
はじめに・自己紹介
NTTドコモ データプラットフォーム部(以下DP部)の矢野です。
NTTドコモではデータを駆使した様々なサービスを取り入れることでサービス価値の向上を目指しています。そのためにDP部ではModern Data Stackといわれるツール群の導入を行うことで、最先端のデータ活用を行うための基盤整備を行っています。
Modern Data StackについてはFivetranのページを参照してください。 www.fivetran.com
データ活用において使いやすいデータ準備は永遠の課題であり、ドコモでもデータ整備の取り組みは日々行っています。
データ整備の取り組みの中でも本記事ではModern Data Stackツール群の中でも話題なELT/ETLツールであるdbtの活用について、具体的にどのようなアーキテクチャでこれを活用しているかを紹介します。
プロジェクトの前提
本プロジェクトの前提として以下2点がありました。
- dbt-coreの利用
- dbt Cloudは有償であることからOSSであるdbt-coreの活用から始める
- dbtの実行環境として、既にネットワーク接続が確保されている社内のAWS環境を利用する
プロジェクトの独立化・ドキュメントサーバの共通化
まず私たちは各dbtプロジェクトが他のプロジェクトに影響を受けないように、それぞれ独立したリポジトリで運用する方針を採用しました。これは、現在複数のプロジェクトでSnowflakeを対象に、SageMakerからJupyterノートブックで処理を実行し、それぞれのプロジェクトが異なるメンバーやリポジトリを使用しているためです。また、これらのプロジェクトのワークロードが今後増加する可能性も考慮しました。
一方、ドキュメントサーバーについては、運用コストを抑えるために共有化する方針を採用しました。これにより、各プロジェクトが一貫性と再現性を保持しつつ、運用の手間やコストも削減できます。
実現したかったこと
- dbtプロジェクトをそのまま実行用ECSにクローンすることで、コードの再現性を担保する。
- dbtプロジェクトの独立性を高めるために、リポジトリごとにプロジェクトを分割する。
- データサイエンティストやデータエンジニアが簡単にパイプラインを作成可能にし、基盤管理者のタスクと分割する。
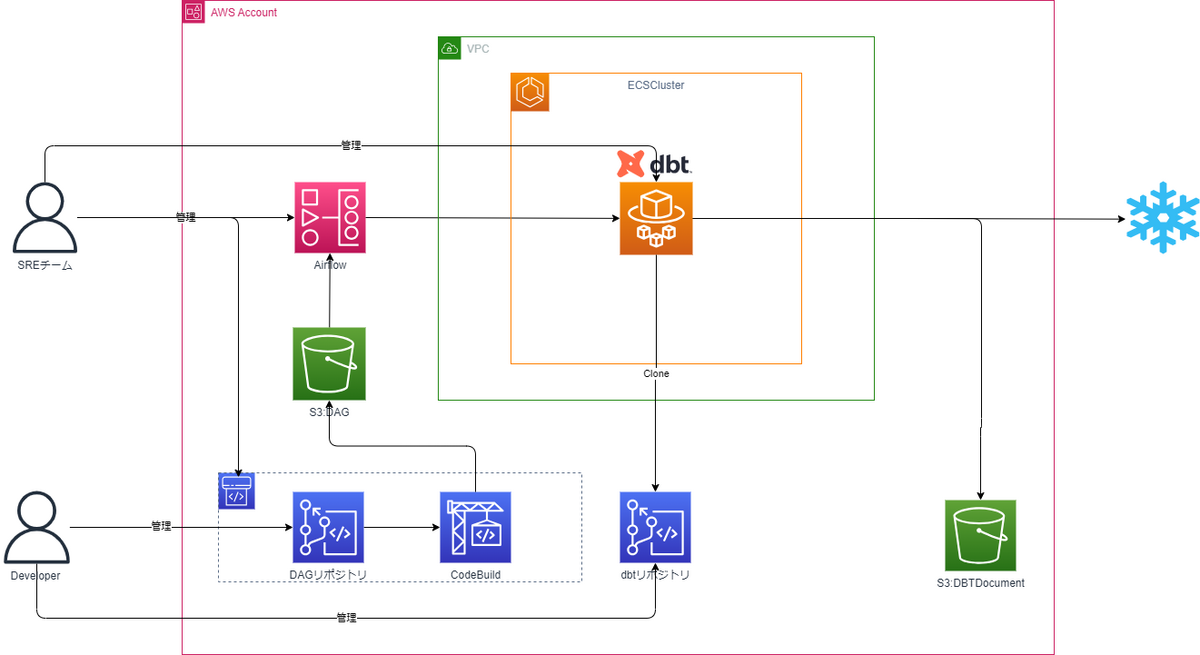
dbtプロジェクトの再現性
今回はこの問題に対応するため、dbt-coreの入ったコンテナイメージを用意しています。Airflowからこのイメージを使用してコンテナを起動させることでdbt環境をコンテナベースで提供することができ、意図しない構成変更によるエラーを防いでいます。
最低限必要なパラメーターをデータエンジニアが記載すれば簡単に自動実行できるテンプレートファイルを用意することで、データエンジニアの利用ハードルを下げています。こちらのテンプレートは引数すべてを使用する必要ないdbtコマンドの実行の場合でも問題なく動作するようになっているため、環境に合わせた実行が可能です。
