
生産性向上 構造化ドキュメントのすゝめ
この記事は、インフラ開発業務の生産性を高めるべく業務の自動化に取り組んだ物語です。
最近ではAnsibleなどを活用してインフラ作業の自動化[1]を行うことも珍しくなくなっています。私たちの取り組みは、さらに設計工程や開発案件の各工程にまで自動化の取り組みを広げて業務全体の生産性向上を目指そう!というものです。
私たちまず自動化のターゲットに置いたのはいわゆる「コピペ」業務。「コピペ」業務をなくして生産性を高めるために、業務プロセスで作られる大量の自然言語ドキュメントを構造化ドキュメントに変えていくことがいかに大切か、という話をしたいと思います。
自己紹介
何者?
改めてこの記事をお読みいただきありがとうございます。ドコモ サービスデザイン部でspモード[2]のネットワークを担当している川谷です。「spモードって何?」って言われちゃうと悲しくなりますが。。
spモードって何?
実際にご存じない方も多くいらっしゃるので簡単にご紹介すると、スマホ向けのインターネット接続サービスです。え?まだわかりづらい?うむむ。。。プロバイダ、というとわかるかも。皆さんも自宅にインターネット回線を引いている方は、回線(ドコモ光とか)とプロバイダ(ドコモnetとかOCNとか)の両方を契約していますよね?スマートフォンも無線を使う回線の契約(データ通信プラン)とISP契約が存在していて、それがspモードというものです。今、ドコモのスマホ(iPhone含む)をお使いの多くの方々にご利用いただいているサービスで、ユーザは4,000万を超えています(日本一!)。
去年は
こんな記事[3]を書いていました。今回はネットワーク感が全然ないですが本業はネットワーク屋さんです。
何がしたいのか ~TOILとしてのコピペ撲滅
普段の業務(ネットワーク設計や構築のマネジメント、トラブルシューティング)を行うかたわら、もっとチームの生産性を上げる方法はないかな~と日々考えていました(います)。そこで目を付けたのがいわゆるコピペのようなTOIL[4]と呼ばれる単純繰り返し作業です。
案件の工程とドキュメント
私のチームでは、主に下記の2種類の形式のプロジェクトで開発業務を進めています。
| 規模 | 特性 | |
|---|---|---|
| 大規模プロジェクト | 100人日~数千人日規模 | 新規性が高く過去プロジェクトの繰り返しにはならない |
| 小規模案件 | 数人日~100人日規模 | 新規性が低く過去の類似案件の反復になる部分が多い |
後者の「小規模案件」では、上流設計から下流設計、検証、コンフィグ作業、商用作業といった小さいウォーターフォール開発[5]を同時並行で大量にこなしています。上流から下流にプロジェクト進む中で大量のパワポ、エクセルを作ってはレビュを繰り返していきます。
下図が「小規模案件」の工程のイメージです*1です。実際の工程やドキュメントはちょっと違いますが概ねこんな感じ。

その工程、本当に必要?
私たちがこの記事で紹介している生産性向上の取り組みを進める中でふと思いました。本当にこんなに多くの工程、ドキュメントを作る必要あるの?とw
分析を進めると、各工程の中で大量のコピペや、人間の可読性のためのだけのドキュメントが多く含まれてることがわかってきました。
コピペってダメなの?
ダメ、ゼッタイ
なんで?
