC_VIEW(
SEMANTIC_VIEW_DBARAI_PURCHASE_HISTORY METRICS ph.total_purchase_amount DIMENSIONS ph.prefecture,
ph.age_group,
ph.purchase_month
WHERE
ph.purchase_month = '2025-06-01'
AND ph.prefecture = '24_三重'
AND ph.age_group = '40代'
);
use_as_onboarding_question: false
dカードSemantic ViewのYAML
name: SEMANTIC_VIEW_DCARD_PURCHASE_HISTORY
description: dカード購入履歴のセマンティックビュー
tables:
- name: PH
synonyms:
- dカード購入履歴
- dカード利用履歴
description: dカードの購入履歴明細
base_table:
database: [DB_NAME]
schema: [SCHEMA_NAME]
table: DCARD_PURCHASE_HISTORY
dimensions:
- name: CARD_GRADE
synonyms:
- カードグレード
- グレード
description: 購入者のカードのグレード。グレードはREGULAR(レギュラー), GOLD(ゴールド), GOLD U(ゴールドU), PLATINUM(プラチナ)がある
expr: CARD_GRADE
data_type: VARCHAR(20)
- name: PREFECTURE
synonyms:
- 地域
- 都道府県
description: 購入者の都道府県(例:"北海道","三重","沖縄")。注意:都道府県名のみで構成
expr: PREFECTURE
data_type: VARCHAR(50)
- name: PURCHASE_DATE
synonyms:
- 購入日
- 日
- 利用日
description: 購入が発生した日付。日次集計に利用
expr: PURCHASE_DATE
data_type: DATE
- name: PURCHASE_MONTH
synonyms:
- 月
- 購入月
- 利用
description: 購入が発生した暦月(DATE_TRUNCによる月初日で表現)。月次集計に利用
expr: DATE_TRUNC('MONTH', PURCHASE_DATE)
data_type: DATE
facts:
- name: PURCHASE_AMOUNT
synonyms:
- 購入金額
- 利用金額
description: 1取引の購入金額
expr: PURCHASE_AMOUNT
data_type: NUMBER(10,0)
access_modifier: public_access
metrics:
- name: TOTAL_PURCHASE_AMOUNT
synonyms:
- 購入金額合計
- 利用金額合計
description: 対象ディメンションでの購入金額合計
expr: SUM(PURCHASE_AMOUNT)
access_modifier: public_access
verified_queries:
