
1. はじめに
NTTドコモデータプラットフォーム部(以下DP部)の古川です。
大量のお客様の声からいかにして素早く、正確にインサイトを見つけ出し、事業活動に活かすか?これは多くの企業が直面する課題ではないでしょうか。
ドコモでもこれまで多岐にわたるお客様の声の分析や課題への対応管理は人手に頼ることが多く、貴重な声を迅速に施策へ活かすまでに時間と労力を要していました。
私たちのチームではこの課題を解決するため、新たな分析アプリケーションを開発しました。このアプリにより、お客様の声から課題を発見し、打ち手へと繋げるまでの一連のプロセスを、効率的かつ一気通貫で対応できるようになりました。開発にあたっては社内データ活用プラットフォームPochiを利用しています。
本記事では、この取り組みの一環として開発した、特定課題の効率的な発見・収集を支援する課題の類型化機能についてご紹介します。
なお本記事の執筆は、取組の詳細検討・実装を進めてもらった大谷さん、津坂さんに担当いただいています。
writer
NTTデータ デジタルサクセスソリューション事業部 大谷 眞史
NTTデータグループ 技術⾰新統括本部 AI技術部 津坂 悠太
社内データ活用プラットフォームPochi※1とは
私たちDP部は社内のデータ民主化を目指し、StreamlitとGoogle Cloudで圧倒的に使いやすいデータ活用プラットフォームを開発・推進しています。このプラットフォームは、24年度は30万時間もの業務効率化を実現し、直近では5,000人以上の社員に利用が拡大しています。
ASCII.jp:NTTドコモ、Streamlit利用の“ポチポチ分析アプリ”開発で社内データ活用を促進 (1/3)
※1: Pochiは社内の開発コードネームです
2. 課題とアプローチ
ドコモではお客様の声を分析しCX向上につなげるために、毎日寄せられる声に対して、どのような課題がどれくらいあるのかを分析して各サービスの改善担当者に棚卸をしています。 一方でサービス改善担当者からすると、分析結果が「通信品質」といった大きな括りになっており、例えば「特定の駅のホームでの通信速度」や「特定のアプリ利用中のパケ詰まり」といった、より具体的な粒度で声を集めたいのに、それができないという問題がありました。 この問題を解決するために、我々は「ある課題に関連する声が何件あるかを素早く把握する機能(類型化機能)」を提供することで、分析の手助けが出来ないかと考えました。
この機能を作成するにあたって、我々は4つのアプローチを検討しました。
LLMによる直接分類: LLM(大規模言語モデル)に個々の声を与えて、「これは『通信速度の課題』に関する内容ですか?」と一つずつ判定させる方法。精度は高くなることが予想されますが、大量のデータを処理するにはコストと時間がかかる問題があります。
専用の分類モデルを構築: 人手で「通信速度」「アプリ操作性」といったラベルを付けた教師データを作成し、機械学習で分類モデルを構築する方法。一度作れば高速に処理できますが、新しい種類の課題(例:新機能への要望)が出てくるたびにモデルを作り直す必要があり、柔軟性に欠けます。
ベクトル検索の活用: お客様の声と検索クエリ(例:「新宿駅 通信速度 遅い」)をベクトル化し、ベクトル空間上で距離が近い(内容が似ている)声を探し出す方法。精度は他手法には劣りますが、クエリを変えるだけで、分析したい粒度を自由自在に変更することができます。
