
はじめに
NTTドコモ クロステック開発部の福島&井手&小原&中村圭佑です。普段の業務では画像認識や生成AIに関する研究開発を行っています。今回は社内でVLMと画像生成が気軽に使えるシステムを作ってみたので紹介したいと思います。Slackをインターフェースとした比較的シンプルなシステムなのでぜひご覧ください。
開発の背景
目的は大きく分けて3つあります。
社内での生成系AIの普及とアイデア創出
この界隈にいるとLLMをはじめとした生成系AIの利用が当たり前な雰囲気を感じますが、現実はそうではないのです。R&Dや日常的にAIに触れている人間以外は「名前は知ってるけど使ったことない」や「なんか凄そうだけどそもそも何ができるか知らない」という認識の方が大半です。ドコモは業務効率化や新規サービス導入のために生成系AIの利用を促進しています。しかし弊社も例外ではなく技術的なコンテンツに触れることが少ない社員の大半は上記のような認識を持っています。新しいサービスや事業を作る上で詳細な機械学習のアルゴリズムを理解する必要はないと考えていますが(もちろん知っているに越したことはない)、普段の業務が忙しい方もいる中で簡単に使えてアイデア創出に繋がるシンプルなシステムが出来れば良いなと考えて開発することが決定しました。そして本社内ではSlackが標準装備されているため、こちらをインターフェースとしてAWSでシステムを実装することにしました。社内システム構築の障壁
- 推論時のインプットが学習される可能性がある問題
これは企業内で生成AIサービスを使うときにあるあるだと思うのですが、社員がInputしてしまった機密・機微情報をサービスプロパイダ側でモデルに学習されると非常に困るのですよね、、、。幸いAWSやAzure openAI serviceはそのような事態を回避するサービスを展開しておりますので、そちらを使用することにしました。 - 生成物のトレーサビリティの問題
こちらはとにかくシャドウITのような状態になるのを避けるため、誰がなんの情報をいつinputして何がoutputされたか?という情報を追えるようにしています。悪意ある使い方や問題が起きた時に証拠を残すためここら辺はガチガチに固めてます。また、Titan imageの生成物にはWatermark(電子透かし)が付与されています。社内で生成した画像が悪意ある使われ方をしていた場合、Titan imageでの生成物か判定することが可能となります。この機能はAIが生成したコンテンツの透明性を高めるのに役立ちます。加えて、さまざまな情報をまとめることで誰がどんなことに使っているのか?という点を分析するのにも使えるのかなぁと考えています。 - 社内システム構築が大変な問題