- name: 2025年4月、三重県、プラチナカードでのdカード利用金額を教えて
question: 2025年4月、三重県、プラチナカードでのdカード利用金額を教えて
sql: |-
SELECT
sv_1.total_purchase_amount
FROM
SEMANTIC_VIEW(
SEMANTIC_VIEW_DCARD_PURCHASE_HISTORY METRICS ph.total_purchase_amount DIMENSIONS ph.prefecture,
ph.card_grade,
ph.purchase_month
WHERE
ph.purchase_month = '2025-04-01'
AND ph.prefecture = '三重'
AND ph.card_grade = 'PLATINUM'
) AS sv_1;
use_as_onboarding_question: false
Semantic Viewに自然言語で問い合わせできるアプリを作る
- StreamlitでUIを作る
検証目的ですので、特に画面を作りこむことはせず、迅速にアプリ化を試せるStreamlitを使いました。 インターフェースはシンプルに構成し、入力ボックスと実行ボタンだけを設けました。
実行ボタンを押すと、入力内容とシステムプロンプトをLLMに投げてクエリを作成し、そのクエリをSnowflakeに投げる構成になっています。 実行後は作成されたクエリとクエリの実行結果を画面に表示します。
- LLMのAPIをアプリに組み込む
LLMのAPIは、社内で整備された基盤を通じて利用しました。(利用モデルはGPT-4.1)
ベースのシステムプロンプトは以下の通りです。
利用者の質問に応じてSnowflake Semantic View用のSQLを生成してください。以下の要件を満たしてください。 ・出力結果をそのままSnowflakeで実行したいので、SQLのみを出力してください。 ・クエリ部分を「```sql」「```」で囲わないようにしてください。
- Semantic ViewのYAMLをシステムプロンプトに組み込む
ベースのシステムプロンプトに加えて、Semantic ViewのYAMLに記載した内容をシステムプロンプトの一部としてそのまま追加しました。
システムプロンプトは合計で4,000トークン程度です。
アプリから自然言語で問い合わせる
- 質問1: 「滋賀県での2025年6月の30代のd払い利用金額を教えてください」
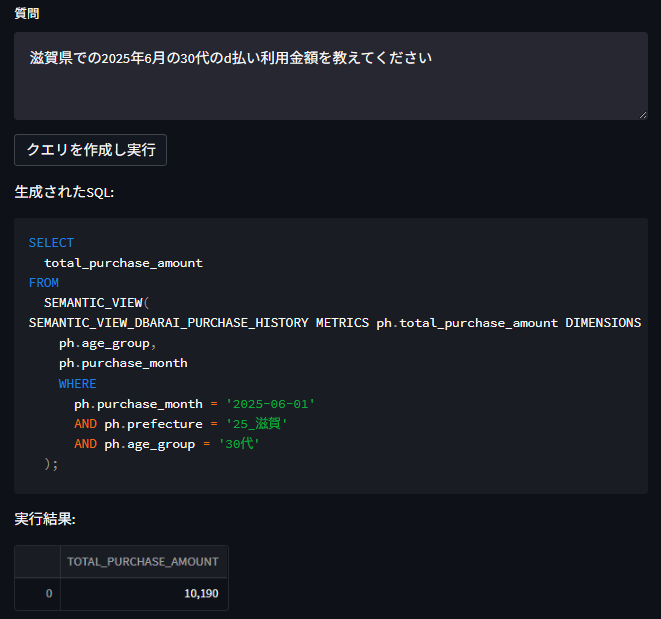
質問1と作成されたクエリ及び抽出結果
きちんとd払いのSemantic Viewを使ってクエリが生成されました。
また、Semantic ViewのYAML上では、都道府県のコードの例として「01_北海道,24_三重,47_沖縄」しか与えていませんが、都道府県番号を推測して25_滋賀とWHERE句に埋め込んでいます。
- 質問2: 「先月の東北のdカード利用金額を県別・グレード別に取得して並べ替えてください」
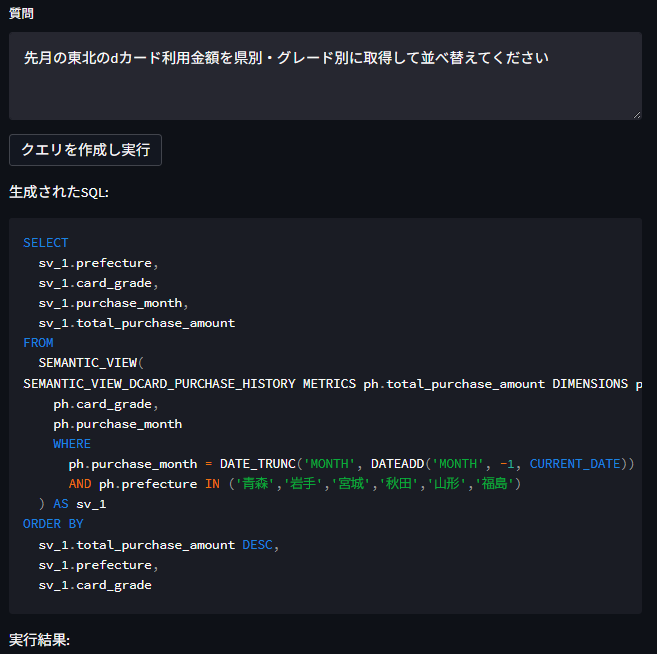
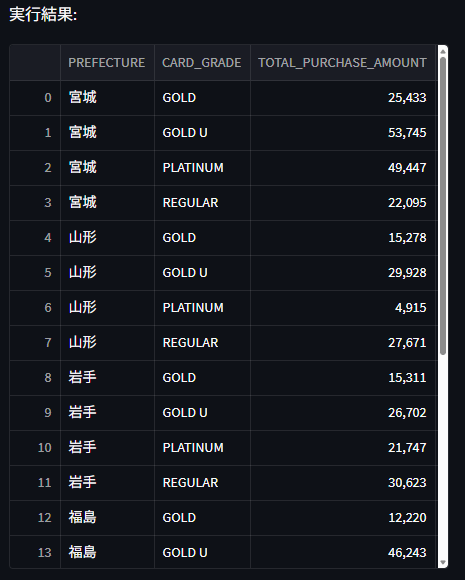