コピペってその名の通り、ある情報をあるドキュメントから別のドキュメントに転記する行為です*2。この「コピペ」は新しい情報が増えておらず、本質的な価値を生んでいません。ただ、人間がやる以上ミスの温床になったり、それを防ぐためのレビュが行われたり。。いいことは全然ないです。
こういった本質的な情報を産まない「コピペ」業務は品質低下、生産性低下の原因なので避けるべき。やるにしてもプログラムに機械的に実施させるべきなのです。
自然言語ドキュメントと構造化ドキュメント
上で書いた「コピペ」を撲滅する方法の一つとして、人間がやっている「コピペ」をプログラムなどを通じてコンピュータにやらせる方法があります。ミスもしないし「コピペ」やレビュの手間も省けます。
この章では人間にしか解釈できない「自然言語ドキュメント」があるといかに「コピペ」をコンピュータにやらせにくいかを見ていきます。
人間にしか読めないデータ ~自然言語ドキュメント
例えば下の構成図を見てください。旧ファイアウォールを新ファイアウォールにリプレースする際の構成図です(図は実在のものではなく例として作った適当なものです)。こういった図を僕たちは基本設計フェーズでよく作っては案件の概要を理解したり、認識のすり合わせを行ったりします。
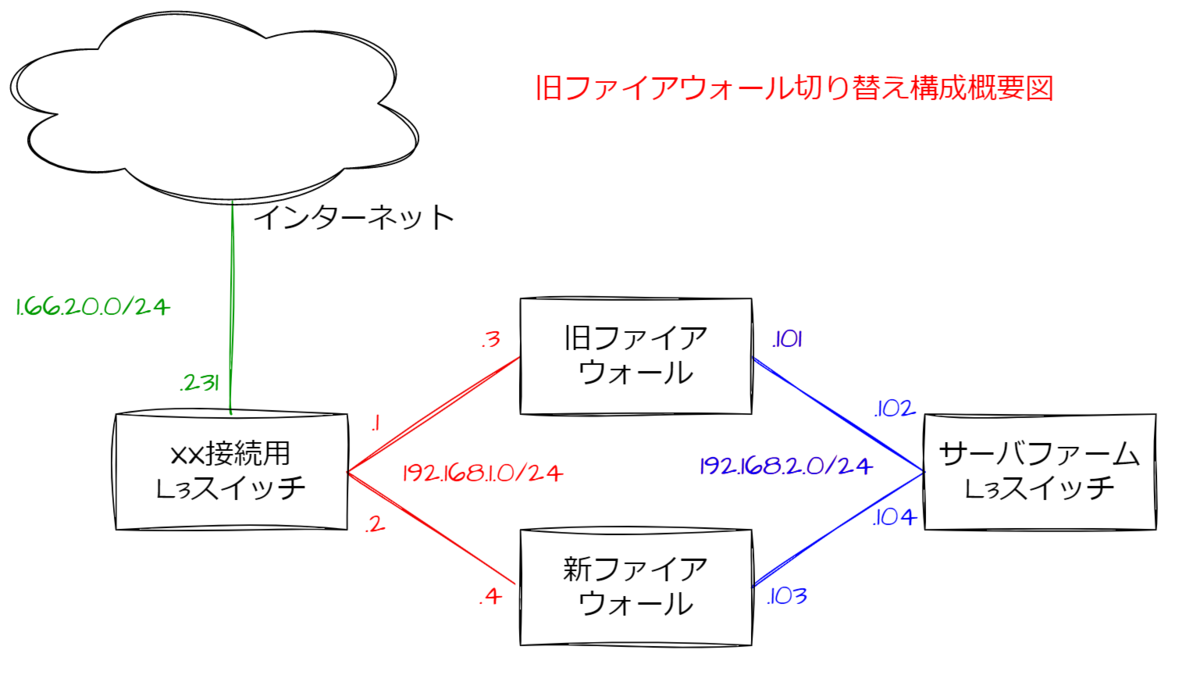
こういった図は、人間が読む分には何の問題もないですが、プログラムに解釈させるのは一苦労*3。このような、人間が解釈する分には問題ないけどプログラムに解釈させるのは難しいドキュメントを僕たちは「自然言語ドキュメント」と呼んでいます。具体的に見ていきます。
図と文字の位置関係が意味を持っている
人間が見れば左上の雲がインターネットでxx接続用L3スイッチとつながっていて、そのIPアドレスは166.2.0.231なんだってわかります。これをプログラムに解釈させようと線の意味とか図とテキストの位置関係の意味とかすべて厳密に定義してコーディングしなければならず大変です。
色がわからない
赤い線と数字、人間が見れば「.1」というのはプレフィックス「192.168.1.0/24」の第4オクテットが1、つまり「192.168.1.1」のアドレスがふられているんだなってわかります。 プログラムに理解させるためには色の意味や、その色で書かれた文字列の意味(プレフィックスやアドレスの第4オクテットだよ)を教えておかなければなりません。 ちなみにわざとらしく右上に「切り替え構成概要図」って赤字で書いていますが、これはプレフィックスやアドレスじゃないよ、というのも人間は分かるけどプログラムにはしっかり教えてあげないとダメになります。
コンピュータに優しいデータ ~構造化データ/ドキュメント
構造化されたドキュメント(データ、といった方がよいかも)の典型例の一つがRDBMS[6]ですね。先ほどの構成図の情報量を維持してRDBMSのテーブル化した例が下図です。(もうちっとマシなスキーマにできそうな気もするので本筋ではないのでご愛嬌)

RDBMSがなぜコンピュータに優しいかというと、
- あらかじめどのテーブルのどのカラムになんのデータが入っているのかが決まっている
- データの形式もあらかじめ決められているので表現や形式の揺らぎが無い
このデータを操作するプログラムからしたら、上の前提を置くことができるので安心してデータを扱うことができます。
なぜ人類はコピペをやめないのか
本質的な設計行為を伴わないプロセスの存在
さて、前述の業務フローをもう一度眺めてみましょう。同じく前述の構成図は僕たちの場合大体基本設計フェーズで作成します(フロー図中の方式概要書)。

で、構成図を再度眺めてみると
- IPアドレス
- 作業対象のホスト名
- 接続情報
