

この記事は NTTドコモ R&D Advent Calendar 2025 の24日目の記事です。
はじめに
NTTドコモ データプラットフォーム部(以下、DP部)の塚本です。主にコンシューマ領域における事業部門やマーケティング部門などのビジネス部門(LOB: Line of Business)へのデータ分析支援や、ビジネス部門主体でデータ活⽤を完結できるようにするためのツール提供などに従事しています。
ビジネス部門主体のデータ活用の取り組みを推進する中で、課題となったのが「スピード」と「ガバナンス」の両立です。常に締め切りと目標達成に追われている状況であっても、無理なくデータガバナンスを担保するため、技術的なアプローチによる解決策を模索してきました。
本記事では、Python と GitHub Actions を活⽤してパーソナルデータの利⽤箇所を⾃動で追跡し、安⼼・安全なデータマート運⽤を実現するチャレンジについてご紹介します。
以降の記事は業務委託先である株式会社 Lupinus の太田さんに執筆協力頂きました。
取り組みの背景
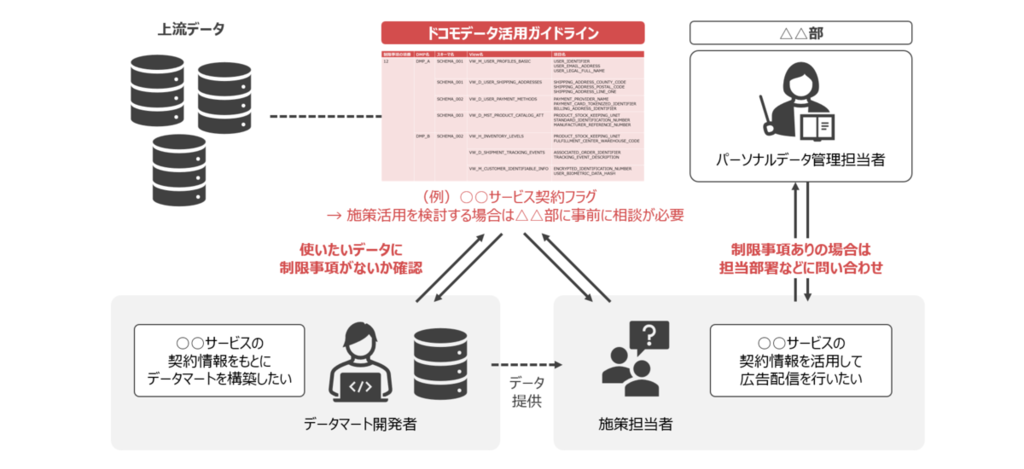
ドコモデータ活用ガイドライン
ドコモでは、データ活用にかかるさまざまな制限事項を遵守し、適法かつ適切にデータを利用するため、全社共通の 「ドコモデータ活用ガイドライン」 を策定しています。ガイドラインの中では、ガバナンスの考え方や判断基準が示されるとともに、上流の DMP (Data Management Platform) の個別のView・カラムにかかる制限事項が一覧化されています。
施策を検討するデータ利用者はもちろん、私たちのようにビジネス部門向けの分析やデータマートの開発を行う場合でも、ガイドラインに定められた制限事項を正しく把握し、利用者に向けて情報提供することが不可欠です。
ドコモにおけるパーソナルデータの取り扱いや活用方法については、以下のページもご参照ください。
ビジネス要件に合わせたデータマート整備
ビジネス部門でデータマーケティングを実施するためには、既存のデータ基盤では足りず、各部門に特化したデータマートが必要です。新たなデータマートの整備業務は主に私たちDP部が担当します。これまではデータの専門家であるDP部がしっかりとサポートしながらデータガバナンスを担保してきましたが、ビジネス部門でのデータ活用の自走化が進む中で、ビジネス部門単独でもデータ活用ガイドラインを遵守できる仕組みが求められていました。
従来の運用方法について整理を進めていくと、次のような課題が明らかになりました。
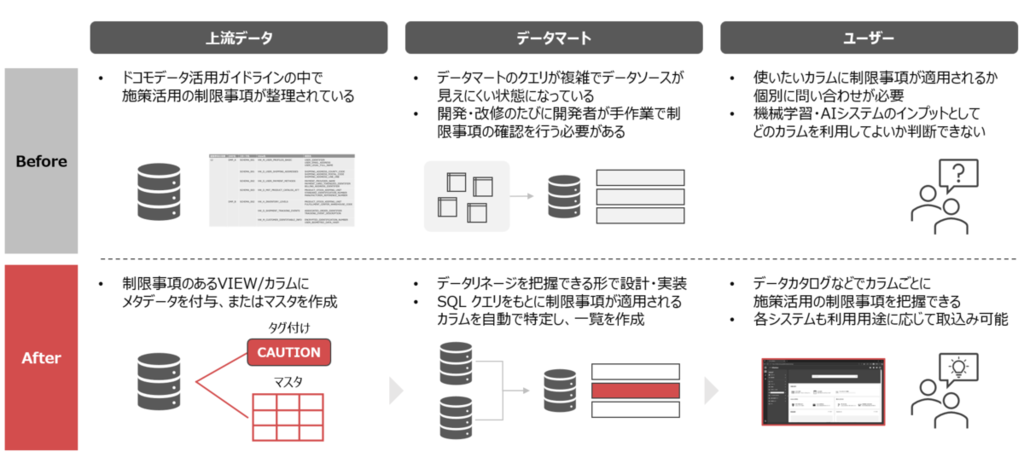
課題1. データマートの利用制限の明確化
データマートの利用者となるビジネス部門にはデータガバナンスに必ずしも習熟していない方もいるため、専門的な知識がなくても安全にデータを扱えることが重要です。そのためには、データの制限事項や注意点を利用者が容易に把握できる仕組みが必要です。しかし、上流データと異なり、私たちが構築したデータマートについては、カラム別の制限事項が一覧化されおらず、スムーズな施策活用を妨げる一因となっていました。
課題2. 利用制限把握のための調査負担
従来の方法では、新たなデータマートの開発や既存のものの改修を行うたびに、どのデータがどの制限事項を持つのか、開発者が手作業で調査する必要がありました。ガイドラインと SQL クエリを照合するため、個々のデータマートが複雑になるにつれて確認作業の負担は増加し、1回あたり30分~1時間ほどの時間を要していました。また、見落としを防ぐためのダブルチェックが必要となり、さらなる工数増加を招いていました。
課題3. 高頻度な開発・改修による運用負担の増加
ビジネス部門向けのデータマートでは、施策の仮説検証サイクルを高速で回すために、開発・改修のスピード感が求められます。また、サービス内容の変更などに伴うカラムの追加や仕様の変更、上流データの変更や削除に起因する修正も毎月のように発生します。運用するデータマートの数が増加し、頻繁に開発・改修が行われる中で、制限事項の調査・把握にかかる運用負担も増加していました。
こうした運用上の課題を踏まえ、人手での調査・制限事項の明確化では限界だと判断し、これを機械的に実施できる方法を模索しました。技術的な要件は以下の2点です。