「先月」という単語をCURRENT_DATEから1ヶ月前(の月初)と適切に解釈し、「東北」という抽象的な単語から具体的に東北6県が指定されました。また、d払いと異なり都道府県のカラムには都道府県番号は付かず、都道府県名のみで構成していますが、WHERE句内の都道府県の指定の仕方も合っています。
結果と今後
自然言語でKPI指標をSnowflakeに問い合わせし、結果を得ることができました!
特に今回の検証で重要だったのは、Snowflake Semantic ViewのYAML定義をLLMに与えることで、指標の定義が統一された正確なText-To-SQLが生成された点です。
複雑なカラム名と値の解釈: 「d払い」と「dカード」で都道府県の構成規則が異なるという複雑なケースに対し、YAML内の description や verified_queries のヒントをLLMが的確に読み取り、d払いでは
25_滋賀、dカードでは青森のように正しいWHERE句を生成できました。抽象的な問いへの対応: 「先月」「東北」といった抽象的な問いに対しても、LLMが時間軸や地理(東北6県)を正確に推論し、意図したSQLを生成できたことは、Semantic Viewのメタデータを用いたText-To-SQLのアプローチの妥当性を示唆しています。
LLMが正確にSemantic Viewの定義を理解したことで、誰もが迷わず、統一されたKPI指標を抽出できる世界に近づきました。
このやり方であれば、1回4,000トークン分程度の微々たるLLM API代しか掛かりません(OpenAIの公式HPから$0.01前後と推測されます(2025/12/8時点))。
1回当たりの実行コストは大幅に削減され、Snowflakeの最先端技術であるSemantic Viewの恩恵をコストの心配することなく全社に提供できます。
社内には、幸いStreamlitアプリをデプロイして全社で活用するための基盤であるPochi*1が整備されています。Pochiには幅広いLLMのAPIが用意されているので、今回作成したアプリの構成をそっくりそのまま正式にアプリ化できます。また社内の誰もがアクセスできる基盤なので、課題2で挙げたロールの壁も超えることができます。
Pochiを活用すれば、Semantic Viewを活用した本アプリを社内に広く提供することが可能です。今回はあくまで検証でしたが、今後は正式なアプリの開発と、dカード、d払い以外にも幅広いSemantic Viewの作成を進めたいと思います。
社内データ活用プラットフォームPochiとは
私たちDP部は社内のデータ民主化を目指し、StreamlitとGoogle Cloudで圧倒的に使いやすいデータ活用プラットフォームを開発・推進しています。このプラットフォームは、24年度は30万時間もの業務効率化を実現し、直近では5,000人以上の社員に利用が拡大しています。
ASCII.jp:NTTドコモ、Streamlit利用の“ポチポチ分析アプリ”開発で社内データ活用を促進 (1/3)
そしてデータ基盤を担当する身としては、アプリを通じてSemantic Viewの良さが伝わる → Semantic Viewが自発的に整備されていく/整備の協力者が増えるという好循環を生み出し、「指標定義の問い合わせ稼働・抽出稼働を削減し、本質的な業務に専念できる」という世界の実現を目指していければと考えています。
*1:Pochiは社内の開発コードネームです