などが入っています。この資料を関係者で「ふんふん、確かにこの方法でよさそうだね~」と確認して下流工程へ進みます。詳細設計フェーズではこの構成図をもとに「IPアドレス一覧」や「ホスト名一覧」「結線一覧」といったドキュメントの作成、修正を行っていきます。
「ん?それってコピペじゃぁ。。」と気づいた人は鋭い。そう、こうやって上流工程の成果物をインプットに下流工程の設計を進めるんですが、本質的な情報量は増えず、あるドキュメントからあるドキュメントに情報を写してく作業が実はいっぱいあります*4。こういった本質的な情報量の増加を伴わない設計プロセスが存在し、その中でコピペが行われています。
自然言語ドキュメントという敵
本質的な情報量増加を伴っていない設計プロセスは人間がやらずにプログラムに「コピペ」させるか、機械的に生成させられるはず。構成図の中でIPアドレスが決まっているならIPアドレス一覧に勝手に埋めてよ、と。なぜこれができないかというと、先に書いた「自然言語ドキュメント」のせいです。
先ほど掲載した構成図は自然言語ドキュメントです。なので、ここで一度決めたIPアドレスなどの情報をプログラムに抽出させて後工程のドキュメントを自動生成、なんてことができないのです。
目指している方向性
自然言語ドキュメントを撲滅すればコンピュータに機械的に「コピペ」業務をさせることができるようになります。ただ、すべてのドキュメントをRDBMSに放り込んで構造化されたデータにする、というのも現実的ではなく。。そこで、コンピュータが機械的に処理できるいい塩梅の構造化まで持っていくことはできないでしょうか。
今僕たちは下図のような2つの方向性、特にまずは①の方向性を目指して議論を行っています。

方向性① ドキュメントを構造化しよう
図は主観的なものですし使い方にもよりますが、横軸に構造化のレベルを置いて僕たちがよく使うドキュメンテーションツールをマッピングしています*5。
RDBMSはかなり構造化されているので一番右に、パワポは好き勝手にどんな資料でも自由に作れてしまう分、人間にしか解釈できないドキュメントを量産できてしまうので左の方に。Confluence[7]もかなり自由度が高いものの、使用できるマークダウンには縛りがありますし、格納されたフォーマットはXHTML(的なもの)になっているのでパワポよりは右に配置しています。
方向性①は、この図のコンピュータに処理させられるか/られないかの「分水嶺」より左にあるドキュメントをいかに➡に変えられるか、です。例えばこのConfluenceで描いた表を見てください。パッと見そこそこきれいで、かつ後述しますが結構簡単にコンピュータに処理させることができます。(どうやって処理できるかはおまけに書いておきますね。)こんな風に、かつ均質にドキュメントをまとめられるとだいぶ構造化が進みます。

じゃあどうやってやんのよ、という話です。特に私たちのように100人以上で進めているプロジェクトで上のような表を均質に作るのはとても厄介です。
ルールで縛る
ホスト名の表は左から順に「ホスト名」「機種」「設置拠点」を書け、設置拠点は次一覧から選べ。例えば「山王パークタワー」と書いてもいいけど「山王PT」とは書くなよ、みたいな。わかりやすくていいんですが、これははっきり言ってうまく行かないです。プロジェクトの規模が大きくなると絶対守らない人が出てきますし、ルールを守っているかをレビュしたり監査したり。。なんてことを始めると本末転倒。。
ルールを作ること自体は否定しませんが、ルールだけでどうにかなるとは思わない方がいいです。ポイントはこの後の2つのように、使う側にインセンティブがある方法を使う点だと思います。
テンプレで揃える