要件1. 現在のデータ基盤の制約でも実現可能なアーキテクチャ
私たちが利用している Snowflake には、カラム単位でメタデータを付与し、それが参照されるたびに自動で伝搬させていく オブジェクトタグ の機能が備わっています。当初はこの機能の導入を検討しましたが、オブジェクトタグを有効活用するためには社内のデータ基盤全体での調整が必要であり、年単位の時間を要することが予想されました。また、仮に使用できるようになったとしても、カラムレベルのリネージをすべて把握し、網羅的に伝搬させることができるかは不透明でした。そのため、今回は現時点の技術制約の範囲内で確実に実現可能なアーキテクチャを検討しました。
要件2. データガバナンスの既存運用フロー変えない仕組み
データマートの制限事項を追跡するためには、大元となる上流データの制限事項を取得する必要があります。データ活用ガイドラインは非エンジニアからなるガバナンスチームが作成しており、現時点では PowerPoint ファイルで管理されています。将来的に Machine-readable なメタ情報として整備するための議論が進められていますが、今すぐに運用フローを変えてもらうことは現実的ではありません。今回は、PoC をクイックに回すためスモールスタートで、PowerPoint ファイルから必要な情報を自動で取得し、プログラムが読み取れる形式に変換する仕組みを構築することにしました。
これらの課題と要件を踏まえ、今回は、データ活⽤ガイドラインの PowerPoint ファイルとデータマートを定義する SQL クエリをもとに、Python と GitHub Actions を活用して 「制限事項の取得→追跡→公開」を自動化 することに挑戦しました。
目標
- データ活用ガイドラインの PowerPoint ファイルから必要な情報を取得できる。
- SQL クエリを解析し、データマートの個々のカラムにかかる制限事項を特定できる。
- SQL クエリを変更した際に自動で制限事項一覧が更新される。
全体設計
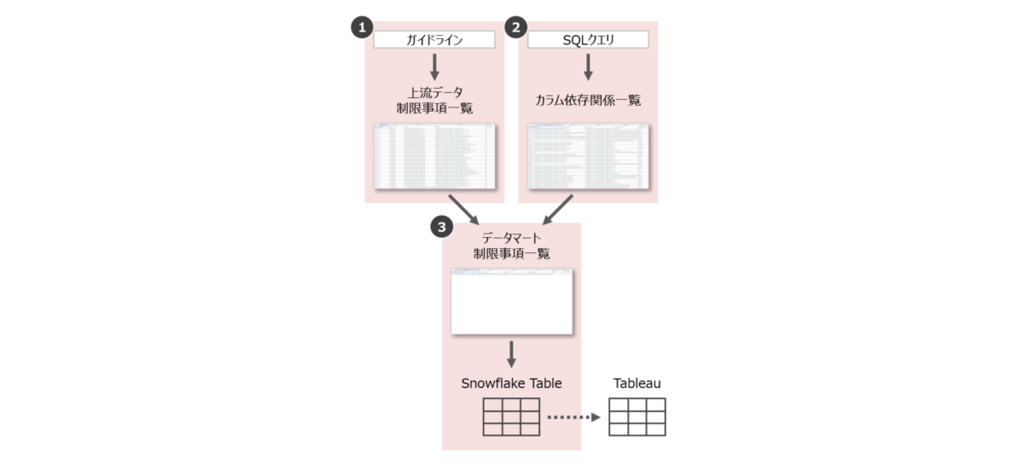
全体の実装方針は次の通りです。
- Step 1. 上流データの制限事項一覧の取得
- データ活用ガイドラインの PowerPoint ファイルから、上流 DMP の制限事項一覧を取得
- Step 2. カラムの依存関係の解析
- データマートの SQL クエリを解析し、カラム単位の依存関係一覧を作成
- Step 3. データマートの制限事項の特定と公開
- 上流の制限事項一覧とカラムの依存関係一覧を用いて、データマートの各カラムにかかる制限事項を特定
- 特定した制限事項は Snowflake 上のテーブルにアップロードして一覧化
- ビジネス部門の利用者が容易に確認できるよう、BIツールにも接続
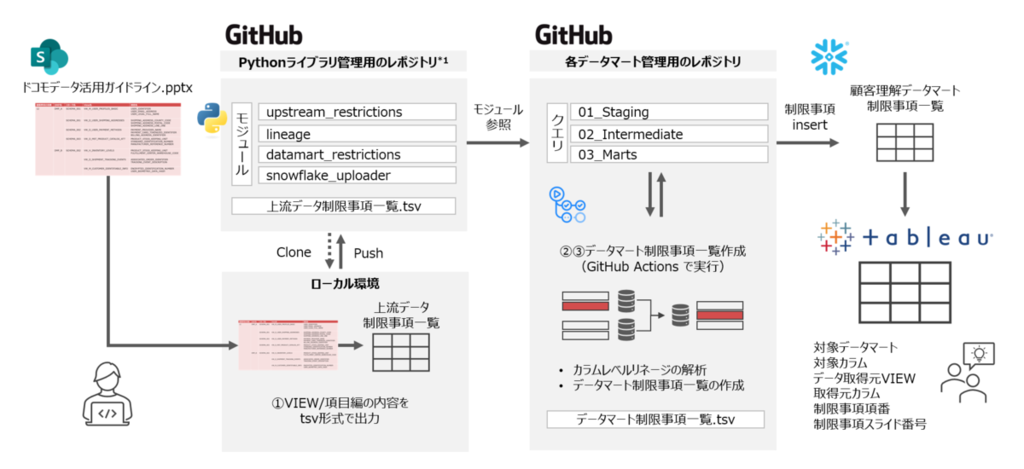
主要な機能はすべて Python で実装し、ライブラリとしてまとめておきます。また、GitHub Actions を用いて CI/CD 環境を構築し、クエリの変更があった際に制限事項の特定処理が自動で実行されるようにします。
なお、今回の実装では、以下の【コード例】を含むコーディング作業の9割以上を GitHub Copilot Coding Agent に任せ、人間である私たちは要件の精緻化とレビューに注力しました。GitHub Copilot や Vibe Coding の活用事例については以下の記事でもご紹介しておりますので、ぜひ合わせてご覧ください。
- GitHub Copilotを育ててSQLを効率的にdbtモデル化した事例 - ENGINEERING BLOG ドコモ開発者ブログ
- Claude Codeを用いたVibe Coding開発のすすめ - ENGINEERING BLOG ドコモ開発者ブログ
次の章では、各機能の実装方法について解説していきます。
個別機能の実装
Step 1. 上流データの制限事項一覧の取得
まず、データ活用ガイドラインの PowerPoint ファイルから上流データの制限事項一覧を取得します。
