
1.はじめに
NTTドコモ データプラットフォーム部(以下DP部)外山です。
NTTドコモでは、携帯回線事業の他、dポイント・dカード・d払いを中心にお客様の新たなライフスタイルを創出する各種d系サービスを提供し、提供後のプロダクト改善やマーケティング施策の実施にデータを活用しています。
本記事では、データ活用の基礎となるデータマートの作成のいろはを紹介します。ユーザーの業務フローを実際に早く変えたい、でも何からはじめればいいかわからないユーザーサイドのデータ整備を担う方におすすめです。
このブログから得られること
- データ活用を進める中で、より活用を進めるためのデータマートを整備するときの初期段階での考え方
- 基盤・スキルセットに依存しすぎず、誰でも運用可能なデータパイプライン構築の考え方
このブログでは得られないこと
- 最新技術を用いたエレガントなデータパイプラインの実装
Keyword
2.データ活用の民主化に向けた現状と課題
ドコモグループの中期経営目標において、「データ活用人材を2025年度5,000⼈規模まで拡⼤し、デジタルマーケティングの高度化・データドリブン経営を加速」と掲げている通り、NTTドコモでは社内のデータ活用人材の育成に力を注いでいます。
NTTドコモは携帯回線事業に加え、dポイント・dカード・d払いを始め様々なサービスを提供しており、それらから得たOneIDで管理された膨大なデータを保有しています。プロダクト改善、シームレスなマーケティング施策を実施するための多様なデータが揃っているため、データ分析を実業務へ組み込める環境となっており、育ったデータ活用人材が活躍する機会も豊富です。
このような時流の中で、DP部は他部署とも協力しつつ、人材育成・データ・ツールからなる「データプラットフォーム」を提供し、NTTドコモでのデータ活用を支えています。
この流れをさらに高速化・高度化する必要がありますが、その前提として、分析ユーザーが利用しやすいデータがなければなりません。 “Garbage In, Garbage Out”という言葉がある通り、NTTドコモの強みであるOneIDで管理されたデータが利用価値の高いデータでない限り、手段の行動化・高速化ができても、間違ったデータドリブン経営に繋がってしまいます。
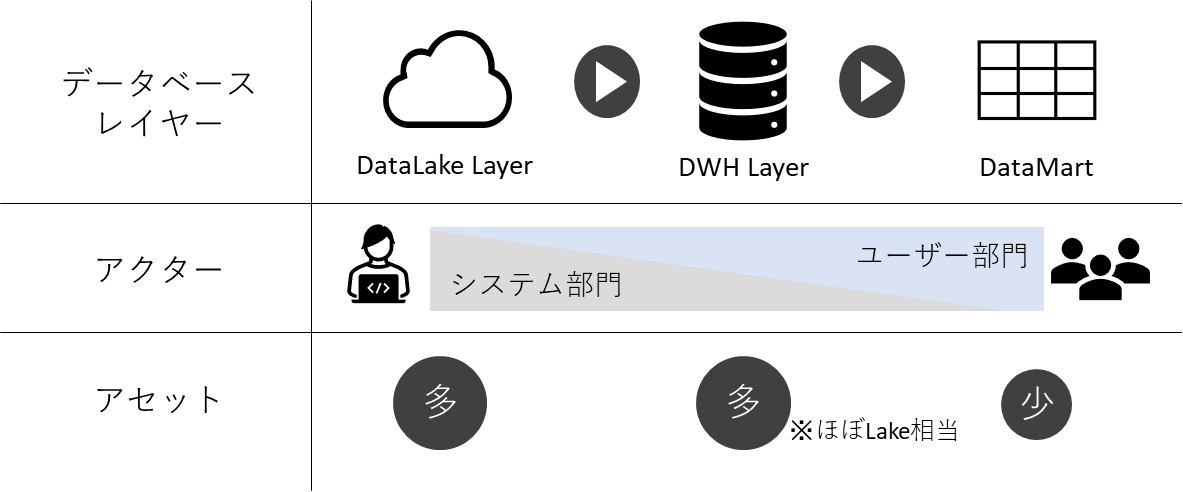