#ECSのスペックを設定する #CPU 256~512 CPU = 512 #Memory 2048~8192 MEMORY = 2048 #Excution params REVISION='LATEST'#タスク定義のリビジョン番号を指定する EXECUTE_FILE_BASE_PATH='xxxx/xxxx'#リポジトリ内のdbtプロジェクトのパスを指定する CODECOMMIT_REPO_NAME = "xxxx-repository"#クローンするリポジトリ名を指定する DWHNAME='xxxx'#対象のデータウェアハウスを指定する BRANCH="xxxx"#クローンするリポジトリのブランチ名を指定する SELECTOR="xxxx"#dbtコマンドを実行する際のselectを指定する VAR="unique_id: xxxx"#dbtコマンドを実行する際のvarを指定する EXCLUDE="xxxx"#dbtコマンドを実行する際のexcludeを指定する TARGET="dev|prd"#dbtコマンドを実行する際のtargetを指定する
引用元・参考
https://docs.getdbt.com/guides/legacy/best-practices
dbtプロジェクトの独立性
現在dbtプロジェクトはdbt用のリポジトリを作成して管理をしていますが、これはMWAAとECSを利用することで、特定のdbtリポジトリだけではなく、任意のdbtリポジトリに対して動作するようにしています。
dbtプロジェクトは本来他に選択肢がない場合や、複雑な回避策が必要にならない限り、一つのリポジトリで作成することがベストプラクティスですが、今回は分割可能な構成での実現を目指しました。その理由は以下の点です。
- 全社向けのプロジェクトとして管理する場合、関係者が増えるにつれて、プロジェクトを一つのリポジトリで管理することが困難になる可能性があるため。
- メンバーによってスキルセットに差があるため、他のdbtプロジェクトを壊させないため。
import os import subprocess import argparse #Global Variables LOCAL_TEMP_PATH = '/home/jovyan/temp/' # dbtコマンドを実行する関数 def exec_subprocess( dbt_base_path:str, selector:str, var:str, exculde:str, target:str, ) -> None: print(f"execSubprocess started with dbt_base_path={dbt_base_path}, selector={selector}, var={var}, exculde={exculde}, target={target}") # dbt コマンドを生成する # 前後に空白を入れないと動作するコマンドとして認識されない try: command = f"dbt run --profiles-dir {dbt_base_path} --project-dir {dbt_base_path}" if selector: command += " --select " + selector if var: command += " --vars '" + var + "'" if exculde: command += " --exclude " + exculde if target: command += " --target " + target # 実行するdbtコマンドをCloudWatchLogsに出力する print(command) # dbtの追加パッケージをダウンロードする result = subprocess.run(['dbt', 