ファイルの読み取りには、Python の python-pptx ライブラリを採用しました。PowerPoint ファイルを扱えるライブラリは他にもありますが、python-pptx は暗号化されたファイルも処理できる点が特長です。
ガイドラインは人間にとっての読みやすさを重視して作成されているため、プログラムで処理するにはいくつかの工夫が必要でした。
- 抽出対象の特定
- スライドタイトルをもとに対象範囲を特定
- 表のヘッダーが必要な列名(下表参照)をすべて含む場合、表の内容を取得
- 結合されたセルの処理
- 列方向にセル結合されている場合、最初の行の値を他の行にコピーして対応
- 複数行にわたるセルの分割
- 1つのセルに複数のView名/カラム名が含まれる場合は、それぞれ独立した行に分割
- 改行コードの処理
- ファイル内に LF (
\n), CR (\r), Vertical Tab (\v) の3種類の改行コードが混在していたため、すべてを正しく認識するよう対応
- ファイル内に LF (
こうした試行錯誤の結果、次のようにプログラムでも読み取りやすい形式で上流の制限事項一覧を取得できるようになりました。取得した内容は tsv 形式で保存し、後続の処理で利用できるようにしておきます。
【出力例】上流データの制限事項一覧
| 制限事項の項番 | DMP名 | スキーマ名 | View名 | カラム名 | スライド番号 |
|---|---|---|---|---|---|
| 12 | DMP_A | SCHEMA_001 | VW_M_USER_PROFILES_BASIC | USER_IDENTIFIER | 32 |
| 12 | DMP_A | SCHEMA_001 | VW_M_USER_PROFILES_BASIC | USER_EMAIL_ADDRESS | 32 |
| 12 | DMP_A | SCHEMA_001 | VW_M_USER_PROFILES_BASIC | USER_LEGAL_FULL_NAME | 32 |
| 12 | DMP_A | SCHEMA_001 | VW_D_USER_SHIPPING_ADDRESSES | SHIPPING_ADDRESS_COUNTY_CODE | 32 |
Step 2. カラムの依存関係の解析
次に、データマートの SQL クエリを解析し、カラム単位の依存関係を明らかにします。今回の取り組みの中でもコアとなる機能と言えます。
SQLの解析には、30種類以上の方言に対応したSQLパーサーである sqlglot ライブラリを使用しました。SQLクエリを 抽象構文木 (AST: Abstract Syntax Tree) と呼ばれる構造的なデータに変換し、複雑なクエリの構造を正確に把握することが可能です。データマートを定義するためのすべての SQL ファイルに対し、次のような手順で処理を行います。
- SQL ファイルを読み込む。
CREATE TABLE AS SELECT ...やINSERT INTO ... SELECT ...といった構文から、解析対象となるSELECT文を抜き出す。sqlglot.parse_one()でSQLをパースし、抽象構文木に変換する。- 抽象構文木を走査し、どのカラムがどのカラムに依存しているかを特定する。
最終的に出来上がった Python コードの一部と実行例を以下に示します。
コード例中の (b) extract_column_lineage() がカラムの依存関係を抽出するメインの関数です。この関数に SELECT 句を含む SQL クエリを渡すことで、カラム単位の依存関係一覧を作成することができます。なお、dialect 引数には Snowflake 以外の方言を指定することも可能です。
(a) extract_table_alias_map() は (b) の内部で呼び出される関数で、クエリの中からテーブルのエイリアスを検出し、「どのエイリアスがどのテーブルを指しているか」という対応表(マップ)を動的に作成します。CTE については、データマートを構築するクエリ全体で名前が一意になるよう、「テーブル名::CTE名」の形式で扱うようにしています。この処理を挟むことで、複雑な SQL クエリでも依存関係を正確に追跡できるようになりました。
【コード例】カラムレベルの依存関係の抽出