これらの背景の中で、次々と新サービスがリリースされる中で、分析をクイックに行うためのデータマート整備が手薄になってしまっていることや、Snowflakeを利用しスケーラブルな運用が可能な反面、コスト最適化観点では改善が必要な状況、データマートの整備が手薄なことに起因し、ユーザー側でのデータマート整備が独立して行われた結果、目線合わせに利用する根拠にバラつきが生まれてしまい改善が必要なことなど、複数の課題と改善ポイントが見つかっている状況でした。
これらデータ活用の民主化の障害となってしまう状態を解決するために、実際に利用するユーザーサイドからの改善ができないか?と考え、これさえ使えば、解決!となるデータマートの作成を実施することとしました。
3.データアーキテクチャーデザイン
データマート作成においては、これさえ使えば、解決!=分析ユーザーが利用しやすいデータとし、データアーキテクチャーの検討から開始しました。データマート設計の指針となる分析ユーザーが利用しやすいデータの要素を5点定めるところから始めましたが、リソース都合もあり初めから現状→理想にジャンプすることは難しい状態でした。そこで、問題解決のプロセスとして、「イシューから始める」こととし、問題解決の質を一旦棚上げすることで、イシュー:分析ユーザーが利用しやすいデータが作成されていないことに、より向き合える現実的な方法を模索することにしました。こちらのパートでは、それらについて解説します。
3-1.避けては通れぬ茨の道
分析ユーザーが利用しやすいデータに関して、はじめに以下5点の要素を定めました。これらは、これまでのデータ分析支援でのユーザーからの指摘事項や、今後利用するユーザーを想像して必要そうなこと、特徴量ストアの事例などを参考にして定義しています。
- 解釈性:利用するカラムがビジネス的な解釈が可能か
- ~の合計という集計定義ではなく、利用頻度を示すという意味解釈ができるか
- 精度:機械学習に利用する場合、精度向上に寄与するか
- 予測アルゴリズムではカバーできない特徴量が生成できると望ましい
- 安定性:機械学習に利用する場合、安定的に利用できるか
- 開発・運用でのデータドリフトが頻繁に発生しにくい特徴量に限定できることが望ましい
- 汎用性:特定事業・サービスに偏って特徴量が存在していないか
- どの事業においても、ベンチマークとして活用できる状態が望ましい
- 容易性:簡単にアクセスできる状況にあるか
- 特定基盤に依存せず、全社基盤で扱えるようになっていることが望ましい
これにより利用しやすいデータの状態は定まったものの、開発をすすめるには以下3つの壁を乗り越えながら、実際に利用されるデータを作成しなければなりません。
第一の壁:なんでもござれなハイスキル人材は引っ張りだこ
