
はじめに
こんにちは、データプラットフォーム部の鈴木明作です!
この記事では、データマイニング分野のトップカンファレンスであるKDD2025にて開催された、KDDCup2025 CRAG-MM Challengeの上位チーム解法を紹介します。
CRAG-MM Challenge
KDDCup2025として、Metaから、「VLM(Vision-Language Model)を用いたRAG(Retrieval Augmented Generation)によるハルシネーション抑止」をお題にしたCRAG-MM Challengeが開催されました。
ドコモでは、会社チームとしてCRAG-MM Challengeに参加しており、特別部門で2部門入賞することができ、カナダのトロントに現地参加し、弊社チームの発表と他の上位チームの発表を聴講してきましたので(現地参加の様子はこちらの記事を参照ください)、CRAG-MM Challengeの上位チーム解法を紹介していきます。
CRAG-MM Challengeは昨年KDDCup2024のCRAG Challengeに続き、2回目の開催で、KDDCup2024は、「テキストデータの質問におけるRAG検索のハルシネーション抑止したLLM回答」がお題でしたが、KDDCup2025では「テキストデータでの質問」から「マルチモーダル(画像)に対する質問」に変更されました。昨年のKDDCup2024 CRAG Challengeの上位チーム解法はこちらの記事をご覧ください。
CRAG-MM Challengeの問題設定
CRAG(Comprehensive RAG Benchmark)は、Metaが考案したRAGシステム評価のためのベンチマーク(評価方法)で、RAGシステムにおける多様な質問応答にどの程度正確に対応できるかを評価することが可能とされています。CRAG-MM Challengeでは、CRAGベンチマークを使って「画像に対する質問に回答するVQA(Visual Question Answering)タスク」を解く問題設定になります。