こちらもどの会社でもあるあるかもしれないですが、社内システムを作るのって諸々の申請・各所との調整・セキュリティ等様々なことを考慮しなければならず大変なんです。この大変さが原因で社員が勝手にパブリックな生成AIサービスを使い情報流出してしまう、、、なんてことがあるかも知れません。
それに全ての社員がクラウドやシステム設計・開発に関する知識を持っているわけではないため各部で生成AIを使える環境を用意するのも非現実的な話です。
これらの問題を避けるためにも予めR&D部門でサービスを提供して皆が使えるようになれば嬉しいですよね?(多分)
- 推論時のインプットが学習される可能性がある問題
サービス創出のフック
こちらが最大の目的ですね。社内には生成AIを使ったことない人が多数いるため、「まずは実際に使ってみる。」というところから始めてもらえればなと思います。使ってみなければどんなものか分からないですしね。そしてここから新規事業や新たなサービスに繋げて貰えれば良いな、、、との思いで作っています。
とまぁここまでは受け身でしたが、I/Oを全てデータベースとS3に保存しているため、社内でどんなものを生成しようとしているのか?どんな分野に対して使われているか?というのが開発者には分かるのです。このデータを分析することにより、R&Dから他の部にサービスの提案やサポートが出来ると考えています(こっちが本命)。 社内で生成AIを使ったサービスの開発したいよ〜という方がいたら、R&Dがこれをフックにして技術の研究開発やアドバイザリーに入れたら嬉しいですね。そしてどんどん論文投稿もしていきたいです。
使い方
Slackをインターフェースとして動かしてます。アーキテクチャの通り、裏にLexがあって対話形式でやり取りする形になっています。 機密・機微情報を入力されると困るため、初回利用時に利用規約の確認を実施しています。ここで同意が得られたユーザのみホワイトリストに登録して利用できるようにしています。推論時のパラメータは色々弄れますが、社内の大多数の人は使わないと思うので裏オプションで用意してます。画像生成時はチャンネルに「画像生成」、VLMはチャンネルに「画像説明」とつぶやくと使えるようになっています。
搭載している機能
- VLM
Vision Language Modelの略です。名前の通り、画像とテキストを複合して扱うモデルです。ここではAWS BedrockのClaude 3.5 Sonnetでimg2textを実装しています。画像とプロンプトをinputすると画像に対する説明文がoutputされます。近いうちに動画も入力できるように実装したいなぁと考えています(Lexは10MB以上のファイルを処理できないため何らかのアーキテクチャ変更が必要ですが笑)。次に説明する画像生成より実社会でのユースケースは広そうです。
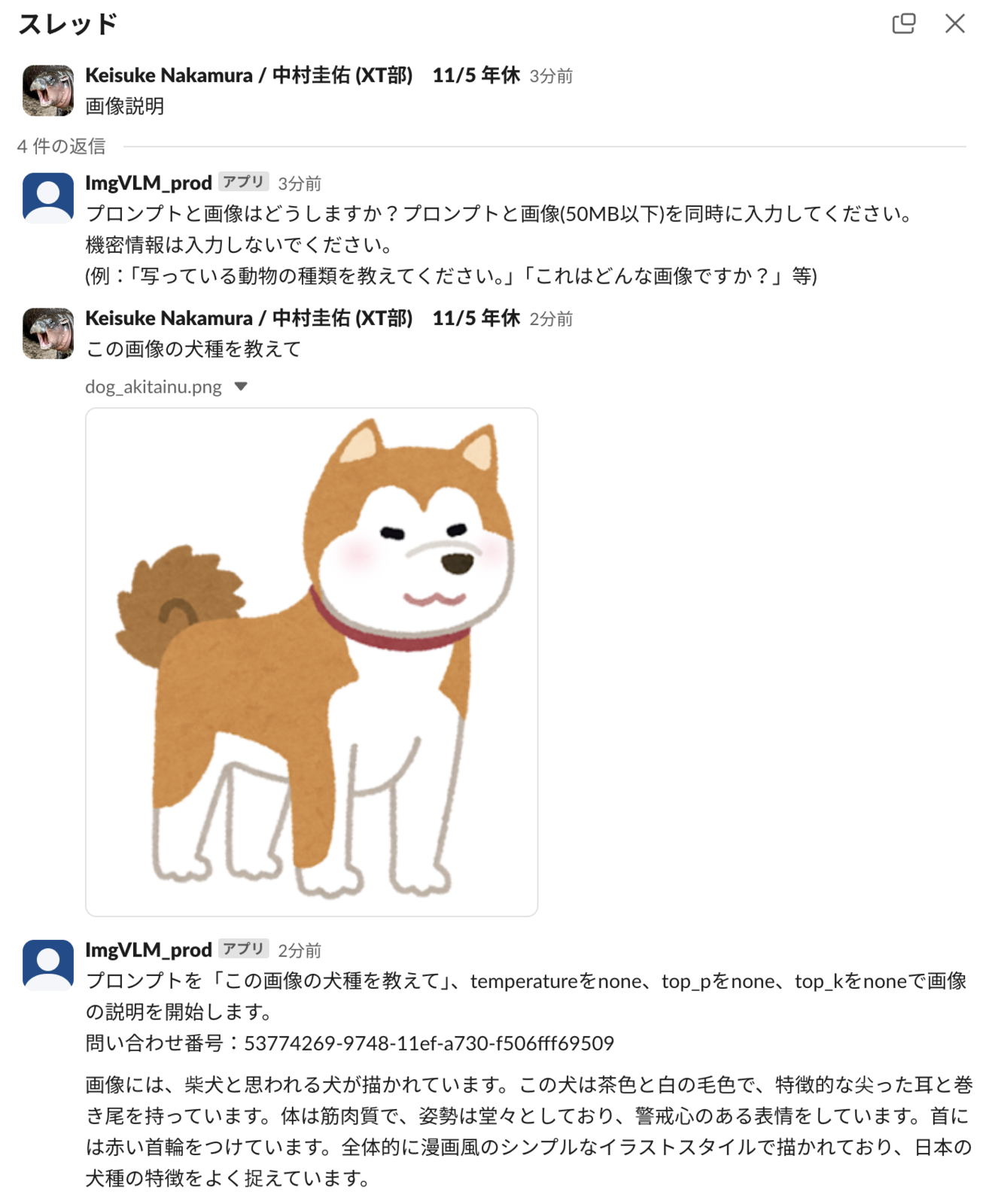