NTTドコモでは、データエンジニアとデータサイエンティストが部門間に跨って存在しており、DP部にも、データサイエンティストが多数在籍しています。その中でもなんでもござれなハイスキルな人材は別案件対応等引っ張りだこ状態のため、スキルセットを問わず対応できる内容でメンバーを集める必要がありました。
第二の壁:汎用性⇔開発工数とのトレードオフ
NTTドコモでは、多数のサービスを扱い、データが膨大にある反面、それら全てを網羅的に整備するには、時間がかかってしまいます。整備する意図は、ユーザーに一日でも早く価値を届けるためであり、そのため、アジリティが担保できる範囲の主要事業に限定し、対応する必要がありました。
第三の壁:役割間(部門間)のコミュニケーションコストが大きい
第一の壁に関連して、素早いアウトプットの作成において、役割間(部門間)とコミュニケーションコストを考える必要がありました。我々が今利用できるX基盤では○○できないが、YさんTmのZ基盤だったら○○できるといった場合に、Z基盤を利用できるように担当者間調整をすることもありますが、具体化されていない状況においては、調整コストがかなり高くつくことがあります。そのため、アジリティ高く対応するには、実装方法も限定する可能性がありました。
3-2.イシューから始める
これら3つの壁を踏まえつつ、理想に向かっていく開発をどうすればいいか。そこでカギとなるのが「イシューから始める」です。開発者の性として、「モダン」な技術・基盤を用いたくなるところですが、果たしてそれが本当に適切なのか考える必要があります。


今回のイシューは分析ユーザーが利用しやすいデータが作成されていないこととした場合に、問題解決の順序はどうとるべきなのかを考えてみます。セオリーに従えば、右回りの宝の山から目当てのものを探す必要があり、今回の場合をあてはめて見ると、解決の質:Modern Data Stackのような手法にこだわるよりも、できる手段をとり、泥臭いが筋がいい状態へと向かっていけるような開発スタンスをとるとよさそうでした。
そのため、第一の壁だったメンバーのスキル面は意識することなく、まずは利用されるデータを設計できることを重視しながら、できるパイプラインを構築することを目指すことにしました。第二の壁の汎用性⇔開発工数のトレードオフは、まずは必要性が明らかなデータから作成することで目指す状態を早く実現し、あるべき姿に早く向かうことを目指すことにしました。第三の壁へは解決の質ではなくイシューを優先することから、コミュニケーションが最小で済む基盤を選択することにしました。
3-3.採用したデータパイプライン