ハイブリッド検索の活用: ベクトル検索(意味の近さで探す)と、従来のキーワード検索(特定の単語で探す)を組み合わせる方法。「新宿駅」のような固有名詞やサービス名を確実に含み、かつ「通信が遅い」という内容の声を抽出するなど、意味検索の柔軟性とキーワード検索の確実性を両立させることができます。ベクトル検索単体よりも高い精度を期待できますが、両方の検索エンジンを管理する必要があり、システム構成はやや複雑になります。
それぞれのメリット・デメリットをまとめると下記のようになります。
[表1:アプローチ比較のメリデメ表]
| 観点 | 案1: LLM直接分類 | 案2: 専用モデル構築 | 案3: ベクトル検索 | 案4:ハイブリッド検索 |
|---|---|---|---|---|
| 精度 | 高 | 中~高(教師データの質と量に依存) | 中 | 高(ベクトル検索よりは高い) |
| 開発コスト | 低 | 高(教師データ作成が大変) | 低 | 中(システム構成が複雑) |
| 運用コスト | 高(API利用料、処理時間) | 低 | 低 | 低 |
| 柔軟性 | 高(プロンプト次第で何でも聞ける) | 低(新しい分類には再学習が必要) | 高(クエリ変更のみ) | 高(クエリ変更のみ) |
| リアルタイム性 | 低 | 高 | 高 | 高 |
4つのアプローチを比較した結果、私たちは今回「案3: ベクトル検索」を最初のステップとして採用することにしました。
精度だけを追求するならば、ベクトル検索以外の案が良いでしょう。しかし、私たちはまず 「誰でも、素早く、思いついた切り口で分析できる」 という体験をユーザーに提供することが重要であると考えました。 ベクトル検索は、 リアルタイム で結果を返すことができ、思いついた切り口は クエリを変更するだけ で良い柔軟性を持っています。 また、完璧なものを時間をかけて作るよりも、まずは価値の核となる機能をいち早くユーザーに届け、フィードバックを得ながら改善していくというアジャイルな思想を重視し、ベクトル検索を採用しました。
今回採用するベクトル検索の実利用イメージを図1に示しています。 もちろん、ベクトル検索には検索結果にノイズが多いこと、クエリによってユーザーの意図と異なった結果になってしまう等といった課題もあります。そこで次の章では、この課題と向き合い、検索精度を少しでも向上させるために私たちが行った工夫について詳しく解説します。
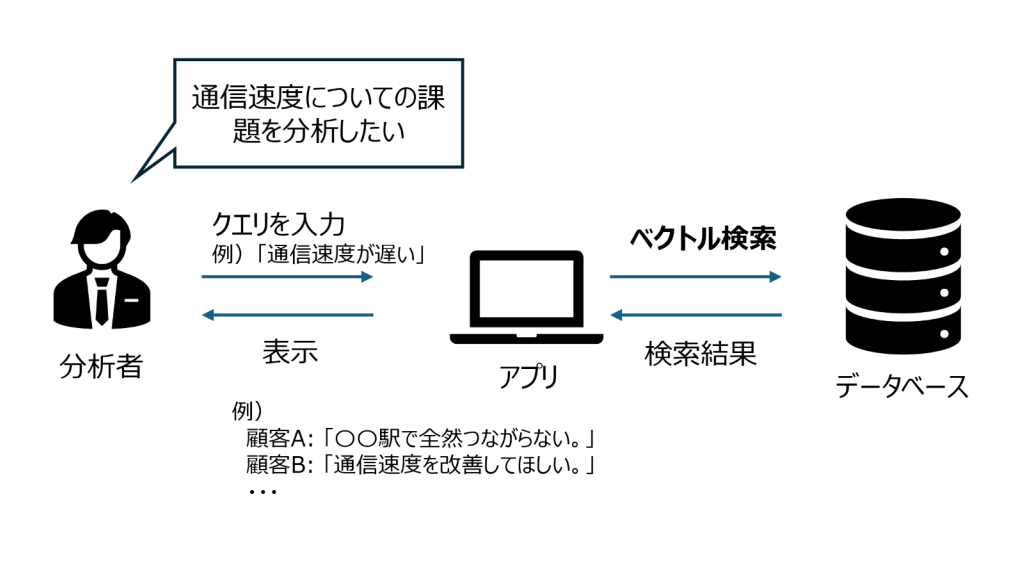
3. 検索精度向上への取り組み
今回の類型化の基本的な方針は、「お客様の声とユーザが入力した文章をそれぞれ埋め込みモデルでベクトル化し、ベクトル間のコサイン類似度※が閾値以上である場合に取得する」というシンプルなものです。
※コサイン類似度:二つのベクトルが指し示す方向の近さを表す指標です。-1から1の値をとり、1に近いほど「類似している」と判断されます。
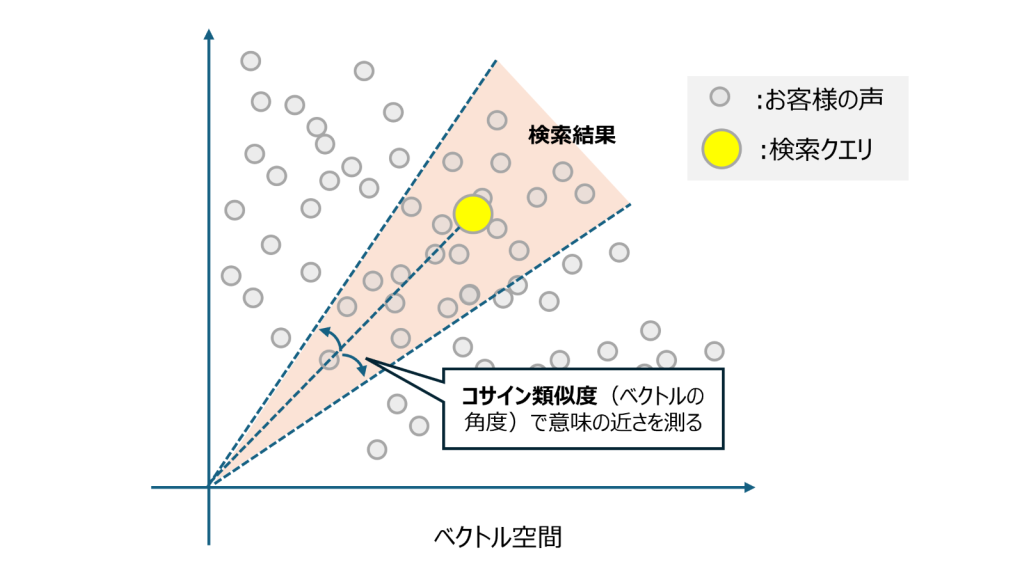
しかし、ここで一つ課題に直面します。それは検索精度の低さです。精度が低いと、本来検索すべき声が漏れてしまったり、逆に無関係な声が混入したりするため、正確な分析の妨げとなります。
この課題を解決するため、私たちは検索精度向上に向けた検証を以下のステップで行いました。
Step 1: 評価基盤の検討 〜どうやって「良さ」を測るか?〜
まずは、客観的かつ効果的に検索精度を評価するための土台作りです。「精度を良くする」と一言に言っても、その「良さ」を測る共通の物差しがなければ、どの改善が本当に効果的だったのかを客観的に判断できません。「なんとなく良さそう」といった感覚的な評価に頼ってしまうと、最終的にビジネスの現場で役立たない選択をしてしまうリスクがあります。