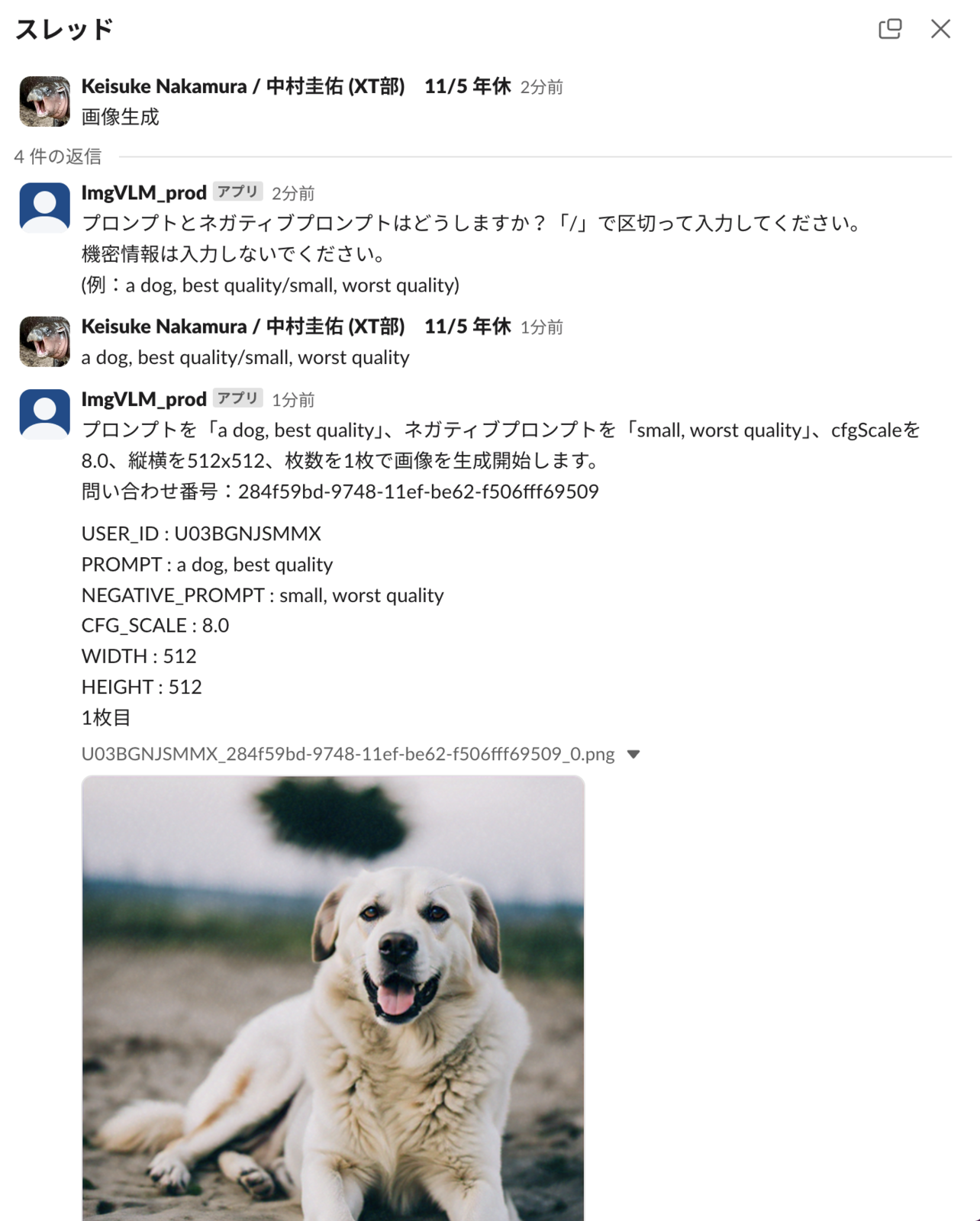
- 画像生成
AWS BedrockのTitan image generatorでtext2imgを実装しています。テキストを入力すると画像が出てきます。Titan image generatorはデフォルト著作権侵害しそうなプロンプトを弾いてくれるので便利です。こちらも近いうちにAzure OpenAI Serviceの画像生成機能(DALL-E3)実装を予定しています。
簡単なアーキテクチャ
かなりシンプルな構成になってます。 ユーザインターフェースはSlackですが、裏はこのようになっています。対話はLexで実施し、Lambdaを経由してECRにpushしたdocker imageを使いECSを立てて各種情報の保存やAPIなどを叩いています。VLMはClaude3.5を使い、画像生成はTitan image Generatorを使用しています。

感想や反応など
画像生成については前々から話題になっていましたが、VLMについては「こんなこともできるんだぁ〜」という声がありました。ユーザビリティ的な観点で言えば、Amazon Titan imageはプロンプトが英語onlyなので苦手な方は苦戦している印象でした。ここも改善するため日本語でも入力できるようLLMを使った翻訳を介したりなんらかの対策をとっていきたいと考えています。また、トークン数が超過してしまったり特定のワードが含まれているとoutputが出ずにエラーを吐くため、エラーの原因がユーザにわかるような機能も実装していきたいです。
以下様々な部署の皆さまに使っていただいてる図です。
まとめ
Latent diffusionのような高品質が画像が安定して生成できるモデルが論文で発表されて以来、社内で使えるようになるには少々時間がかかりましたが、なんとか実装できてよかったです。これだけではビジネスに繋がらないことは重々理解していますが、何かのきっかけになってくれればな、と思っています。特に技術的な部分に触れることがない大半の社員に対して「知ってもらう」ことができたのは大きいのかなと考えています。弊社でも生成系に関する応用研究をどんどん実施しているため、ビジネス活用に興味がある方/使ってみたいけど導入に悩んでいる方は是非下記のメールアドレスにご連絡ください!
連絡先
NTTドコモ R&Dイノベーション本部 クロステック開発部 複合価値創出担当 画像認識チーム
- 福島悠介 yuusuke.fukushima.fw@nttdocomo.com
- 井手秀徳 hidenori.ide.vw@nttdocomo.com
- 小原裕輝 yuuki.kohara.du@nttdocomo.com
- 中村圭佑 keisuke.nakamura.fc@nttdocomo.com