私たちは最近、ドキュメンテーションにConfluenceを使うことが増えています[8]が、Confluenceにはテンプレート機能があります。その機能を使って、「方式概要書」のテンプレートをあらかじめ用意。ホスト名の表を用意しておけば、ドキュメントを作る側からするとベースがあるので楽だし、自然と構造化された書式で揃うようになります。
ドキュメント自動生成で揃える
(これが一番言いたかったやつ)
例えば「ホスト名」の表。ホスト名だけ入れれば本来機種と設置拠点は自動的に決まります。これを例えば機器データベースから自動的に引いてきて補完してあげるようにします。すると、ドキュメントを作る人はいちいち自分で調べて埋めなくてもよいし、自動的に埋まる機種や設置拠点に表記ゆれや記入間違いを起こすこともなくなるというわけです。
僕たちのチームでは実際にSlack[9]のショートカットでConfluenceのページをテンプレートから自動生成、ページ内のホスト情報などの自動補完なども実装して活用しています。

方向性② コンピュータで非構造化ドキュメントを扱えるように
こちらはまだいろいろ考え中。紙面の都合もありますし詳細についてはまた次の機会に譲ることにして簡単にだけ。要するに、ドキュメントを書く側がコンピュータに優しいような構造化ドキュメンテーションを心がけるだけでなく、コンピュータの側も少しは非構造化ドキュメントを理解できるよう、賢くできないものか?という話です。
自然言語解析の研究は昔からなされていますし、非構造化データをAIなどを駆使して解析しビジネスに役立てようという取り組み[10]も多数行われています。そういった取り組みを参考にしながら、少々構造化が緩いドキュメントなどもコンピュータで解釈して処理できるようにしたいな~などと考えています。
じゃあ業務を自動化しようぜ ~作業承認プロセス
僕たちが手始めに取り組んだのは作業承認プロセスの自動化です。他にもいっぱい自動化しようと思っていますがこの記事ではそのご紹介を。こんな仕組みで作っています。

細かくは説明しませんが、自動化の業務フローの入り口は基本すべてSlackになっています。日々Slack上でコミュニケーションをとる流れでそのままドキュメント作成につながるようになっています。情報は適宜Confluenceに書き込んでいますが、ConfluenceはRDBMSのようながちがちの構造化はなされず、表やその項目、タイトルの付け方などが決まっているだけの緩い感じですが、テンプレからの生成や、自動投入の仕組みを駆使することで構造化が崩れにくいような工夫をしています。
ポイントは、作業概要の執筆をSlackからの自動生成と担当者による執筆両方で行っている点。RDBMSみたいにガチガチな構造化データだとこういうわけにはなかなかいきません(まさかSQL手入力する人もいませんしね。。)。これはCofluenceが緩い構造化がされつつも人間が読んだり編集できる形式で保たれているからできていることです。
おまけ ConfluenceページのParse
ConfluenceのページをParse(構文解析)するのも大変だろ!と時々指摘されるのでちょっとだけParse方法をご紹介。ここを見てもらうと、僕がなぜConfluenceをパワポより構造化レベルが高いところに位置付けたか理解してもらえると思います。
例えば下の表。

この表を含むConfluenceの中身を取得するとこんなXHTML分が返ってきます。
<h1>ホスト名</h1> <table> <!-- 表の中身 --> </table>
下のコードでこの表をConfluenceのXHTML(的なもの)から取得できます。コメントを入れてわずか14行! やっていることは要するに
<table>タグを探す- 直前のノードtextノードを取得する(表の直前にタイトルを入れる必要があるけどまぁよくやるよね)
- マッチしたら
<table>ノード配下を丸ごと返す