そこで私たちは、これから試す様々なアプローチの優劣を公平に判定するための「評価基盤」を、まず最初に設計することにしました。この評価基盤は、以下の3つの要素から構成されます。
- 検証データセット: 実際のお客様から寄せられた声データ約5,000件を、検証データとして用意しました。 また、検索シナリオの多様性に対応するため「通信速度が遅い」「アプリのログインができない」などの一般的な表現に加え、キーワードや固有名詞を含むもの、口語表現や略語パターンなども含めて、合計100パターンの検索クエリを作成しています。ここでは、実利用に即した精度評価を意識した実験設計としました。
2.正解データ:
100パターンのクエリそれぞれに対し、検索対象となる約5,000件の声の中から「どれが本当に検索すべき声か(=正解)」をラベル付けする必要があります。しかし全件を人手でラベリングするのは、膨大な工数が発生します。そこで今回は、当時の高性能モデルであったGPT-4.1を用いて、正解データセットの効率的な作成に取り組みました※。
※LLMで正解を作成する際の注意点: LLMで正解データを作るのは効率的ですが、注意が必要だと考えます。LLMが生成した「正解」と、私たちがビジネスの目的上「正解としたいもの」が一致しない場合があります。これを防ぐため、必ず人間が作成した正解とLLMが作成した正解を比較し、ズレがないかを確認することが重要です。本検証では、LLMが作成した正解データを人間が確認し、正解データの妥当性を事前に評価しています。これを怠ると、「評価スコアは高いのに、現場では全く使えない」という結果になりかねません。
3.評価指標: 適合率と再現率の調和平均であるF1スコアの最大値を主要指標としました。加えて、最適な閾値の標準偏差を副次的評価指標とします。この値は、各クエリごとに適切な閾値がどれだけばらつくかを表し、値が小さいほど様々な検索クエリに対して安定した閾値を個別に調整する必要がなくなり、運用負荷を下げることができると考えられます。
Step 2: 比較手法 〜精度を上げるための組み合わせ探し〜
次に、精度向上に効果的と考えられるアプローチを洗い出し、複数の手法を組み合わせて比較検証しました。本検証では、下記の3つのアプローチに注力しています。(なお、ベクトル化モデルのタスクタイプや埋め込みベクトルの次元数なども、検索精度に影響を及ぼす点ですので、興味のある方は公式ドキュメントを参照してください。)
ベクトル化モデル
今回は、性能と多言語対応などを考慮し、下記2つのベクトル化モデルを比較対象としました。なお、本検証では、私たちが利用する分析基盤であるGoogle Cloud上で最適なモデルを選定することを目的とし、同プラットフォームで提供されるモデルを比較しました。もしクラウドやツールの制約がなければ、OpenAIやCohere社のモデル、日本語特化型のモデルなど、他の埋め込みモデルも有力な選択肢となります(業務要件に応じて比較・検討をおすすめします)。
- モデルA:
text-multilingual-embedding-002 - モデルB:
gemini-embedding-001
- モデルA:
テキスト前処理
ベクトル化する前に、ノイズ(例:定型文、日付表現、タグ等)を取り除いたり、重要な情報を凝縮することで、文章の本質的な情報だけをベクトル化し、検索精度向上を目指します。今回は「①ルールベースによるノイズ除去」と、「②LLMを活用した要約・除去」の2手法を検証しました。
