
- はじめに
- 全体像
- 動作環境
- AWS CLI環境設定時のつまずき
- DataFrame取得・加工処理でのつまずき
- Athena(およびawswrangler)作業時のつまずき
- おわりに
- おまけ
- 参考にさせていただいたサイト
はじめに
本記事はNTTドコモ R&D Advent Calendar 2022カレンダー2の20日目の記事になります。
株式会社ドコモ・インサイトマーケティングの鈴木(里)です。 モバイル空間統計®*1での位置情報データの分析に携わっています。
先日、社内のデータベースからAWS*2のAthena*3にデータを送る必要がありました。
その中で様々なつまずきがあったため、ここに事象と対処をまとめたいと思います。
全体像
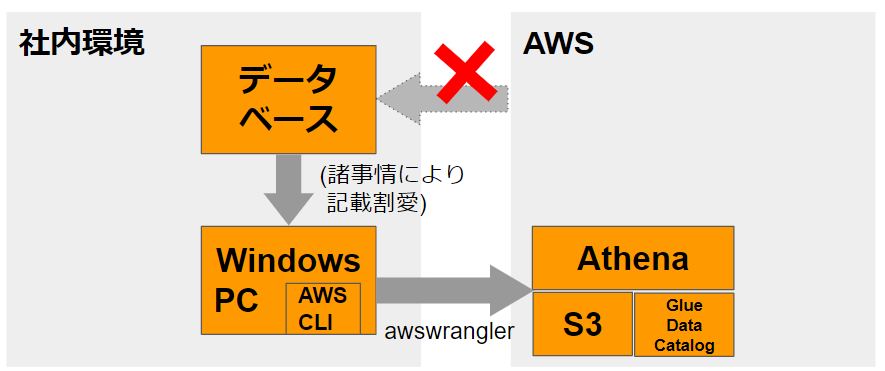
プログラミング言語はPythonを使用します。
やっていることは下記の3つです。
(1) データベースからデータをpandas.DataFrame*4形式で取得(今回は割愛)
(2) ローカルPCでDataFrameを適宜加工
(3) AWS SDK for pandas(awswrangler)*5を用いてAthenaにテーブル作成
- AWSへの接続に必要な認証情報/コンフィグはAWS CLI*6の名前付きプロファイル*7で指定
動作環境
Windows10
Python3.10.4
aws-cli/2.7.31
AWS CLI環境設定時のつまずき
AWS CLIは以下のサイトなどからインストールすることができます。
複数のAWS環境につなぐ必要がある場合は環境ごとに「名前付きプロファイル」を作って使い分けをしているのですが
ここで最初のつまずきがありました。
「C:\Users\ユーザ名」のパスが悪さをする
■事象
Windowsの場合、AWS CLIに関する認証情報やコンフィグはおそらく「C:\Users\ユーザ名\.aws」フォルダ配下に配置されますが Windowsのユーザ名によっては困ったことになります。
例えばユーザ名が「田中 太郎」だった場合、上記フォルダは「C:\Users\田中 太郎\.aws」になりますが、 フォルダパスにスペースが含まれてしまいます。
するとPython等から名前付きプロファイルを読み込もうとした際、エラーになってしまうことがあります。
「C:\Users\ユーザ名」のフォルダパスはWindows側でユーザ名を変えてもそのままなので、 別のユーザを作成してそちらで作業する...ということができない環境の場合、困ったことになります(なりました)。
input
import awswrangler as wr import boto3 session = boto3.Session(profile_name='my_profile_name') # 自分で作成した名前付きプロファイルに置き換える # Athenaのdatabase一覧を取得 databases = wr.catalog.databases()
output
raise NoRegionError()
botocore.exceptions.NoRegionError: You must specify a region.
→regionをコンフィグで指定していてもNoRegionError
output2
(os.environ['AWS_DEFAULT_REGION'] = 'ap-northeast-1'等でregionを指定した場合)
raise NoCredentialsError()
botocore.exceptions.NoCredentialsError: Unable to locate credentials
→認証情報ファイルはあるのにUnable to locateエラー
■対処
事象発生時は気づかなかったのですが、冷静に考えると認証情報やコンフィグを別の場所に移せばこの事象を回避できそうです。
.awsフォルダごと別の場所に移すことでこれを回避していきます。ここではCドライブ直下に移してみます。
認証情報とコンフィグのパスは、下記の環境変数で指定することができます。
AWS認証情報のパス:AWS_SHARED_CREDENTIALS_FILE
AWSコンフィグのパス:AWS_CONFIG_FILE
スタートメニュー→envで検索→システム環境変数の編集→環境変数 から、下記の通り設定していきます。
変数名:AWS_SHARED_CREDENTIALS_FILE、変数値:C:\.aws\credentials
変数名:AWS_CONFIG_FILE、変数値:C:\.aws\config