import sqlglot from sqlglot import exp import re from typing import Dict, Optional # ======================================== # 関数定義 # ======================================== # (a) テーブルエイリアスマップの作成 def extract_table_alias_map(parsed: exp.Select, dialect: str, target_table: Optional[str] = None) -> Dict[str, str]: alias_map = {} tables = [] cte_names = set() # CTE名を取得 for cte in parsed.find_all(exp.CTE): if cte.alias: cte_names.add(cte.alias) cte_expr_name = getattr(getattr(cte, 'this', None), 'alias', None) if cte_expr_name: cte_names.add(cte_expr_name) # FROM句とJOIN句内のすべてのテーブル参照を検索 for table in parsed.find_all(exp.Table): table_name = table.sql(dialect=dialect) # テーブル名をクリーニング cleaned = re.sub(r'/\*.*?\*/', '', table_name) cleaned = re.sub(r'\s+AS\s+\w+', '', cleaned, flags=re.IGNORECASE) cleaned = ' '.join(cleaned.split()) clean_name = cleaned.strip() # テーブル名がCTEかどうかをチェック cte_base_name = ( table.alias if table.alias and table.alias in cte_names else clean_name if clean_name in cte_names else None ) is_cte = cte_base_name is not None # CTEの場合: "テーブル名::CTE名" に変換 if is_cte and target_table: qualified_name = f"{target_table}::{cte_base_name}" tables.append(qualified_name) if table.alias: alias_map[table.alias] = qualified_name if cte_base_name != table.alias: alias_map[cte_base_name] = qualified_name # 通常のテーブル名の場合: そのまま使用 else: tables.append(clean_name) if table.alias: alias_map[table.alias] = clean_name else: parts = clean_name.split('.') alias_map[parts[-1]] = clean_name # 修飾子なしのカラムのデフォルトマッピングを追加 if tables: alias_map['__default__'] = tables[0] return alias_map # (b) カラム単位の依存関係取得 def extract_column_lineage(select_sql: str, target_table: str, dialect: str = "snowflake"): lineage = [] # SQLを抽象構文木 (AST) にパース try: parsed = sqlglot.parse_one(select_sql, read=dialect) except Exception as e: print(f"パースエラー: {e}") return lineage if not