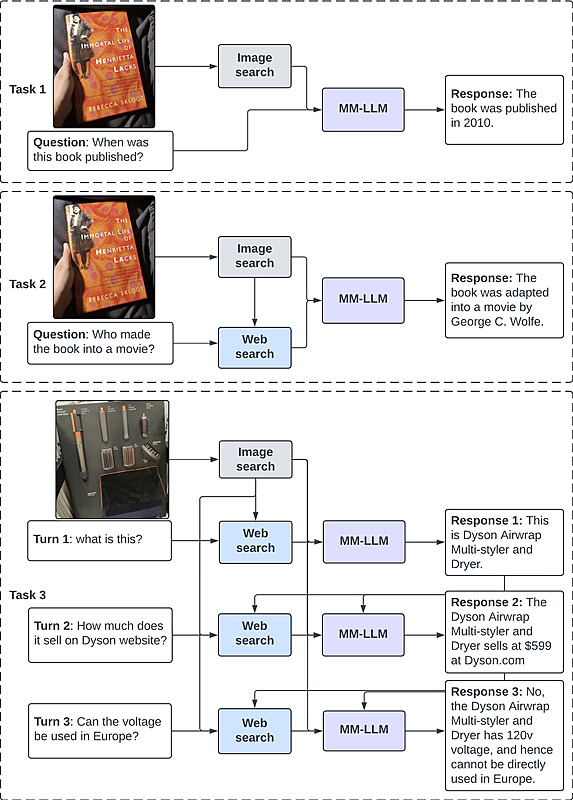
CRAG-MM Challengeは3つのTaskから構成されています。
- Task1.シングルソース RAG:画像APIを使って、類似画像を検索して画像および画像のメタ情報から質問に回答する。
- Task2.マルチソース RAG:画像API&テキストAPIを使って、画像およびテキストの外部情報を取得して質問に回答する。
- Task3.マルチターンQA RAG:画像API&テキストAPIを使って、画像およびテキストの外部情報を取得して、マルチターンでの質問に回答する。
また、すべてのTaskで以下のルールがあります。
- MetaからRAG検索APIが公開されており、参加者はこのAPIを使って外部情報を取得する必要がありました。
- VLMのモデルはMetaが開発したLlama 3.2 11B or Llama 3.2 90B系列、もしくは1.5B以下の他のVLMを使う必要がありました。
- その他にも、実行環境(GPU L40s 48GBの単一インスタンス)、推論時間、トークン数(VLM出力は75 トークン以上は切り捨て)などの複数の制約がありました。
CRAG-MM Challengeの評価方法
- 評価は、各質問に対する回答の以下のスコアの合計値で順位が決まります。大事なポイントは、”I don’t know”と回答すれば、不正解(-1)にならないので、評価スコアが下がらないことです。CRAG-MM Challengeでは非常に難しい問題が多かったため、上位チームの多くが、基本的には”I don’t know”と回答して、VLMの内部知識とRAG検索により回答できる質問にだけ回答する手法をとっていました(その結果、多くの上位チームが回答率20~30%程度でした)
- 正解(完璧な正解回答):1.0
- 許容範囲の正解(有用だが、軽微な間違いあり): 0.5
- 回答しない(I don’t knowと回答する):0.0
- 不正解(間違った回答または無関係な回答): -1.0