次に、前述の方針に照らし合わせながら、メンバーとどういった実装パターンがありうるか?を検討しました。 整理した結果、4つの実装方式が実現できそうでしたが、メンバーが実現できる内容で、開発のしやすさ、運用のしやすさなどからバランスよいものを選択する必要がありました。開発目線では、SQLでは計算しにくいものでPythonだと計算しやすいものが存在、運用目線では、実行クエリが多岐にわたるため、実行コード管理や運用時の手間をできるだけ最小化できるバッチ運用のような形を目指す等の議論がありました。これらの要件を満たす実装方法として、最終的にNo1の方式を採用することとしました。
実装方式
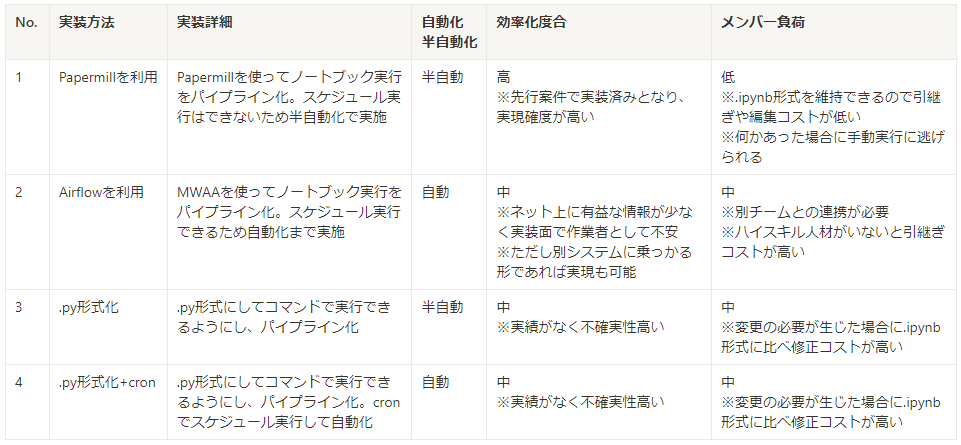 ※Papermill:Jupyter notebookにパラメータを引き渡し、バッチ実行を可能とするツール
※Papermill:Jupyter notebookにパラメータを引き渡し、バッチ実行を可能とするツール
※MWAA:ワークフロー管理(オーケストレーション)ツールであるAirflowのマネージドサービス
実行フロー
上記、実装方式を選んだ場合の実行フローのイメージは以下となります。
任意の運用者で実行できるように工夫しており、作成済みコードをCodeRepositoryにPushしておき、運用者は実行前にPullするだけで、必要なコードを揃う状態にしています。その際に、「PGM(A)の前に実はPGM(A’)が必要」といった実行順が暗黙知化しているケース、「PGMが数十にもなる場合において、順に実行するだけであっても、実行を忘れる」といったオペレーションミスを防ぐ必要があります。そのため、PGM全体を1つだけで動かせるように、Papermillを活用しています。ここでは、実行を管理するPGMを「親PGM」、実処理を行うPGMを「子PGM」と呼んでいます。
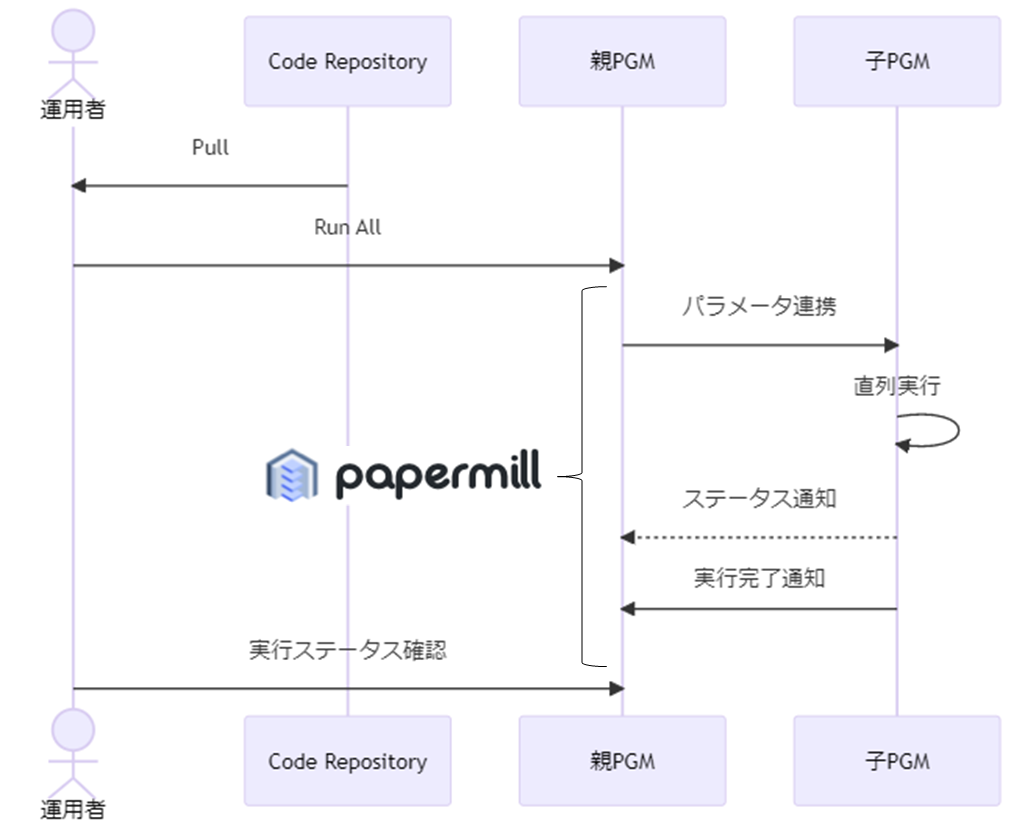
こちらを実現する上で、子PGMを効率的に親PGMから呼び出せるように、関数を作成しました。単純に子PGMを実行するだけではなく、子PGMが正常に動作したことをクイックに確認できるように、result = use_logs['cells'][-1]['outputs'][0]['text']を実装し、子PGMの最終セル結果を取得、親PGM側で表示できるようにしました。
その関数イメージは以下となります。