※環境変数を再読み込みさせるため、一度PCを再起動したほうがいいかもしれません
無事、名前付きプロファイルを読み込めるようになりました!
input
import awswrangler as wr import boto3 session = boto3.Session(profile_name='my_profile_name') # 自分で作成した名前付きプロファイルに置き換える # Athenaのdatabase一覧を取得 databases = wr.catalog.databases() print(databases)
output
(データベース一覧のリスト)
※ちなみに私の環境だと、名前付きプロファイルとは別にdefaultのプロファイルを1つ定義しておかないとうまく動きませんでした(credentialsとconfig両方のファイルに書く必要がある)
DataFrame取得・加工処理でのつまずき
暗黙の型変換でつまずきました。
int型のカラムがいつの間にかfloat型に!?
■事象
int型のはずのカラム*8になぜかfloat型のデータが入っていました。 (テストデータでは事象発生しなかったため発見が遅れ、ちょっと焦りました)
調べた結果、初歩的な部分ですが暗黙の型変換が原因だとわかりました。 pandasには「整数の列でも中身に1つでもNULLのデータが含まれる場合、当該カラムをfloat型にする」仕様があり、これに引っかかっていました。
Because
NaNis a float, a column of integers with even one missing values is cast to floating-point dtype
どうやらデータベース上で当該カラムにわずかにNULLのデータが入っており、DataFrameとして読み込んだ際にfloatになってしまったようです。
input
(データベースからデータを読み込む部分は割愛、DataFrameで代用)
import pandas as pd import numpy as np df = pd.DataFrame({'num':[1,np.nan,3],#カラム「num」はintだがNULLが含まれている 'id':['006','005','106'], 'value':[7.0,8.0,np.nan], 'attr':[10,20,30]} ) print(df)
output
num id value attr 0 1.0 006 7.0 10 1 NaN 005 8.0 20 2 3.0 106 NaN 30
→intのはずのnum列がfloatになっている
■対処
いくつか方法がありそうですが、ここでは「NULLを穴埋めしてから対象カラムをint型に指定しなおす」ことで事なきを得ました。
input
import pandas as pd import numpy as np df = pd.DataFrame({'num':[1,np.nan,3], 'id':['006','005','106'], 'value':[7.0,8.0,np.nan], 'attr':[10,20,30]} ) #欠損値を0で穴埋め:この時点ではまだnum列はfloat df['num'] = df['num'].fillna(0) #num列をintにキャスト df['num'] = df['num'].astype(int) print(df)
output
num id value attr 0 1 006 7.0 10 1 0 005 8.0 20 2 3 106 NaN 30
→num列は整数のまま!
Athena(およびawswrangler)作業時のつまずき
pandasを使う際に各種AWSサービスの操作を助けてくれるライブラリ「AWS SDK for pandas(awswrangler)」を使うことでかなり楽ができたのですが、いくつかつまずきがありました。
S3に出力されるparquetファイル名を指定できない
■事象
awswrangler.s3.to_parquet関数を用いると、DataFrameから簡単にAthenaにテーブルを作成することができます。 しかし、データの実体であるS3バケット*9上のファイル*10は以下のようにランダムな名前になってしまいます。
input
import awswrangler as wr import boto3 wr.s3.to_parquet(df=df, # Athenaに出力したいDataFrame ...略... )
output (S3バケット上に生成されたファイル)
99c43cb726fa42f68a1c7b6b899f2f52.snappy.parquet
やむを得ない措置だそうですが、 このままだとファイルが何を示すのかわかりづらいですね。
■対処
ファイル名を完全に指定することは現状できないようですが、 to_parquet関数のfilename_prefixに任意の文字列を渡すことでファイル名の先頭の文字列を指定することができます。
例えば、filename_prefix = 'test_20221201_'と指定した場合のファイル名は下記のようになります。
input
import awswrangler as wr import boto3 filename_prefix = 'test_20221201_' wr.s3.to_parquet(df=df, # Athenaに出力したいDataFrame ...略... filename_prefix=filename_prefix, # ファイル名の頭につく文言 ...略... )
output (S3バケット上に生成されたファイル)
test_20221201_99c43cb726fa42f68a1c7b6b899f2f52.snappy.parquet
データの種類や追加した日などをfilename_prefixに指定することで、ファイルを区別しやすくすることができます。
間違ったファイルを追加してしまった
■事象
ダミーデータでのテスト中に、うっかり同じデータを2回テーブルに追加してしまいました...