'deps'], check=True, capture_output=True, text=True) print(result.stdout) # dbtコマンドの実行 result = subprocess.run(command, check=True, capture_output=True, text=True, shell=True) print(result.stdout) except Exception as e: print(e) return None # Codecommitからdbtプロジェクトが入っているリポジトリをクローンする def repo_clone( repo_name:str, branch:str ) -> None: # branchを指定してリポジトリをクローンする try: subprocess.run(['git','clone','-b',f'{branch}',f'codecommit::ap-northeast-1://{repo_name}',LOCAL_TEMP_PATH], stdout=subprocess.PIPE,check=True,timeout=120) except subprocess.CalledProcessError as e: print(f"repoClone exception: {e.output}") print(e) print("repoClone ended") return None if __name__ == '__main__': # DAGから渡される引数を取得する parser = argparse.ArgumentParser() parser.add_argument('--CODECOMMIT_REPO_NAME') #dbtプロジェクトのリポジトリ名 parser.add_argument('--EXECUTE_FILE_BASE_PATH') #dbtプロジェクト内の実行パス parser.add_argument('--BRANCH') # リポジトリのクローンで自邸するブランチ名 parser.add_argument('--SELECTOR') #dbtコマンドで使用するselect parser.add_argument('--VAR') #dbtコマンドで使用するselect parser.add_argument('--EXCLUDE') #dbtコマンドで使用するexclude parser.add_argument('--TARGET') #dbtコマンドで使用するtarget # DAGから渡された引数を各変数に代入 args = parser.parse_args() SELECTOR = args.SELECTOR CODECOMMIT_REPO_NAME = args.CODECOMMIT_REPO_NAME EXECUTE_FILE_BASE_PATH = args.EXECUTE_FILE_BASE_PATH BRANCH = args.BRANCH VAR = args.VAR EXCLUDE = args.EXCLUDE TARGET = args.TARGET #dbtが実行されるパスを作成 DBT_BASE_PATH = f'{LOCAL_TEMP_PATH}{EXECUTE_FILE_BASE_PATH}' try: repo_clone(CODECOMMIT_REPO_NAME,BRANCH) os.chdir(f'{LOCAL_TEMP_PATH}{EXECUTE_FILE_BASE_PATH}/') exec_subprocess( dbt_base_path=DBT_BASE_PATH, selector=SELECTOR, var=VAR, exculde=EXCLUDE, target=TARGET ) except Exception as e: print(f"main exception: {e}") raise(e)