def execute_nb(nb_path , nb_name , param_main , data_warehouse): """ 子PGMを実行する関数 Parameters ---------- nb_path : str 実行する子プログラムの格納先。 nb_name : str 実行する子プログラム名。 param_main : str 子プログラムに渡すパラメーター(JSON)。 user_id :認証で使用 p :認証で使用 riyou_ym:作成断面を定義 data_warehouse : str 子プログラムに渡すパラメーター snowflakeのウェアハウスを定義 """ #初期化・開始時間取得 exec_pgm_path = 'XXX'#notebook格納先パス use_logs = {} d_today = datetime.date.today() start = time.time() #子PGM実行 use_logs = pm.execute_notebook( exec_pgm_path + '/{nb_path}/{nb_name}.ipynb'.format( nb_path = nb_path , nb_name = nb_name ) ,exec_pgm_path + '/{nb_path}/output/{nb_name}_{riyou_ym}.ipynb'.format(nb_path = nb_path ,nb_name = nb_name , riyou_ym = riyou_ym) ,parameters = dict(param_main = param_main ,param_data_warehouse = data_warehouse ) ,kernel_name = "python3" ) #処理結果取得 result = use_logs['cells'][-1]['outputs'][0]['text'] #処理時間計算 m , s = divmod(round(time.time() - start,2),60) execute_time = str(int(m)) + '分' + str(int(s)) + '秒' #処理結果表示 print( d_today , nb_name, result.replace( '\n' , '' ) , execute_time , sep = "/" ,end = '')
4.開発デザイン
イシューから始めるための実装方針が定まり、実装を進めていきたくなりますが、まだ事前検討すべき内容が残っています。 実際に作るモノを具体的にどう定めるか(データマート設計)、作成プロセスを具体的にどう定めるか(ルールメイキング)が必要です。
4-1.データマート設計