- 評価には3つのフェーズがあり、第1フェーズではLLM評価、第2フェーズでは第1フェーズからテストデータが更新されてLLM評価、最終フェーズでは人手の評価によって最終順位が決定されます。
- 3つのTaskにおいて、上位3チームと、特別部門でのスコアが最も高いチームが入賞となります。
余談ですが、2025年9月にOpenAIからハルシネーションに関する文書と論文が公開されており、ハルシネーションよりも棄却(回答しない)が望ましいと主張されています。
CRAG-MM Challengeの上位解法
- ここから本題の上位解法を紹介します。
- 記事執筆の2025年12月時点で、一部の論文しか公開されていないため、現地発表(口頭&ポスター)から筆者が理解した内容になります。今後の論文公開に伴い、上位解法について加筆修正する可能性があります。
北京大学チーム
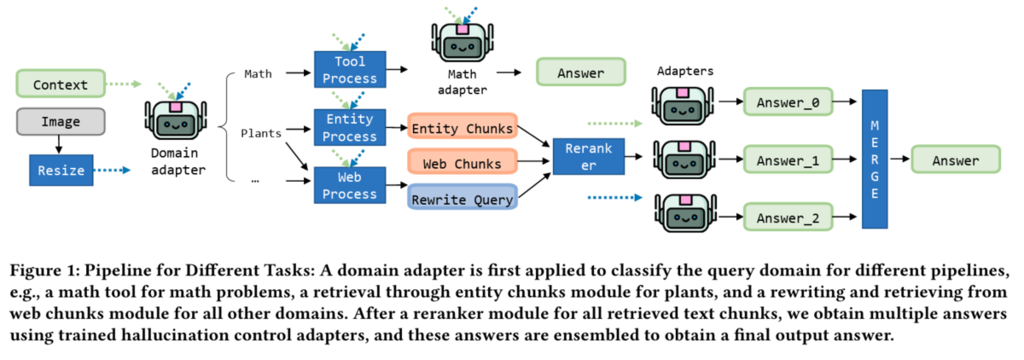
解法の概要
- ドメインルータ、カスタムRAG検索、教師あり学習(SFT)/DPO/GRPO学習、モデルマージなど、多数の工夫が含まれている解法です。
- VLMの学習では、SFT、DPO、GRPOによる、複数の学習手法を用いています。VLMには、「Llama 3.2 11B Instructが内部知識&RAG検索情報から回答できれば回答する。内部知識&RAG検索情報から回答できなければI don’t knowと回答する」という”回答パターン”を学習させます。データ作成では、Llama 3.2 11B Instructが質問に回答できれば正解ラベルとして、回答できなければ’I don’t knowを正解ラベルにするように、GPT APIなどで正解ラベルを生成します(蒸留の一種になるかと思われます)。コンペ主催者から提供されたコンペデータの正解ラベルをそのまま正解ラベルにするのでなく、新たに正解ラベルを作成して”回答できる or 回答できないパターン”を学習させる点がポイントでした(詳細はKDDCup2024上位チーム紹介記事のWinning Solution For Meta KDD Cup’ 24のFine-tuning欄を参照)。KDDCup2025の多くの上位チームにて同様の方法でVLM学習を行っていました。