引用元・参考
https://docs.getdbt.com/guides/legacy/best-practices
https://docs.getdbt.com/guides/best-practices/how-we-structure/6-the-rest-of-the-project
ドキュメントサーバの共通化
dbtプロジェクトを分割可能にした場合、dbtドキュメントもdbtプロジェクトの数作成されますが、リポジトリの増加に合わせてドキュメントサーバも増加させていくことは現実的ではありません。そこで以下を実現しました。
実現したかったこと
- dbtドキュメントが作成されたら自動的にドキュメントサーバを更新する。
- 一つのECSを複数dbtプロジェクトのドキュメントサーバとして稼働させる。
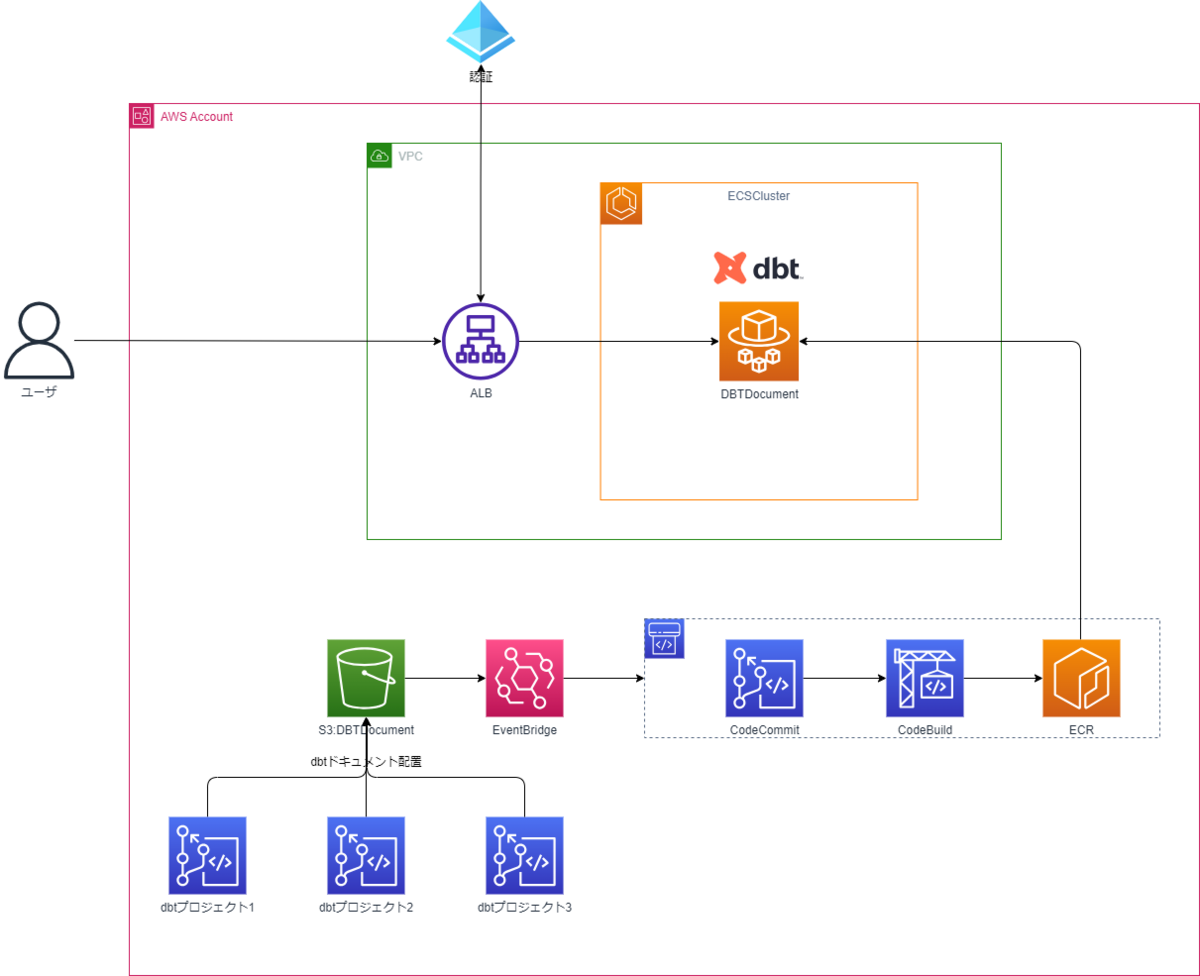
dbtドキュメントサーバの自動更新
dbtドキュメントが作成され、S3に配置されたタイミングでCodePipelineを起動させコンテナイメージを更新することを実現しました。
dbtドキュメントサーバの共通化
一つのドキュメントサーバで複数のdbtドキュメントを管理するため以下のように管理をしています。
- dbtドキュメントを作成する際は、S3にリポジトリ名をパスとして以下のように配置する。
- s3://bucket/repository_name/dbtdocument_resources
- コンテナイメージを更新する際はdbtドキュメント用S3の内部のパスがリポジトリごとに分かれているが、すべてのリポジトリのドキュメントを取得して、コンテナイメージを更新する。
- ECSで利用するコンテナのベースイメージではNginxの公式イメージを利用し、存在するリポジトリのパスであればアクセス可能にする。
工夫した点
- ECS内でdbtの柔軟なコマンドが実行できるようなコードを用意
- DAGのテンプレートを用意し、データサイエンティストのパイプライン作成を容易
- EventBridge*CodePipelineを利用し、各リソースの連携を自動化することで不要な手作業の削減・サイクルの高速化
あとがき
今回は検証も兼ねたdbtの導入ということで、構成の変更が求められても問題ないように、各コンポーネントは疎結合にして、別のサービスに入れ替えることも容易にしています。それはもし今後規模を拡大していくことがあった場合タスク管理を行うツールがMWAAでよいのかであったり、dbtCloudが導入された場合にdbt-coreとdbtCloudの役割をどのように分けるかなどいろいろな可能性があるためです。またdbtはSnowflake以外の他のMDSの技術とも親和性高く、今後新しい要件が発生した際も柔軟に対応できるようになっています。今後も常に変化するニーズに合わせて柔軟に技術を選択できるよう、様々な技術にアンテナを貼って、アーキテクチャを更新していければと思います。