ユーザー視点にたち、データマート設計を行う場合、闇雲に作ってしまうと内容重複や不足が発生します。そのため、データマートのコンセプトを定めた上で、候補変数のブレストを行い、発散気味に内容抽出を行い、優先度・実現度を見定めながらその具体化、最終的にはデータフォーマットを定めるようなプロセスをとりました。以降、ステップ的にポイントをまとめますが、完了してから次ということではなく、期限を設定し、繰り返し前提で作成しました。

候補変数のブレスト
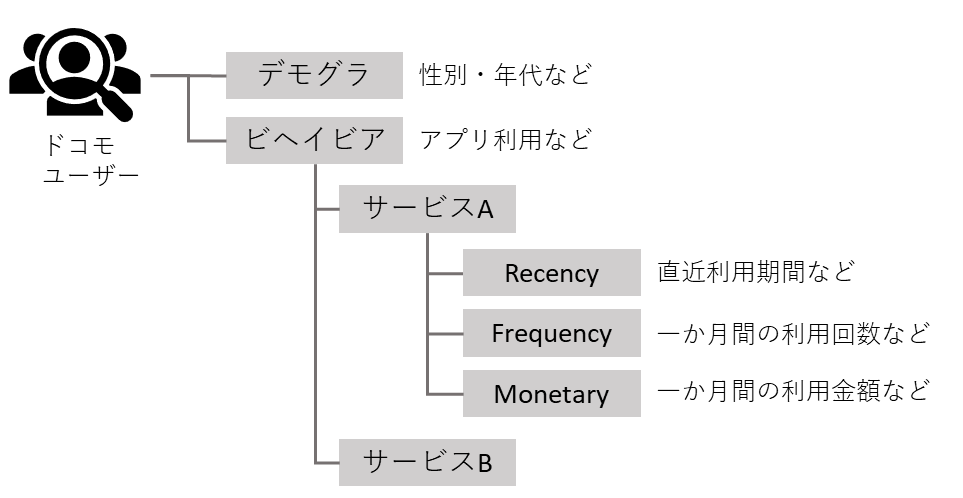
分析に利用しそうだからといって闇雲に作成すると、先述の解釈性・汎用性を疎外してしまう恐れがあります。つまり、データからユーザー像を見透かすことできるようにするためには、深さ・広さ・構造からなる「解像度」を先に考える必要があります。構造化した上で、作成したい候補変数のブレストをメンバーと実施しました。
※参考:馬田隆明 解像度を上げる
- 解像度
- 深さ:汎用性を保つため、あえて、深く作りすぎないようにする(サービス×RFMを基本)
- 広さ:事業領域を網羅する(ドコモサービスを網羅する)
- 構造:デモグラ・ビヘイビアで構造化する
候補変数の具体化
ブレストにて候補とした変数に関して、どういう内容を作成するかの具体化を実施しました。具体化にあたっては、過去の分析で作成した項目を参考にしつつ、何か具体的なターゲットを置き、どういう風に使えるかの仮説を設定し、必要な変数イメージを定めるようにしています。
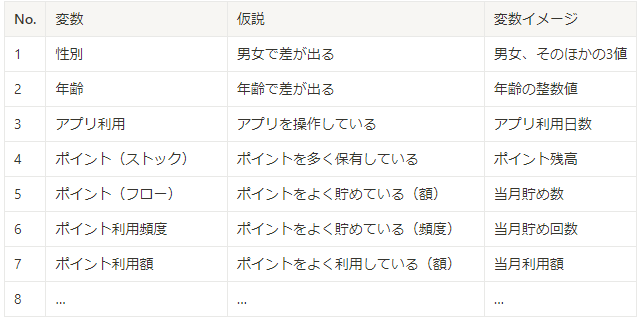
データフォーマットの決定
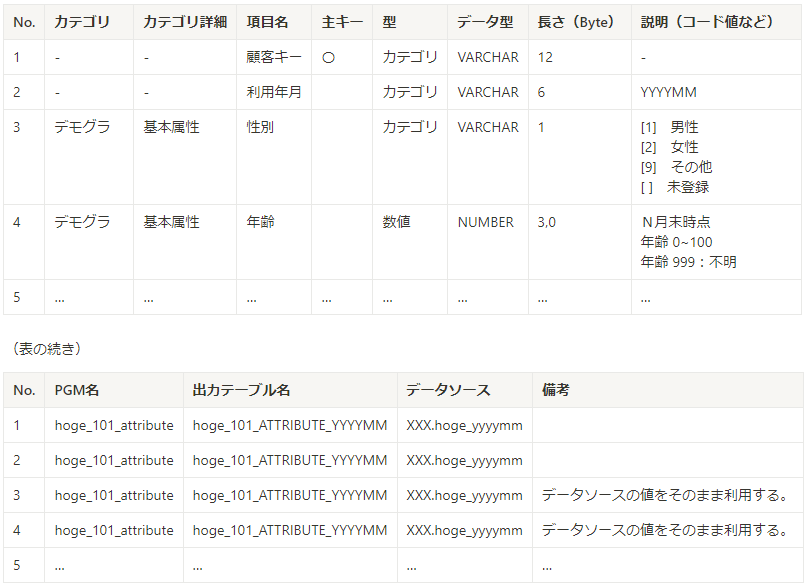
具体化した内容をもとに、実際に作成するデータマートの仕様を決定しました。 その際、項目と対応するPGM・関連データソース等もまとめておき、後で参照しやすくできるように工夫しました。 実際のフォーマットの掲載が難しいため、イメージを以下に記載します。
4-2.ルールメイキング
今回採用したPapermill方式だと、開発者が.ipynb形式で自由に開発・更新できるものの、自由度が高すぎる反面、属人的なコーディングとなり、後々の管理が困難となってしまうため、事前にコーディング規約をチームで設定しました。 また、アジリティ高く開発が進むように開発範囲を狭めたものの、数名での開発とはなるため対応範囲は広いことや、開発者のスキルセットに関しても、熟練者と初級者では異なるため、プログラム品質に差が生まれそうな状況だったため、効率的な開発となるよう、工夫する必要がありました。そこで、事前にプログラムのテスト項目を定め、品質を一定担保しながら、開発者の都度のテスト設計等は避けつつ、開発を効率的に行えるようにしました。