- その他にも、検索クエリ書き換え、画像の解像度リサイズ、複数プロンプト&複数回評価による安定したローカル評価、なども行っていました。
チーム名:db3
順位:Task1の2位、Task2の2位、Task3の1位
論文:DB3 Team's Solution For Meta KDD Cup' 25
NVIDIAチーム
解法の概要
- マルチタスク学習や、独自評価ライブラリを使った解法です。
- RAGパイプラインにおける、検索クエリ書き換え(Query Rewrite)、リランキング(Re-ranker)、VQAの3つでVLMを使っており、VLMは、3つのタスクを一つのデータセットに結合してマルチタスク学習を行ったモデルを使っています。マルチタスク学習の実行環境はGPU A100×8枚とのことです。VQAの後処理として、VLMからの出力トークンが”I”となる出力確率値が閾値よりも高い場合には、I don’t knowを出すようにしているようです。
- 秘密兵器として、NVIDIAが開発したRAGに特化したオープンソース評価ライブラリである「NVIDIA RAGAS」を活用することで、最終評価である人手評価と相関する信頼性の高いローカル評価を行っていました。NVIDIAが自社で開発したライブラリであるNVIDIA RAGASをCRAG-MM Challengeの課題に落とし込んで活用している点が流石でした。
- GitHubでNVIDIA解法コードが公開されています。

チーム名:Team_NVIDIA
順位:Task2で1位
美団チーム①
解法の概要 ※美団は中国の大手食品デリバリー会社
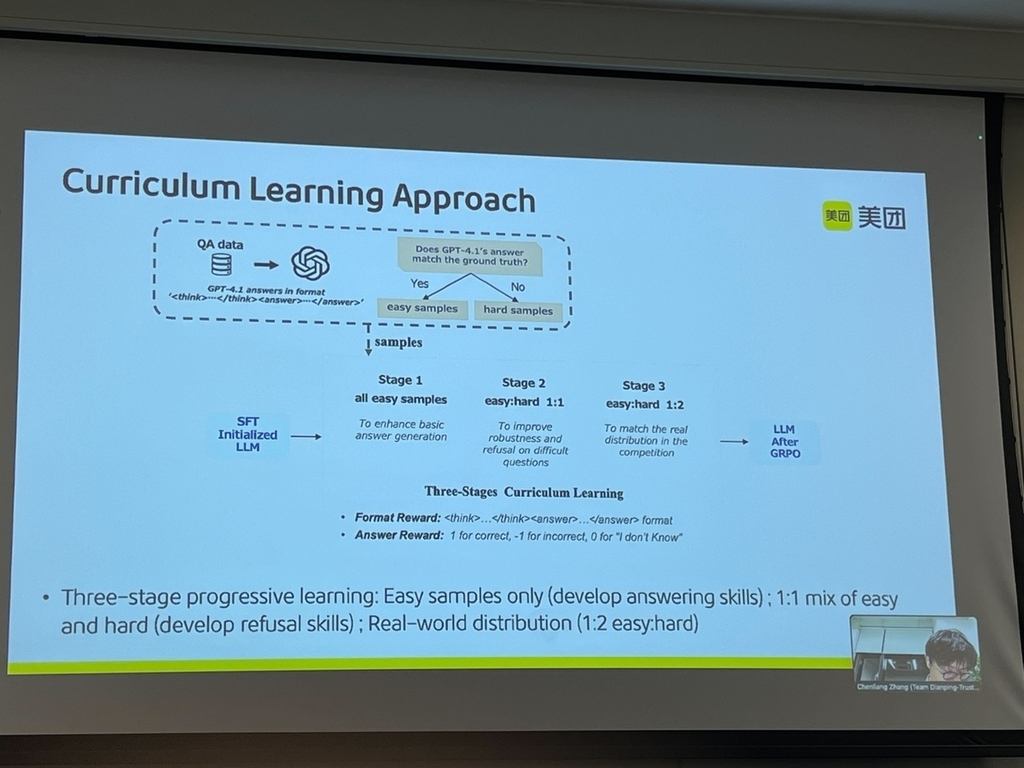
- SFT、カリキュラム学習(CL)、強化学習(RL)の3つで構成されている解法です。
- まず、CoT reasoningプロンプトによるSFTで学習を行います。