- ①ルールベース: 署名や日付・定形フレーズ・不要なタグなどを正規表現で機械的に削除します。
- ②LLM: たとえば「このお客様の声から余分な署名や絵文字、よく使われる社内定型語を除いて短くまとめてください」といった具体的なプロンプト指示をLLMに与え、前処理を実施しました。
クエリ拡張
ユーザーは「通信が遅い」といった短文や、抽象的な言葉で検索する傾向があります。しかし、検索対象となる「お客様の声」は具体的な状況が書かれた文章であるため、両者の表現が一致せず、検索精度が低下するという課題が見えていました。そこで、LLMを用いてユーザーのクエリを拡張し、検索に適した文章に変換するアプローチを検証しました。 具体的には、LLMに「抽象的なクエリに対し、関連する具体的な表現を複数生成してください」と指示します。実際にLLMに拡張させた例を以下に示します。
元クエリ: 「通信が遅い」
拡張クエリ:
- 「スマートフォンのデータ通信が遅いことへの不満」
- 「特定の地域や時間帯でインターネット接続が遅くなる。」
- 「5Gサービスを利用しているのに通信速度が思ったより遅い」
これらの多様な表現を検索クエリに加えることで、表現の揺れを吸収し、ユーザーの意図通りに声を探し出せるようになるのではないかと考えました。 またどのようなクエリ拡張を行えば検索精度が最も向上するのかについても検証しました。
Step 3: 検証結果と考察 〜どのアプローチが良いか?〜
数十パターンの組み合わせを試した結果の一部を表2に示します。
[表2:各手法の評価指標比較表]
| 手法 | 最大F1スコア | 最適閾値の標準偏差 |
|---|---|---|
| モデルA (text-multilingual-embedding-002) | 0.53 | 0.06 |
| モデルA + ルールベース | 0.49 | 0.06 |
| モデルA + LLM要約 | 0.53 | 0.06 |
| モデルB (gemini-embedding-001) | 0.64 | 0.04 |
| モデルB + ルールベース | 0.61 | 0.04 |
| モデルB + LLM要約 | 0.57 | 0.04 |
| モデルB(クエリ拡張あり) | 0.66 | 0.04 |
今回の検証結果から、以下の知見が得られました。
ベクトル化モデルの選定が重要
gemini-embedding-001がtext-multilingual-embedding-002に比べてF1スコアが全体的に高いことがわかります。実際、執筆時点でgemini-embedding-001はGoogleの他モデル(text-multilingual-embedding-002)や他の主要な商用モデルを凌駕する性能を有しており、特に日本語を含む多言語でもトップクラスの実力が報告されています。 この結果より、今後もモデルのアップデート情報を適切に追い、最適なモデルを選定していくことが重要だと考えます。今回のデータ特性では、特定の前処理が不適
意外なことに、今回の検証では、ルールベースでのノイズ除去やLLMによる要約といったテキスト前処理は、いずれのモデルにおいてもスコアを低下させる、もしくはほとんど変化させない結果となりました。 これは、お客様の声に含まれる一見ノイズに見える情報(例:タグ)が、実は文脈を理解する上で重要な意味を持っており、それを除去することでかえって情報が欠落してしまったためではないかと推測しています。LLMによる要約も、要約の過程で重要なニュアンスが失われてしまった可能性が考えられます。