だけです。textノードで取得しているので<h1>でも<h2>でも<p>タグでもよいのでテーブルの直前にタイトルさえ入れてくれれば取得できます。
fun getTable(title: String): TableEditor? { // tableタグを探す val tables = xmlDocument.getElementsByTagName("table") for (i in 0 until tables.length) { val table = tables.item(i) // tableタグの一つ兄兄弟のノードを探す val bigBrother = table.previousSibling // text要素を取得し、引数と比較。一致したらそのノードを返す。 if (bigBrother.textContent == title) { return TableEditor(table, this) } } return null }
これだけです。表の中身はで構造化されているのでそれも結構簡単に解析できます。表の中に表をネストしたり複雑なことをやり始めると大変ですが、そんな必要があること自体稀なので禁止しちゃえばいいんですね(テンプレで縛れる)。
さらに戦いは続く
この記事でご紹介した作業概要の自動生成、作業承認フローの自動化は手始めです。ここでご紹介したような方法でドキュメントの構造化が進めば、さらにこれまでコピペを繰り返していた作業の自動化を進められるのではないかと期待しています。実は上流工程ドキュメントからの設計情報、投入Configの自動生成、自動補完なども一部着手していたり。それらの取り組みも今後チャンスがあればご紹介させていただこうと思います。
参考文献
[1] レガシーシステムのインフラ作業自動化してみた!, Qiita NTTドコモ R&D advent calendar 2021 2日目 リンク
[2] spモード リンク
[3] GAFAMとも違う、別のロードバランサスケールアウト方式導入してみたお, Qiita NTTドコモ R&D advent calendar 2021 5日目 リンク
[4] 日本企業が放置してきた「Toil」のもたらす問題, ZDNetJapn リンク
[5] ウォーターフォールモデル, wikipedia リンク
[6] 関係データベース管理システム, Wikipedia, リンク
[7] Confluence, Atlassian, リンク
[8] 30,000人の従業員がOktaを活用し、スムーズに働き方を転換するNTTドコモ, Okta, リンク
[9] Slack でインフラストラクチャと文化を変革する NTT ドコモ, Slack, リンク
[10] 非構造化データは「宝の山」! 構造化しAI活用するにはどうすればいい? DATAFLUCTとFastLabelの場合, Ledge.ai出張所 リンク
*1:実際の私たちの工程はちょっと違いますが、あくまでもイメージ
*2:ここでいう「コピペ」は必ずしもCtrl+C/Ctrl+Vでコピペする行為に限らず、人間が目で見て多少の形式変換を行って転記する行為も含んでいます
*3:もちろんパワポはこの図が描かれたファイルを読み込んで画面に表示することができるので、そういう意味ではコンピュータはこの図を理解はしています。ただ、図として表示しているにすぎず、図の意味については理解していない、という意味です
*4:ここでは文字通りCtrl+C/Ctrl+Vでコピペするものに限らず、情報量を増やさずに形式や対象のファイルだけ変えて情報を写していく行為も含めて「コピペ」と呼んでいます
*5:JiraやRDBMSはドキュメントとは言わないかもしれませんがここでは広義のドキュメントとして扱っています