- カリキュラム学習では、stage1. 全て簡単な問題、stage2. 簡単な問題:難しい問題 の比率を1:1、stage3. 簡単な問題:難しい問題の比率を1:2にして学習(step by stepで学習)することで、精度向上に寄与したとのことでした。
- 強化学習では、VisualRFT付きのGRPO(少量の学習データでもマルチモーダル推論能力を強化学習する手法)で学習するとのことでした。
- Ablation studyスライドでは、SFT、RL、カリキュラム学習、RAGのそれぞれによるスコア向上効果がわかります。

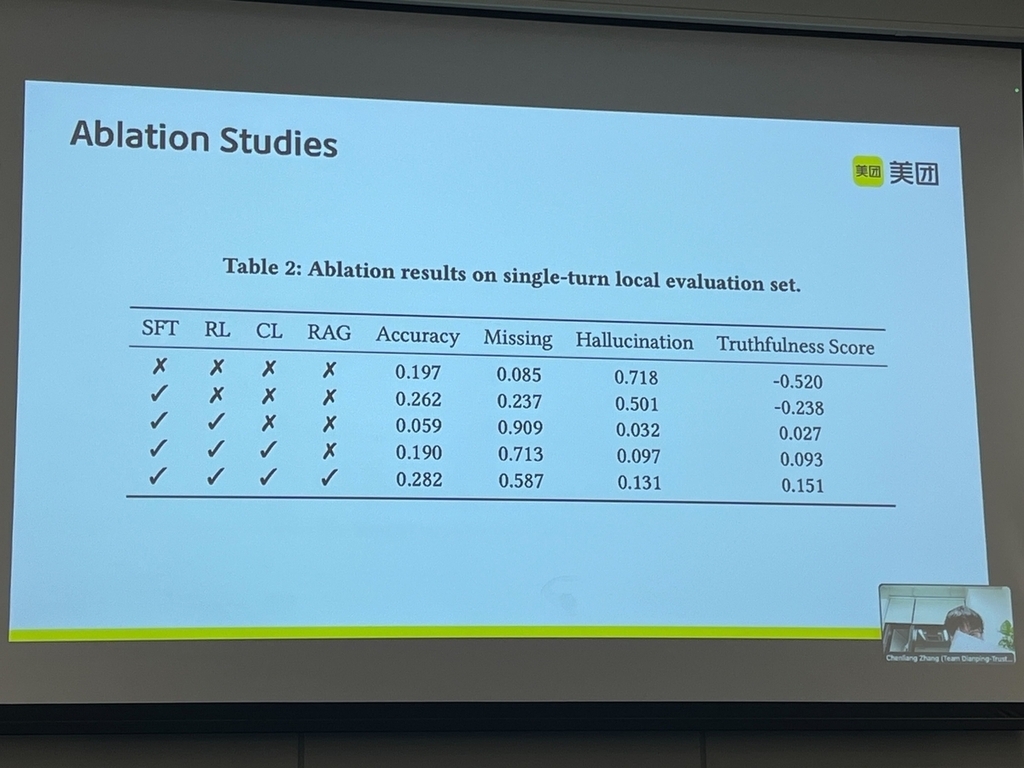
チーム名:Dianping-Trust-Safety
順位:Task1の1位、Task3の3位
美団チーム②
解法の概要
- マルチタスク学習やデータ拡張を使った解法です。
- NVIDIAチームと同様に、検索クエリ生成、リランキング、VQAの3つのデータを一つに統合してマルチタスク学習しています。
- ユニークな点として、Task1でのデータ拡張があります。データ拡張の方法としては、Llama 3.2 11B Instructで回答させて正解だった場合には、該当質問のサンプルに対するn個の類似ラベル(n=10)を生成・検証し、ハルシネーションになっていないかフィルタリングした上で、残った𝑚個のラベルは、元の質問と画像と共に、学習データに追加されます。
- Task2 & 3では、RAG検索結果に対してリランキング処理も追加しています。
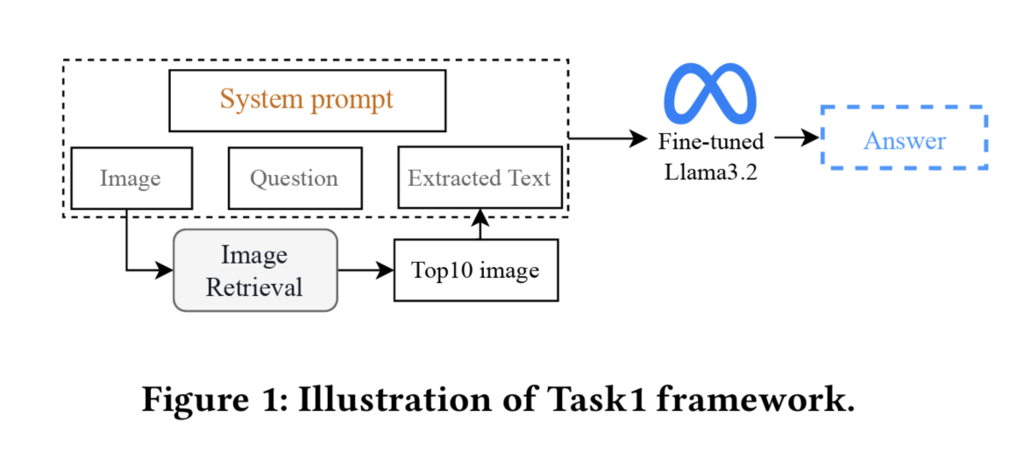
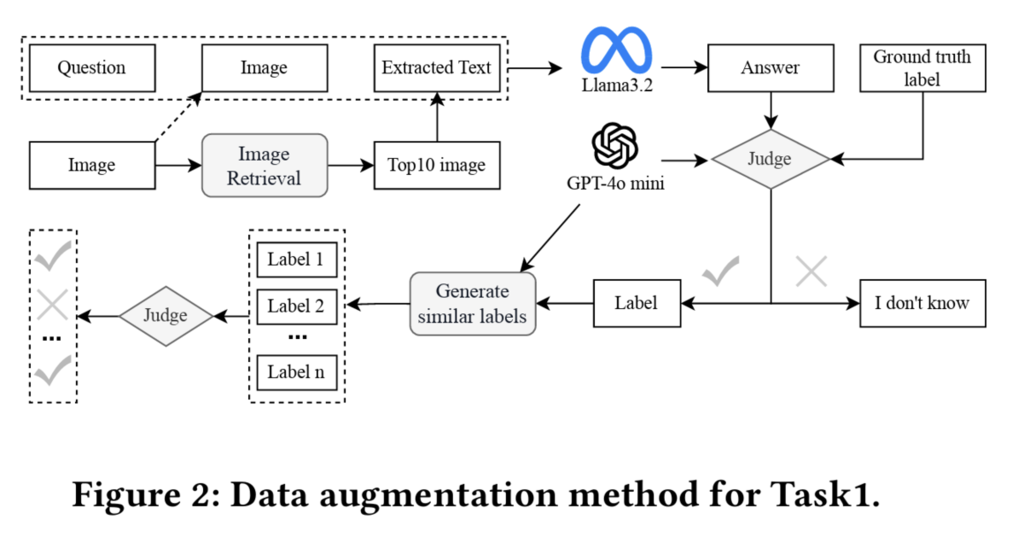
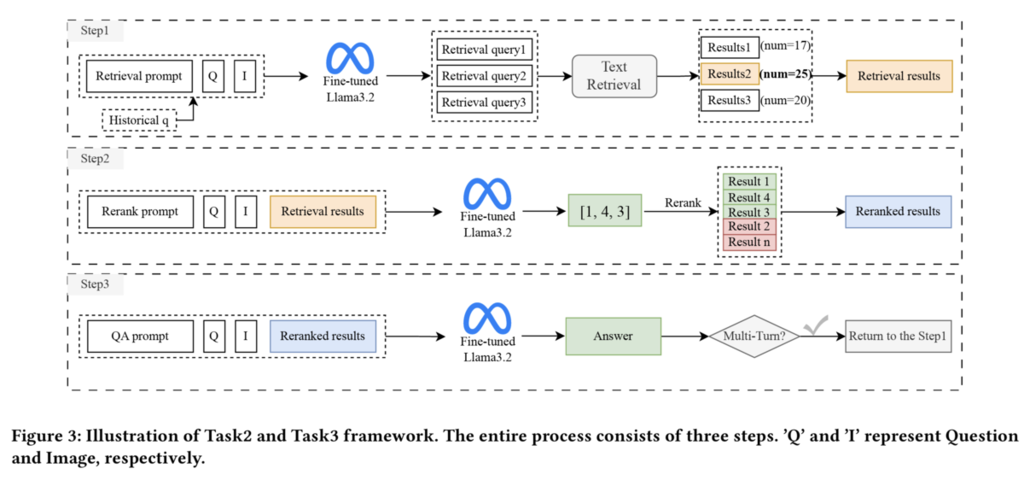
チーム名:blackperl
順位:Task3の2位
論文:Solution for Meta KDD Cup’ 25: A Comprehensive Three-Step Framework for Vision Question Answering