コーディング規約:プログラムフロー規約
実装プログラムフローが属人的になるとコードレビュー時、該当箇所の発見に時間がかかったりと確認コストが増えてしまいます。また、中間テーブルを作成するようにしている都合で、中間テーブルの削除処理の作成を失念し、ストレージコストを圧迫してしまうといったリスクもありました。そのため、以下のようなプログラムフロー規約を作成し、開発をしました。
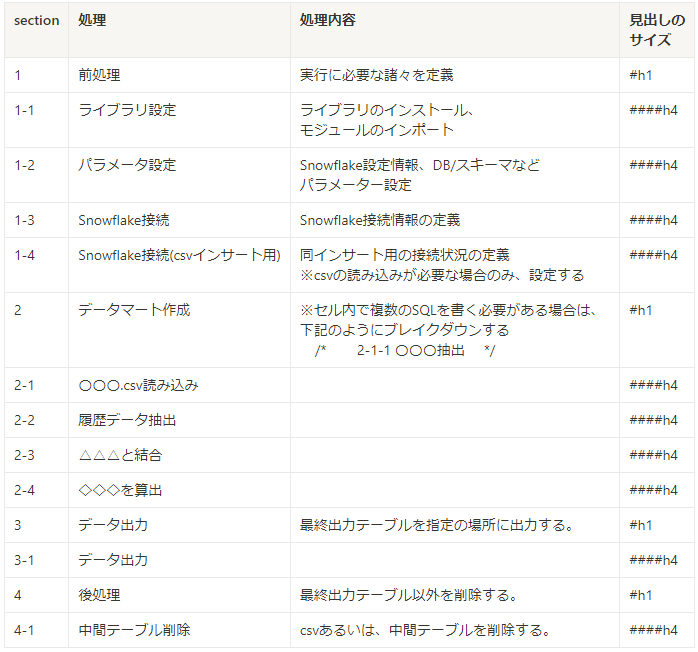
その他、コーディング規約として命名規約・コメント記載規約も作成しました。
上記規約に則って、コード作成が行われているかはコードレビュー時に確認をしています。 レビュー観点を都度検討だと、コード品質がぶれてしまう、また、アジリティが低くなるため、 以下7項目を事前に確認観点として定めて、コードレビューを行いました。
- コーディング規約に沿ってプログラミングされているか
- プログラムフロー規約に沿ってプログラミングされているか
- 命名規約に沿ってプログラミングされているか
- コメント規約に沿ってプログラミングされているか
- テスト用定数からパラメーターへの変更漏れはないか
- サンプリングの条件式をパラメータ化できているか
- 抽出条件に誤りはないか
- 結合キーに誤りはないか
- 時制はあっているか
- case文やif文などの判定式に誤りはないか
テストパターン
作成したPGMに対し、単体・総合テストのようなことを都度検討すると、アジリティ高く開発することが難しいため、最低限の品質担保が可能となるテストパターンを事前に作成し、開発を行いました。イメージとしては、ブラックボックステストのようなテストパターンを8項目設定しました。
- 出力結果は想定通りか
- 〇が△に作成されていること
- 〇のカラム名及び型がテーブル定義と一致すること
- 〇の各カラムのコード値がテーブル定義と一致すること
- 〇のレコード数がinデータのcsvのレコード数と一致すること
- 〇の◇に重複がないこと
- 〇の各カラムと該当のinデータのカラムの分布に差がないこと
- 中間テーブルが削除されている事
5.おわりに
5-1.利用状況
2023年8月末において、9Viewを公開し、最大250人近いユーザーにより、直近6,000回以上利用されるデータマートを提供しています。