isinstance(parsed, exp.Select): print("パースされたSQLがSELECT文ではありません。") return lineage # テーブルエイリアスマップを作成 alias_map = extract_table_alias_map(parsed, dialect, target_table) # SELECT句からカラムの依存関係を抽出 for select_expr in parsed.expressions: target_column = None # ターゲットカラム名を特定 if select_expr.alias: target_column = select_expr.alias elif isinstance(select_expr, exp.Column): target_column = select_expr.name if not target_column: continue # 各カラムのソースを特定 for col in select_expr.find_all(exp.Column): if col.table: source_table = alias_map.get(col.table, col.table) else: source_table = alias_map.get('__default__', 'UNKNOWN') lineage.append({ 'source_table': source_table, 'source_column': col.name, 'target_table': target_table, 'target_column': target_column, 'dependency_type': 'SELECT' }) return lineage
【例1】単純なSELECT文
sql1 = """ SELECT product_id, price * quantity AS total_amount, UPPER(product_name) AS product_name_upper FROM sales """ print("=== 例1: 単純なSELECT文 ===") result1 = extract_column_lineage(sql1, "SALES_SUMMARY") for record in result1: print( f"{record['source_table']}.{record['source_column']} -> " f"{record['target_table']}.{record['target_column']}" )
=== 例1: 単純なSELECT文 === sales.product_id -> SALES_SUMMARY.product_id sales.price -> SALES_SUMMARY.total_amount sales.quantity -> SALES_SUMMARY.total_amount sales.product_name -> SALES_SUMMARY.product_name_upper
【例2】JOIN句を含むSELECT文
sql2 = """ SELECT o.order_id, o.order_date, c.customer_name, c.email FROM orders AS o JOIN customers AS c ON o.customer_id = c.customer_id """ print("\n=== 例2: JOIN句を含むSELECT文 ===") result2 = extract_column_lineage(sql2, "ORDER_SUMMARY") for record in result2: print( f"{record['source_table']}.{record['source_column']} -> " f"{record['target_table']}.{record['target_column']}" )