Acroquest Technologyチーム
解法の概要
- タスクごとに学習したモデルのLoRAアダプタの切り替えを行なう解法です。
- 検索クエリ生成、VQA、の2つのタスクについて個別でVLMの学習(QLoRA)を行い、推論時は、パイプライン上で、検索クエリ生成、VQAのLoRAアダプタを切り替えることで、推論時間制限内に収めて最終回答出力しています。検索クエリ生成のQLoRA学習を行う際には、検索クエリ生成専用の正解ラベルを用意するのではなく、VQAタスクでの最終的な回答を正解ラベルにすることで、精度向上したとのことでした。
- また、Qwen3-Reranker-0.6Bでリランキングを行うことで、RAG検索情報の品質を高めています。
- 現地発表では、精度向上には繋がらなかった試行実験として、DPO学習、画像のメタデータ活用、HTMLファイルのパースなどの説明もあり、論文を読むだけでは得られない学びもありました。

チーム名:YAMALEX
順位:Task2の3位
NTTドコモチーム
解法の概要
- ドコモ解法は別の記事にて公開予定のため、そちらを参照してください。
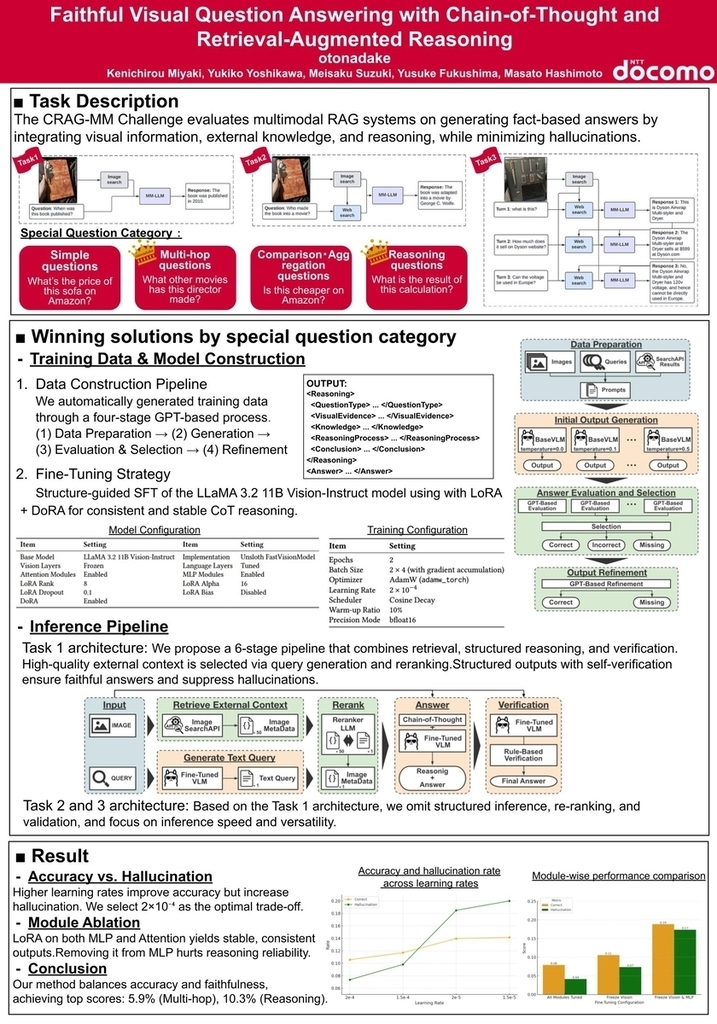
チーム名:otonadake
順位:Special Question Category WinnersのReasoning Question 、Multi-hop Questionの2部門で入賞
NECチーム
解法の概要
- 画像のオブジェクト抽出に焦点を当てた解法です。
- CRAG-MM Challengeデータセットには、画像のどのオブジェクトへの質問なのかが非常にわかりにくいサンプルも含まれていました。このため、画像セグメンテーションモデルであるBiRefNetで画像のROI(Region of Interest: 関心領域)を切り取ることで、質問に該当する画像の中のオブジェクトを強調し、質問に関係ない無駄な画像部分を排除して、VLMが回答しやすくなるように画像を整形しています。