■対処
Athenaにあるテーブルの実体は、S3バケットに置かれたデータです。
to_parquet()でAthenaに追加されたデータは、下記のように「.parquet」という形式に圧縮されたファイルとして、S3バケットの指定した場所に配置されています。

したがって、名前や更新日時から「誤って追加されたデータ」を特定できれば、当該データを削除することでテーブルを元の状態に戻すことができます。
(上記の例だとfilename_prefixが全て'test_20221201_'なので、最終更新日時で区別しました)

データ削除後にAthena上で対象のテーブルを見てみると、誤って追加された部分が消えていることを確認できます。

おわりに
新しくコードを書いたり環境を作ったりするときは大抵つまずきがあるものですが、強く生きていきたいですね。
よいお年を。
おまけ
Athena接続部テストコード
import pandas as pd import awswrangler as wr import boto3 from botocore.config import Config # Athena関連設定クラス class AWSSetting() : profile_name = '作成したプロファイル名' # AWS CLIプロファイルを指定 bucket_name = 'my_bucket' # parquetファイル出力先のS3バケット bucket_path = f's3://{bucket_name}/test/' # parquetファイルを置くS3バケットのパス parquet_file_prefix = 'test_20221201_' # parquetファイルの先頭に付与される文字列 athena_database_name = 'test_db' # Athenaの出力先データベース名(≒スキーマ) # Athena関連処理のクラス class AthenaClient(AWSSetting) : # boto3セッション作成およびdatabase準備 def __init__(self): # AWS CLIで設定したプロファイルを指定してsessionを取得 self.session = boto3.Session(profile_name=self.profile_name) # Athenaのdatabase一覧を取得 databases = wr.catalog.databases() # 所望のdatabaseが未作成なら作成する if self.athena_database_name not in databases.values: wr.catalog.create_database(self.athena_database_name) # DataFrameをAWSSettingで指定の宛先に出力 def dataframe_to_athena(self, df, table_name) -> None: to_parquet_mode = '' # 出力先テーブルが存在するならTrue、存在しないならFalse table_exist = wr.catalog.does_table_exist(database=self.athena_database_name, table=table_name, boto3_session=self.session) if(table_exist) : to_parquet_mode = 'append' # テーブルが存在するなら追記モード(append)にする else : to_parquet_mode = 'overwrite' # そうでないなら新規作成モード(overwrite)にする # S3にparquet形式でデータを置きつつAthenaにテーブル作成 wr.s3.to_parquet( df=df, # Athenaに出力したいDataFrame path=self.bucket_path, # 出力されたparquetファイルを置くS3バケットのパス dataset=True, filename_prefix=self.parquet_file_prefix, # ファイル名の頭につける文言 mode=to_parquet_mode, # 新規作成(overwrite) or 追記(append) database=self.athena_database_name, # 出力先のAthenaのdatabase名(≒スキーマ) table=table_name, # Athenaに作成されるテーブル名 # partition_cols=['xxx'] , # パーティションを切る場合に指定。パーティションに使うカラムを指定(xxxにカラム名が入る) boto3_session=self.session ) # テスト用のDataFrameを作成する data = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] df = pd.DataFrame(data, columns=['a', 'b', 'c']) athena_client = AthenaClient() athena_table_name = 'my_table' athena_client.dataframe_to_athena(df, athena_table_name)
参考にさせていただいたサイト
Amazon Athena とは
Amazon S3 とは
DataFrame(データフレーム)
AWS CLIでクレデンシャルファイルパスを環境変数から設定できるようになりました
Windows環境変数編集画面へのショートカットアクセス方法
(pandas user guide) Integer dtypes and missing data
(AWS SDK for pandas(awswrangler)) 4 - Parquet Datasets
(AWS SDK for pandas(awswrangler) Github issue) parquet dataset file name
*1:「モバイル空間統計」は株式会社NTTドコモの登録商標です
*2:Amazon Web Service:世界最大規模のクラウドプラットフォーム
*3:AWS Athena:アドホックな分析に適したデータベース
*4:pandas.DataFrame:Pythonでのデータ分析や機械学習でよく使われるデータ形式
*5:AWS SDK for pandas (awswrangler):pandasからAWSを便利に操作できるPythonのライブラリ。参考リンク先ではAWS Data Wranglerと呼ばれているが、これは古い名称。最近正式名称が変わった模様
*6:AWS CLI:コマンドライン上から様々なAWSのサービスを操作することができるツール。ここではPythonからAWSに対して各種操作をするために使用
*7:名前付きプロファイル:AWS CLIの認証情報とコンフィグのペアに名前を付けたもの。ユーザ側で名前を指定すれば所望の設定を呼び出せる
*8:カラム:列のこと
*9:S3:AWSのストレージサービス。ストレージは「バケット」という単位で作成/管理する
*10:AthenaはS3に対してクエリをかけるサービスなので、データの実体はS3バケットに配置される