クエリ拡張による精度向上と実用化に向けた実装
検証の結果、最も高いF1スコアを記録したのは、
gemini-embedding-001モデルにクエリ拡張を適用した手法でした。このアプローチは、特にユーザーが入力しがちな短文や抽象的なクエリに対して顕著な精度改善効果を示しました。クエリ拡張を適用することによる、F1スコアの改善幅は0.02と一見すると大きくありませんが、クエリ拡張は実運用において、検索精度の安定性を担保する上で有効であると考えます。なぜなら、実際の利用シーンでは、ユーザーが入力するクエリの質や形式を制御することは不可能であり、多様な入力に対して安定した性能を維持することが重要となるためです。
一方で、LLMが生成するクエリが、必ずしもユーザーの意図と一致するとは限りません。例えば「"パケ詰まり"について調べたいのに、"5G"といった少しずれた候補も出てしまう」といったケースです。 そこで私たちは、LLMが拡張したクエリを自動で検索適用するのではなく、ユーザー自身がそれらを任意に選択できるインターフェースを採用しました。 これにより、ユーザーは自分の意図に沿わない検索結果に煩わされることなく、最終的な検索をコントロールできます。この工夫が、分析の精度とユーザーの納得感を両立させる鍵となると考えています。
これらの検証から、私たちは「前処理は行わず、gemini-embedding-001 を使用し、クエリ拡張を適用する」という組み合わせが、今回の目的において適切であると結論付けました。
一般的に有効とされるテキスト前処理も、対象データの特性によっては逆効果になり得ることを示唆しています。データの特性を深く理解し、仮説と検証を繰り返すことの重要性を再認識させられる結果となりました。
4.ユーザーの声
先日、社内でアプリの利用体験会を実施しました。
11月14日時点でアンケートに回答した43名のうち、31名(72%)が今後の業務で活用できそうだと前向きな意見を寄せています。
特に良かった点としては、
- 特定の見たい課題が決まっている場合、簡単に分析結果を出せる点
- ドコモに届いた問い合わせを簡単に検索できる
- 確認したい声を簡単な操作で確認できる点
など、類型化機能に関する評価が多くありました。
5. 今後の展望
今回ご紹介した検索機能は、分析担当者が特定の仮説を検証するために使われる、いわばトップダウン型のアプローチです。これは既知の課題を深掘りすることを目的とした手法です。
しかし、このアプローチだけでは、分析担当者自身がまだ認識していない、潜在的な課題や予期せぬお客様のニーズを発見することは困難です。
そこで現在私たちは、ボトムアップ型のアプローチ、つまり「課題の“タネ”をお客様の声から自動的に見つけ出す」機能の開発に取り組んでいます。
具体的には、日々寄せられる声をクラスタリングし、これまで見られなかった新しい話題や急上昇しているトピックの塊を出力する仕組みです。これにより、分析担当者は自ら検索クエリを考えることなく、注目すべき課題や要望を発見できるようになります。
6. おわりに
本記事では、大量のお客様の声を柔軟に分析する課題に対し、ベクトル検索を用いた取り組みをご紹介しました。
データの特性・手法の特性を深く理解し、仮説と検証を繰り返すことの重要性を改めて実感するプロジェクトとなりました。今後は、未知の課題を自動発見するボトムアップ型のアプローチにも挑戦していきます。
この記事が、皆さんの分析業務における試行錯誤のヒントになれば幸いです。