
1. はじめに
NTTドコモ データプラットフォーム部の田中です。私たちのチームでは、社内のデータ活用を加速するためにSnowflakeの新機能検証を進め、データ利活用の体験向上を目指しています。
近年、プロダクト改善や顧客体験の向上においてお客様の声などのテキストデータの活用は不可欠です。 定量指標では捉えづらい不満や期待は、テキストの中に埋もれがちで、担当者が素早く意図にたどり着ける検索・要約体験が求められます。 一方、従来のキーワード中心の検索では、言い回しの揺れ等により、課題を拾い切れない・別の課題が混ざってしまうという課題がありました。
この課題に対し、SnowflakeのマネージドAI/MLであるCortex Searchを用い、セマンティック検索とSnowflakeのCOMPLETE関数を組み合わせたRAGによる対話型検索を検証したので、その内容を紹介します。 狙いは、担当者が自然文で質問し、関連する声を根拠とともに横断的にたどれる体験を、Snowflake上で簡便かつ運用しやすく実現できるかを確かめることです。
なお、本記事の掲載の取組については、株式会社シイエヌエスの支援メンバーである小倉さんに検証を進めてもらっており、以下は小倉さんに執筆いただいています。
2. Cortex Searchについて
2.1 概要
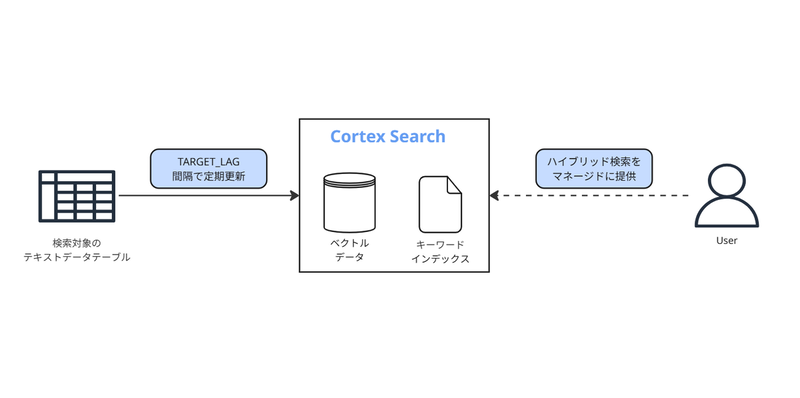
Snowflake Cortex SearchはSnowflakeのAI機能の1つです。Snowflakeのテーブルの文字列カラムに対する自然言語検索を可能とします。1
主な特徴は下記の通りです。
ハイブリッド検索: 「意味的に」似たテキストを検索するベクトル検索と、「単語の一致」で検索するキーワード検索を組み合わせてテキストを検索
フルマネージド: いくつかのパラメータを指定してSQLコマンドを実行するだけで作成でき、ベクトル化(Embedding)、検索のためのインデックス作成や更新は自動で行われる
高速: 大量のテキストに対して200~300ミリ秒でクエリを実行する
2.2 ユースケース
Cortex Searchの主なユースケースは下記の通りです。
- テキストのあいまい検索: Snowflakeに蓄積された数万レコードのテキストデータから類似するものを検索する
- RAG構築: ドキュメントやナレッジベースに対して自然言語で検索し、LLMで正確な回答を得る
3. 検証 RAGによる対話型検索
3.1 目的
単に検索結果をリスト表示するだけでなく、利用者の質問に対して自然言語で要約した回答を返す対話型の検索機能を想定した検証を行います。
「料金プランに関する不満点を要約して」のような抽象的な指示にも対応できる、より高度なユーザー体験を目指します。
3.2 実装方法
回答生成
下記手順で、アプリ利用者の質問に対する回答を生成します。
- COMPLETE関数を実行し、「質問に対する回答を得るためにハイブリッド検索システムに入力すべき検索文字列」を生成する
- Cortex Search Serviceを検索し、回答生成に必要な情報を取得する
- 検索結果をコンテキストとして埋め込み、質問に対する回答を得るためのプロンプトを生成する
- COMPLETE関数を実行し、生成したプロンプトに対する応答を質問への回答とする
※ 本検証では、自由記述形式のお客様フィードバックを模したダミーデータを使用しています。
実際のコードは下記のとおりです。
Python Snowflake APIを用いて、COMPLETE関数やCortex Searchを実行します。
Pythonコード(実装詳細)
import json from snowflake.core import Root from snowflake.cortex import complete, CompleteOptions from snowflake.snowpark.context import get_active_session session = get_active_session() # アクティブなSnowpark Sessionを取得 user_input = 'dカードのサービス改善のアイデアを出してほしいです。' # 利用者からの入力 model_name = 'mistral-large2' # COMPLETE関数のモデル名 # 1. COMPLETE関数を実行して、検索文字列を取得する search_text_prompt = [ { 'role': 'system', 'content': ( 'あなたはNTTドコモのお客様の声を分析するアプリ用の検索文字列を生成するAIアシスタントです。' 'ドコモ社員であるアプリユーザから、任意の質問が入力されます。' '「その質問に対する回答を得るために検索システムに入力すべき文字列」を生成してください。' '検索システムは、キーワード+ベクトルのハイブリッド検索に対応しています。' ), }, # Few-Shot prompting { 'role': 'user', 'content': 'ユーザからの質問: d払いについてどのような不満の声が上がっていますか?' }, { 'role': 'assistant', 'content': 'd払いに関して不満を感じたユーザの声' }, { 'role': 'user', 'content': 'ユーザからの質問: 回線速度が遅いというフィードバックは、どのような場所についてよくされていますか?' }, { 'role': 'assistant', 'content': '通信速度が遅いと感じたエリアについてのユーザの声' }, { 'role': 'user', 'content': user_input }, ] search_text_response_format = { 'type': 'json', 'schema': { 'type': 'object', 'properties': { 'search_text': { 'type': 'string', 'description': '質問文' }, }, }, 'required': ['search_text'], } search_text_options = CompleteOptions( response_format=search_text_response_format ) # CortexSearchに渡す検索文字列を生成 search_text_result = complete( model=model_name, prompt=search_text_prompt, options=search_text_options, session=session, ) search_text = json.loads(search_text_result)['search_text'] # 2. 