=== 例2: JOIN句を含むSELECT文 === orders.order_id -> ORDER_SUMMARY.order_id orders.order_date -> ORDER_SUMMARY.order_date customers.customer_name -> ORDER_SUMMARY.customer_name customers.email -> ORDER_SUMMARY.email
【例3】CTE (共通テーブル式) を使用するSELECT文
sql3 = """ WITH sales_cte AS ( SELECT product_id, quantity, price FROM sales ) SELECT s.product_id, s.quantity * s.price AS total FROM sales_cte AS s WHERE s.quantity > 1 """ print("\n=== 例3: CTEを使用するSELECT文 ===") result3 = extract_column_lineage(sql3, "SALES_CTE_SUMMARY") for record in result3: print( f"{record['source_table']}.{record['source_column']} -> " f"{record['target_table']}.{record['target_column']}" )
=== 例3: CTEを使用するSELECT文 === SALES_CTE_SUMMARY::sales_cte.product_id -> SALES_CTE_SUMMARY.product_id SALES_CTE_SUMMARY::sales_cte.quantity -> SALES_CTE_SUMMARY.total SALES_CTE_SUMMARY::sales_cte.price -> SALES_CTE_SUMMARY.total
すべての SQL ファイルを走査し、抽出した依存関係を次のような1つの tsv ファイルにまとめて出力します。この出力をもとに再帰的に依存関係をたどることで、最終的にデータマートの各カラムが上流 DMP のどのカラムに依存しているかを把握できるようになります。
【出力例】カラム依存関係一覧
| source_table | source_column | target_table | target_column |
|---|---|---|---|
| DB.SCHEMA.SALES | PRODUCT_ID | DB.SCHEMA.SALES_SUMMARY | PRODUCT_ID |
| DB.SCHEMA.SALES | PRICE | DB.SCHEMA.SALES_SUMMARY | TOTAL_AMOUNT |
| DB.SCHEMA.SALES | QUANTITY | DB.SCHEMA.SALES_SUMMARY | TOTAL_AMOUNT |
| DB.SCHEMA.SALES | PRODUCT_NAME | DB.SCHEMA.SALES_SUMMARY | PRODUCT_NAME_UPPER |
各レコードがカラムの依存関係を示しています。例えば1行目は、DB.SCHEMA.SALES テーブルの PRODUCT_ID カラムが、DB.SCHEMA.SALES_SUMMARY テーブルの PRODUCT_ID カラムの作成時に使用されていることを表しています。
Step 3. データマートの制限事項の特定と公開
Step 1 で取得した「上流データの制限事項一覧」と、Step 2 で作成した「カラム依存関係一覧」を用いて、データマートの各カラムにかかる制限事項を特定します。
手順は比較的シンプルで、次のように進めます。
- データマートの構築に使用している上流データのカラムのうち、制限事項があるものを特定する。
- カラム依存関係一覧をもとに、制限事項のあるカラムの影響範囲を再帰的に追跡する。
- 2 の追跡結果から、最終的なデータマートのカラム別制限事項一覧を作成する。
このように作成したデータマートの制限事項一覧は、snowflake-connector-python を利用して Snowflake 上のテーブルに格納しています。利用者は、このテーブルが接続された Tableau のワークブックを参照するだけで、いつでも最新の制限事項を確認できるようになりました。
CI/CD 環境の構築
