
1.概要
NTTドコモ データプラットフォーム部(以下DP部)の外山です。
NTTドコモではプロダクトの改善及びシームレスなマーケティング施策を実施するために、全社でデータ活用を進めていますが、その実現において利用しやすいデータがあることは欠かせません。
それに関し、前回のブログでは、まずは、「イシューから始めよ」に則り、初期段階では解決の質にはこだわらず、分析者が利用しやすいデータを高速に整備するための方法について紹介させていただきました。
その結果、月1万回のアクセスを超えるデータ活用に欠かせないデータマートを提供できるようになった反面、直近にかけてデータパイプラインを管理する私たちに負荷がかかる状況が続いていました。具体的には大きく以下3点が課題として発生していました。
- 直列走行を前提とした、処理タスク間でモジュール性の低いデータパイプラインとなっている
- 事後アウトプット検証のみとなり、最低限のデータ品質の担保しかできていない
- AWS Sagemakerノートブック上でのオンメモリ処理とDWH製品(Snowflake)処理が煩雑に行われており、非効率処理となっている
そこで、次のステップとして解決の質の向上を狙い、モダンデータスタックのうち、データエンジニア界隈で、ELTのTransformに関するデファクトスタンダードとなりつつあるdbt(dbt Core)を導入しました。
公式ドキュメントから読み解けるdbtの特徴は、大きく以下3点となります。
- データパイプラインの高いモジュール性の実現と柔軟なデータパイプライン設計が可能
- データパイプライン組み込み前提のdbt testによるデータ品質の向上が可能
- dbt自体はコンパイル機能を前提とし、DWH製品との親和性向上により処理効率が向上
つまり、技術的負債になりつつある既存データパイプラインをdbtへの刷新を行い、最強のデータパイプラインの構築に挑戦しました。が、いくつもの失敗を経て現在に至るため、 このブログを通して、私の失敗をみなさんに知っていただき、同じような失敗をする人が一人でも減ることを祈って、最強に至る歩みを紹介させていただきます。
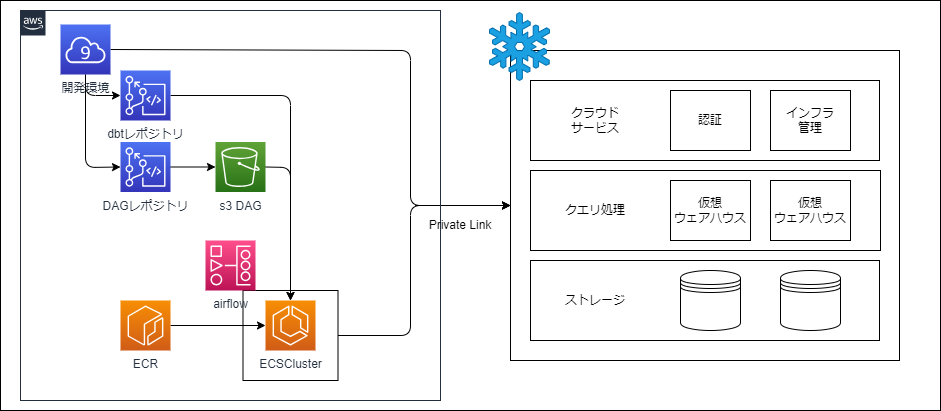
2.構築したdbt実行環境
弊社基盤チームに協力してもらいながら、dbt実行環境をAWS上のサービスを組み合わせ構築しました。 開発と商用で実行環境を分離しており、開発時はCloud9ベースでの実行、商用時はMWAAを利用できる形式にしています。
3.最恐に至る道
公式ドキュメントおよび、各社のブログ記事を参考に、dbt実装を実施しましたが、商用開始直後にインシデントを起こしてしまいました。大きくは以下の3つの要因により、約75万のSnowflake費用を溶かし、待機クエリにより他商用運用がストップ、発覚は数日後と惨憺たる状況でした。
- Snowflakeへの実行制御が不十分で、結合爆発したクエリでの長時間走行が発生
- 並列処理を理解しきれないまま実行し、Snowflake仮想Warehouse内で別商用クエリの待機が発生
- クエリタグ設定漏れによる、1の発見遅れが発生、影響調査にも時間を要す
4.最強に至る道
雑に分かった気にならず、課題一つ一つを読み解いていき、対応することで、現在では商用パイプラインを安定運用しています。以下、実装例を交えながら、どう最強に至ったかをご紹介します。
※Snowflakeの設定などで必要可否が変わる部分もあると思いますが、ご了承ください
4-1.Snowflakeへの実行制御
長時間走行を防ぐために、ECSでのセッション断は行っていたものの、実際にはSnowflake上のクエリがキャンセルされておらず、意図せず長時間走行をしてしまっていました。そこで、dbt実行時に、クエリのタイムアウト設定と、デタッチ設定を実行できるようにしました。
実装イメージとしては、dbt_project.ymlのmodels配下に+pre-hookを追加し、モデル実行時にタイムアウト及びデタッチ設定を実行するようにしました。また、'ifステートメント'を利用し、開発時と商用時で走行時間を変えるといった工夫も行っています。
models:
pj_dbt:
# 実行制御:SESSION単位
+pre-hook:
# 開発時は15分のタイムアウトとする
- "{{'ALTER SESSION SET STATEMENT_TIMEOUT_IN_SECONDS = 900' if target.name =='dev'}}"
- "{{'ALTER SESSION SET ABORT_DETACHED_QUERY = true' if target.name =='dev'}}"
# 商用時は60分のタイムアウトとする
- "{{'ALTER SESSION SET STATEMENT_TIMEOUT_IN_SECONDS = 3600' if target.name =='prod'}}"
- "{{'ALTER SESSION SET ABORT_DETACHED_QUERY = true' if target.name =='prod'}}"
その他、on-run-startでの実装も試みましたが、モデル実行時に発行されるセッションIDがon-run-start時とモデル実行時で異なり、セッション単位に実行制御を加えることが難しかったため、今回は利用していません。
参考
- snowflake
- dbt
4-2.並列処理の理解
待機クエリを発生させてしまった背景として、並列化することでトータルの実行時間は減らせるものの、Snowflakeの仮想ウェアハウスのリソース負荷を見逃していたことがあります。 dbtの並列処理数(threads>1)に加え、特に、盲点だったことはJob実行をAirflowで行っていたため、実行DAG数・DAG内でのタスクの並列処理数、dbtでの並列処理も合わさると、想定より仮想ウェアハウスへの負荷が増えてしまう場合があります。
そのため、他と処理が別にできるよう、現在はSnowflakeの仮想ウェアハウスを追加することや、dbtのthreads数をあえて低めにする運用を行っています。一方、dbtの並列数を減らすとトータルの実行時間は増えてしまい、Snowflakeの仮想ウェアハウスに対し、一定程度の負荷が継続するため、スモールに並列を試しつつ、最大並列処理数を検討することがおすすめです。
参考
4-3.クエリタグの設定
今回のインシデント発見の遅れの一因として、Snowflakeのクエリタグの設定漏れがあります。dbtでは、大きく3通りの設定方法があります。
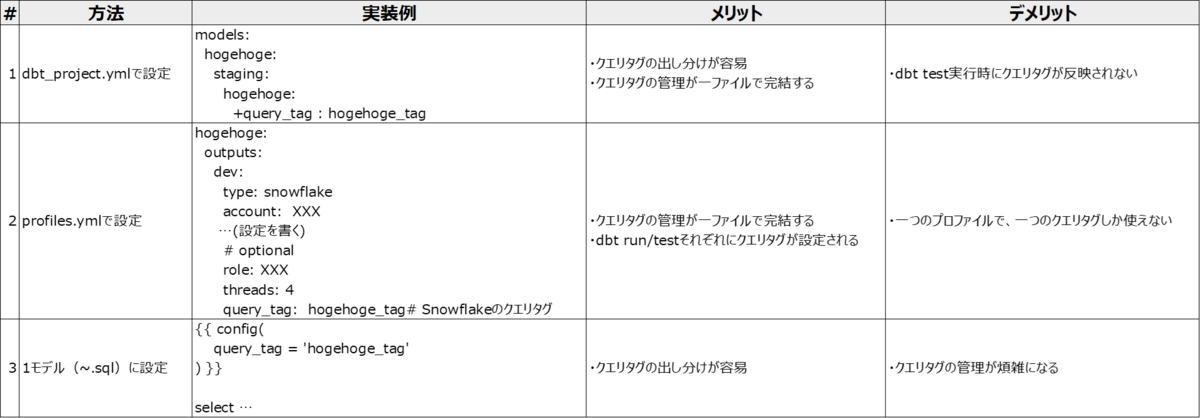
クエリタグを実行パイプラインで出し分けたいため、当初は#1のmodelsに記載する方法で進めていましたが、運用中の発見として、パイプラインを実行するdbt runではこちらで問題ないものの、dbt testに関してはクエリタグが設定されないことが判明し、現在は#2のprofiles.ymlに設定しつつ、#1のmodelsにも記載する形をとり、クエリタグの漏れをなくし、可観測性を高める運用を行っています。
参考
4-4.その他
インシデントからの対応事項に加え、その他の改善としては、ブランチ戦略をとっておらず、開発中のモデルが含まれることにより、コンパイルエラーを引き起こしていた部分をgit-flow形式に変更したことや、ユーザー体験として日本語カラム名の方が望ましいため、dbt実装上もstagingから日本語名にしていましたが、dbt testなどがやりにくくなってしまったため、原則英名、最終アウトプットのみ和名とする運用に切り替えたことなど細かな改善も行っています。
5.まとめ
75万円を溶かす「最恐」なところから、上記を一つずつ解消し、既存パイプラインのマイグレーション・リファクタリングをすることで、対象のモデルによって90%のコスト・実行時間改善ができるまで整備することができました。また、SQLのみでまるでソフトウェア開発の如く、高品質のデータパイプラインを構築できることは、必ずしもスキルフルではない人材でも、SQLさえかければ複数回のハンズオンで開発を始めることができ、昨今のデータエンジニア不足の中のおいて、dbtはデータ整備をスケールする「最強」のモダンデータスタックの一つに今は感じています。
一方で、今回一度最恐に落ちてしまったのは、製品特性としてSnowflakeのようなDWH製品の機能に精通しておく必要があったにも関わらず、よく確認もせず単に技術に飛びついてしまったところが原因です。認知負荷がますます高まるところは悩ましいものの、より「最強」を目指して今後もチャレンジを継続できればと思います。