検索処理を実行する root = Root(session) service = ( root .databases['MY_DATABASE'] .schemas['MY_SCHEMA'] .cortex_search_services['CUSTOMER_VOICE_SEARCH_SERVICE'] ) search_results = service.search( query=search_text, columns=['VOICE_TEXT'], limit=30 ) # 3. コンテキストを埋め込んで、プロンプトを生成 context = '\n'.join( [result['VOICE_TEXT'] for result in search_results.results] ) content = f''' 質問と、それに関連するお客様の声テキストデータを提示します。 提示したお客様の声に基づき、質問に対する回答を生成してください。 # 質問 {user_input} # お客様の声 {context} # 回答フォーマット - answer: ユーザからの質問に対する回答 - reason: この回答を提示した理由(このような回答をしたのは、xxxのようなお客様の声があったためです) ''' # 4. Complete関数を実行して、回答を取得する answer_prompt = [ { 'role': 'system', 'content': 'あなたはNTTドコモのお客様の声から課題や傾向を分析し、サービス改善を助けるAIアシスタントです。', }, { 'role': 'user', 'content': content }, ] answer_response_format = { 'type': 'json', 'schema': { 'type': 'object', 'properties': { 'answer': { 'type': 'string', 'description': 'ユーザからの質問に対する回答' }, 'reason': { 'type': 'string', 'description': 'ユーザからの質問に対する回答の根拠' } }, 'required': ['answer', 'reason'], }, } answer_options = CompleteOptions( response_format=answer_response_format ) answer_result = complete( model=model_name, prompt=answer_prompt, options=answer_options, session=session, )
本実装では、COMPLETE関数の精度を高めるために以下の工夫を行いました。
- Few-Shot Prompting: 検索文字列生成時に具体的な入出力例を提示することで、期待する形式の出力を安定的に得られるようにしました。
- 構造化出力(response_format):
response_format引数により出力フォーマットを指定することで、LLMの応答を確実にパースできる形式で取得しています。
これらの工夫を行わない場合、検索文字列が冗長になったり、回答が期待する形式にならないケースが多く見られました。
3.3 結果
- 利用者からの入力:
回線に関する苦情は、どのような場所で多く発生していますか? - 検索文字列:
回線に関する苦情 場所 多く発生 - 回答:
回線に関する苦情は、自宅(特に集合住宅や戸建て)と職場で多く発生しています。特に、東京都、茨城県、愛知県、栃木県、千葉県、埼玉県、神奈川県、兵庫県、大阪府、福岡県、熊本県などの地域で苦情が多いです。また、特定の交通機関や駅周辺でも通信が困難な場所が報告されています。 この回答を提示した理由は、以下のようなお客様の声があったためです。 - 自宅(集合住宅1階)での通話・通信の問題 - 自宅(集合住宅階)での通話・通信の問題 - 自宅(戸建て階)での通話・通信の問題 - 職場(その他階)での通話・通信の問題 - 職場(戸建て階)での通話・通信の問題 - 特定の交通機関や駅周辺での通信問題 これらの声から、特定の場所や地域での通信問題が顕著であることがわかります。
3.4 考察
Cortex Searchによるハイブリッド検索とCOMPLETE関数を組み合わせることで、利用者からの入力に関連するお客様の声を抽出し、回答生成までつなげることができました。
特に、以下の3点が印象的でした。
- 検証環境の構築からPoC実装までわずか1日で完了できた点。Cortex Searchがフルマネージドであり、複雑なインフラ構築や手動でのベクトル化作業が不要なため、迅速に検証を開始できました
- ハイブリッド検索により、「明確なキーワード」と「曖昧・言い換え表現」の両方に強いコンテキスト抽出が可能だった点
- COMPLETE関数を使って検索クエリや回答プロンプトを柔軟に生成することで、ユーザの抽象的な問いに対しても的確な回答ができた点
今後の展望として、下記のような改善が考えられます。
- ユーザ属性や文脈に応じた動的クエリ生成(「誰が・何の目的で検索しているか」)
- 検索クエリのパターン蓄積とテンプレート化(COMPLETE関数の安定化)
- 検索結果のスコアリング(Numeric boostsやTime decaysによる検索結果のランキング調整)
- 検索結果の要約粒度コントロール(COMPLETE関数で回答長やフォーマットを制御)
- 東京リージョンで未提供のより高性能なモデルの活用(回答精度の向上)
4. おわりに
本記事では、Snowflake Cortex Searchを活用し、社内アプリにおけるテキスト検索の高度化に向けたPoCの取り組みをご紹介しました。
Cortex SearchにCOMPLETE関数を組み合わせることで、ユーザの自然文による抽象的な問いに対しても、意味の通った対話的な検索体験を提供できる可能性が見えてきました。
本PoCで扱ったデータは一般的なRAGのユースケース(例:社内規程検索、FAQチャットボット等)とは異なり、自由記述のお客様の声という表現のばらつきが大きいデータでした。それでも、Cortex Searchの柔軟な検索能力は十分なパフォーマンスを発揮することが示されました。
Cortex Searchはコスト構造が複雑なサービスであり、導入に際しては費用対効果も重要です。コストを抑えて利用する方法についても、別の機会に執筆したいと思います。
最後までお読みいただき、ありがとうございました。