最後に、ここまでの一連の処理をまとめ、GitHub Actions を用いて CI/CD 環境を構築します。SQL ファイルが変更 (push または pull_request) されるたびにこのワークフローが実行され、制限事項一覧が自動で更新される仕組みです。なお、Step 1 の処理には PowerPoint のデスクトップアプリが必要となるため、ここでは Step 2 と Step 3 の処理のみを行うワークフローを定義しています。
【コード例】GitHub Actions による CI/CD 環境の構築
name: Upload Datamart Restrictions to Snowflake # 実行条件定義: main ブランチの src/snowflake/models/ 配下のファイルに変更があった場合 on: push: branches: - main paths: - 'src/snowflake/models/**' pull_request: branches: - main paths: - 'src/snowflake/models/**' workflow_dispatch: # 実行ジョブ定義 jobs: upload-restrictions: runs-on: ubuntu-latest permissions: contents: read steps: # 現在のレポジトリの内容を実行環境にクローン - name: Checkout code uses: actions/checkout@v4 # Python 環境のセットアップ - name: Set up Python uses: actions/setup-python@v5 with: python-version: '3.10' - name: Install dependencies run: | python -m pip install --upgrade pip pip install -r requirements.in # Step2: カラムの依存関係の解析 - name: Analyze lineage from SQL models run: (省略) # Step3: データマートの制限事項の特定と公開 - name: Create and upload datamart restrictions to Snowflake run: (省略)
導入効果と今後の展望
本取り組みにより、データマートの制限事項を漏れなく、ミスなく整備できるベースラインが整いました。
まだ実務導入前の段階ではありますが、これまで開発者が手作業で行っていた制限事項の調査・追跡が不要になったことで、当チームのみで 年間約50時間(開発・改修1件あたり1時間×年間50回)の工数削減が見込まれます。同様の仕組みを全社的に展開することができれば、数十倍の効果を出せると試算しています。
また、データの利用者自身がカラム別の制限事項をいつでも確認できる体制が整ったことも大きな成果です。高い品質でガバナンスを維持し、スムーズに情報提供することで、ビジネス部門主体のデータ利活用の活発化が期待できます。さらに、今回の仕組みを応用し、ユーザが実際に制限事項のあるカラムを使おうとしたときにアラートを飛ばすような仕組みを構築することも考えられます。
今後は、今回構築した仕組みを実際の業務に定着させていくフェーズに⼊ります。具体的な業務フローの作成やユーザーテストなどを通して、開発者を含めた誰もが安⼼して使える状態を⽬指します。個別の機能についても さらなる改良の余地が残っています。関係各部署と連携しながら改善を重ね、真に価値のある仕組みに育てていきたいと考えています。
まとめ
本記事では、Python と GitHub Actions を活用してパーソナルデータの利用箇所を自動で追跡し、安心・安全なデータマート運用を実現する取り組みをご紹介しました。
今回構築した仕組みによって、パーソナルデータの制限事項を⼿作業で確認する場合の⼯数や⾒落としのリスクを⼤幅に削減し、事業部⾨の利⽤者が安⼼してデータマートを活⽤できる環境を整備することができました。今後も継続的に改善を重ねることで、より良いデータガバナンス体制の構築を目指していきます。
最後までお読みいただきありがとうございました!