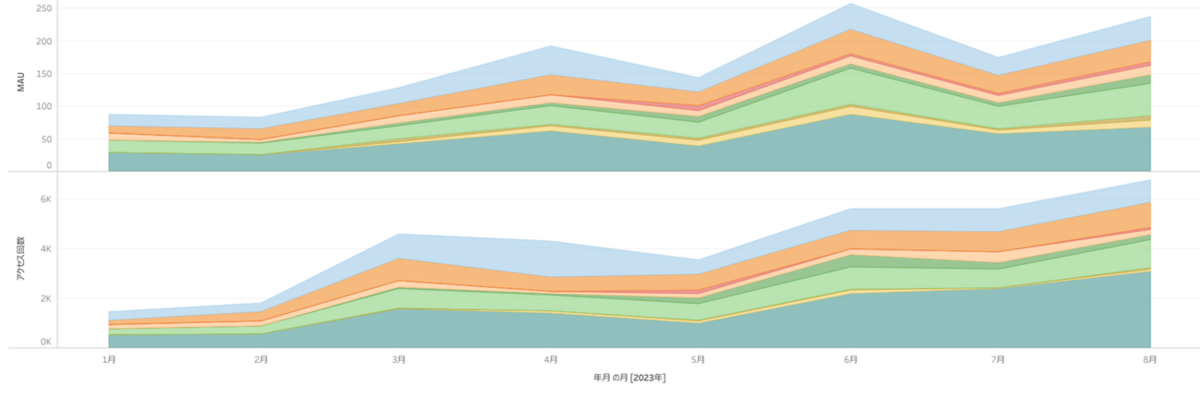
5-2.カイゼン計画
分析ユーザーが利用しやすいデータの作成において、事前にどういうものが必要かをユーザーインタビューで明らかにすることは難しいため、 実は開発者側の思い込みだった可能性が考えられます。また、利用され続けるために、改善要望等を収集する必要があります。 更に、データエンジニアリングはこれまで記載した通り、意義は大きいものの、地味な作業も多く、メンバーのモチベーションが低下しやすいため、モチベーション向上のためにも、ポジティブなコメントを集めてみることも重要です。
今回作成したデータを利用いただいたユーザーからは、ポジティブな意見として、「機械学習の特徴量作成にかかる時間が1/10になった」、「データレイアウトや命名規則に一貫性があり、理解しやすい」等々コメントいただけた反面、 「顧客キー変換が前提になっており、初めからXXキーをいれてほしい」・「情報更新日を今よりも早くしてほしい」といった改善要望も複数上がってきていました。
ユーザー課題を全て解決しよう!と張り切ってしまいそうになりますが、サービス変更等によるデータ改修が事前に決まっており、メンバーを既にアサインしてしまっている等して体制的に対応困難なことがあります。そのため、ここもまたイシューから始める必要があります。
より解くべき課題を特定する優先度基準
ユーザーからのコメント及び、開発者側として解決の質を高める内容を優先度高く評価することにしました。
- 汎用性があり、ユーザー志向(使われるもの)を優先度高く設定したい
- データ品質に関わる作業を優先度高く設定したい
- 運用が簡素化・自動化される作業を優先度高く設定したい
次回開発内容
課題を上記基準を用いて選別し、以下3テーマの開発を行うことを決め、現在対応を続けています。
- カラム方向の対応:顧客キーの追加
- 顧客キー変換処理のような、ユーザーにとっては面倒な部分を改修し、まだ拾えていないユーザーニーズを取り込み、利用データは本データのみで完結する形を目指す
- レコード方向の対応:対象母集団の拡張
- 現在は利用データの制約により、取り込めていないデータがあることが判明。データを差し替えることで、対象母集団拡張を行う
- データ品質
- 上流データの異常・不具合を目検に頼っており、運用負担が高く、ユーザーに向けても自信をもっておすすめできない。自動検知できる仕組みを構築する
最後に、記事を書く機会に恵まれれば、こちらの開発内容に関しても掲載したいと考えています。 続編もご期待いただけますと幸いです。