- また、VLMは位置バイアスを持っていることが知られているため、VLMへの入力プロンプト設計を最適化することで、精度を向上させたとのことでした。
- その他にも、質問ドメインのルータにより特定ドメインの質問には回答せずにI don’t knowとする、VLM出力の75token以上は切り捨てるなどでスコアが向上したとのことです。

チーム名:NEC_AI_ROCKETS
順位:Special Question Category WinnersのSimple Question 部門で入賞
電気通信大学チーム
解法の概要
- VLMの内部表現(internal representation)を活用してハルシネーションを検出する解法です。
- VLM内部のレイヤー(hidden_state, attension_head)ごとの行列情報から、ロジスティック回帰でモデルがハルシネーションを起こすか予測し、最終的にロジスティック回帰予測結果をアンサンブルすることで、VLMの回答をそのまま最終回答とするか、I don’t knowとするかを決めています(質問に対するVLMの回答の自信の有無を、モデルの内部表現から判定するイメージになるかと思います)
- 他の上位チーム解法にある、VLMの学習やRAG検索情報は一切使っていないことが特徴で、とてもユニークな解法だと感じました。
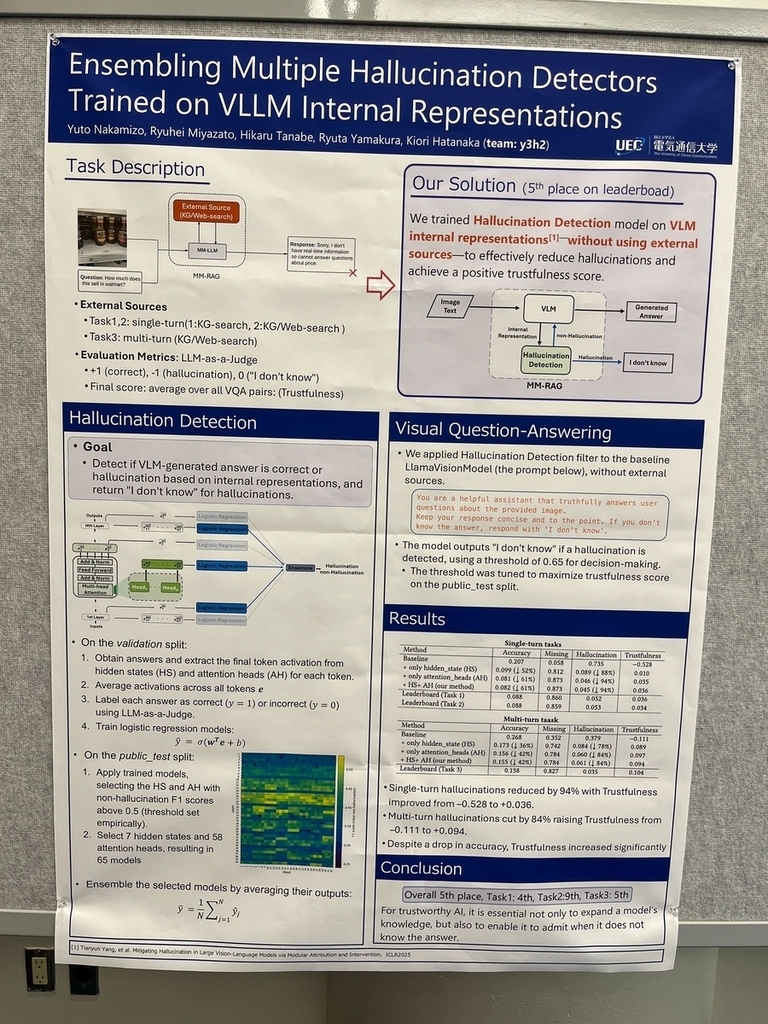
チーム名:y3h2
順位:第2フェーズでの総合順位5位
感想
- 多くの上位チームにおいて、学習データセット生成・学習・推論・評価(LLM as a judge)という全体パイプラインをすべてVLMで行っており、生成AI時代のデータ分析コンペの到来を改めて感じました。
- RAGのベストプラクティス(ドメインルータ、検索クエリ書き換え、リランキングなど)に加えて、CRAG-MM Challenge特有の解法となる、蒸留によるVLM学習、マルチタスク学習、LoRAアダプタ切り替えなどの発表があり、とても学びの多いコンペでした。