
目次
使用ソフトウェア一覧
![]()
![]()
![]()
環境
| 言語・フレームワーク | バージョン |
|---|---|
| Python | 3.9.16 |
| dbt | 1.6.1 |
| dbt-snowflake | 1.6.0 |
はじめに
NTTドコモ サービスイノベーション部の秋山です。普段の業務では、お客様の行動データからドコモのサービスを改善するための分析を行っています。また、その分析のために必要なデータ基盤をCX1分析基盤と呼び、CX分析基盤のデータマート運用もしています。
今回はデータマート運用を簡単にすることで有名なdbtをCX分析基盤へ導入してみます。
(トップへ)
1. ドコモにおける顧客分析の難しさとCX分析基盤
まず、私のチームで運用しているCX分析基盤についてご紹介いたします。
ドコモでは多種多様なサービスが存在するため、お客様の問題をとらえるためには一つのサービスに関する行動データでは不十分なことがほとんどです。
例えば、オンラインショップで端末を購入できなかったお客様がいた際に、
オンラインショップでの購入をあきらめた後、ドコモショップでお買い求めになられたのか、コールセンターにお電話したのか、などその後の行動にいろいろな仮説が浮かびますが、
オンラインショップでの行動データのみでこれらの仮説を検証するのは不可能です。
そのため、サービス横断でお客様の行動を分析することで、本当にお客様が困ったポイントを抽出することが重要だと考えています。
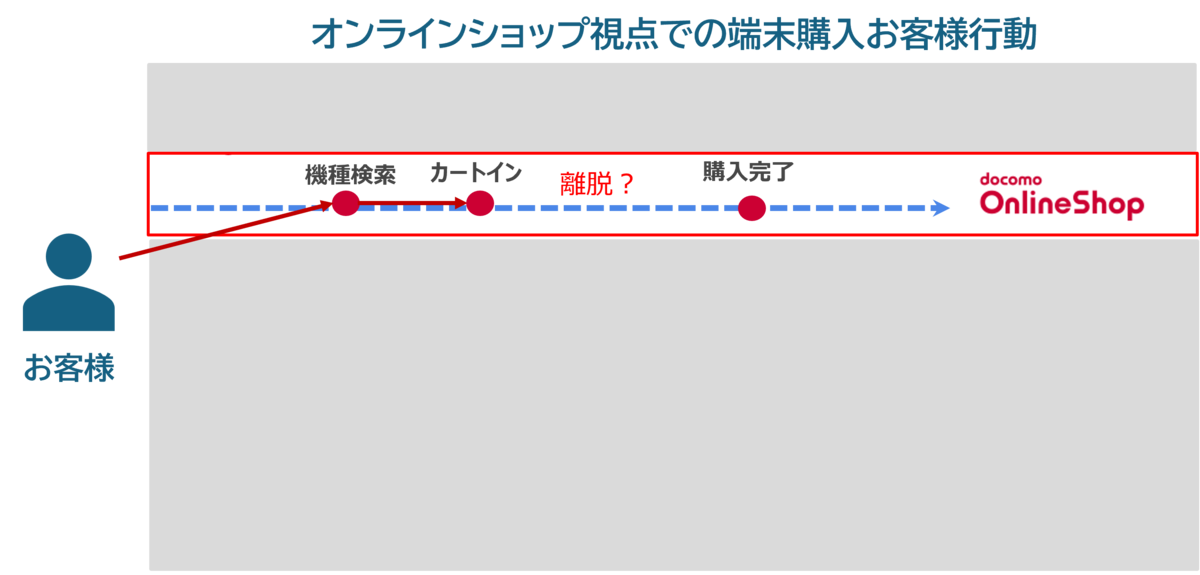
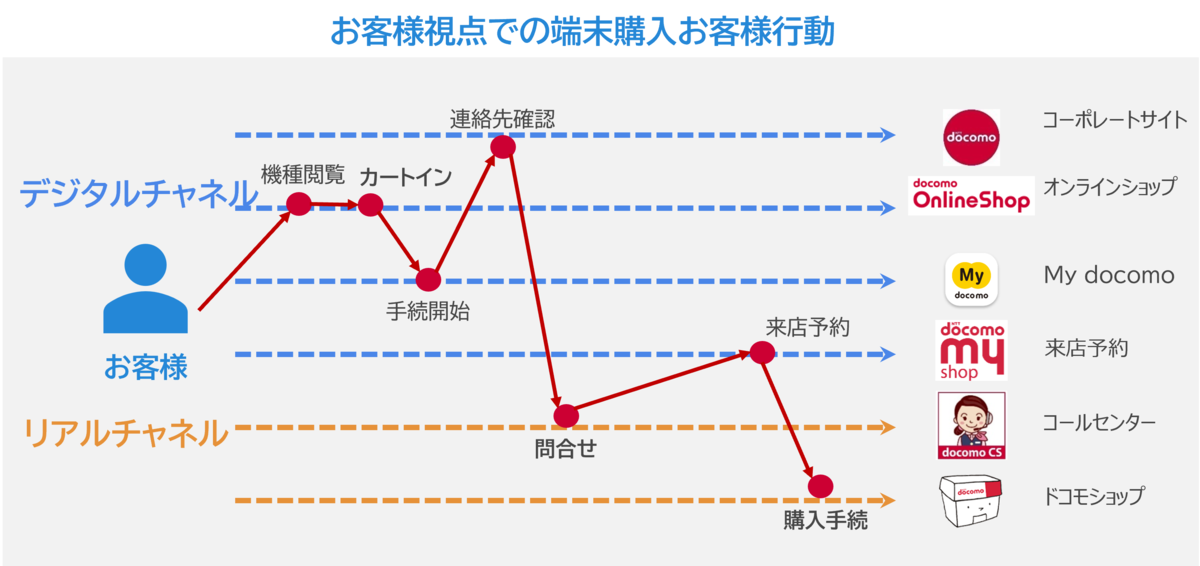
こうしたサービス横断での行動分析を可能にするのがCX分析基盤です。
このようなサービス横断分析を実現するために、私たちのチームではCX分析基盤を開発した上で日々運用しています。
(トップへ)
2. CX分析基盤を運用するときの課題
2.1. 基盤運用で発生する問題について
CX分析基盤では取り扱うサービスが豊富なため、数十の上位システムから発生するデータ(今後は上位システムのデータが格納されているテーブルのことを上流テーブルと呼びます)を取り扱っており、それらを加工することによって各種テーブルを提供しています。
そのため、図のように複雑なデータリネージュになっており、主に2つの問題が発生します。
- 障害発生時のリカバリ作業が困難
- ドキュメント修正が煩雑
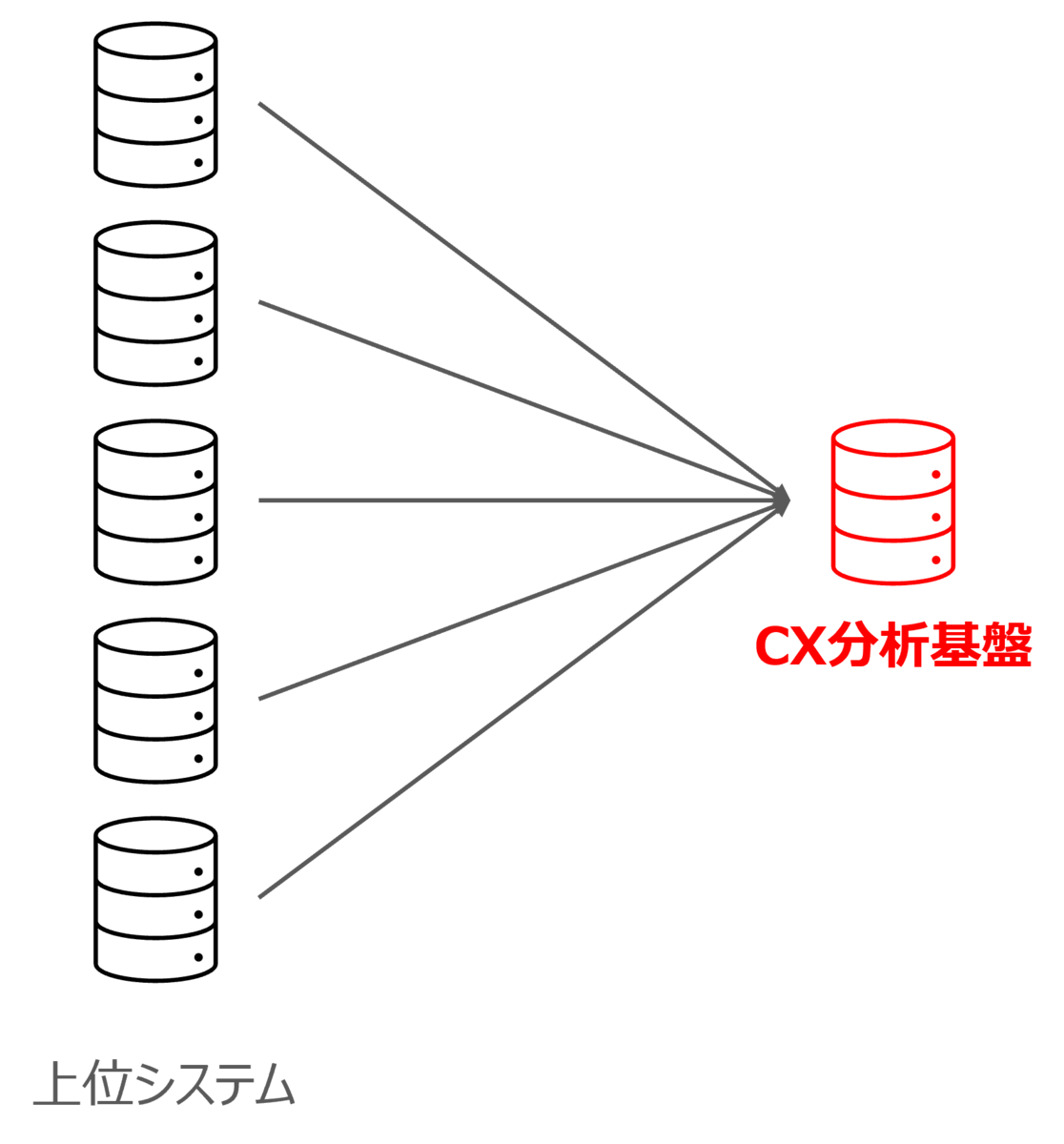

2.2. リカバリ対応が困難な問題
前者のリカバリ対応が困難な問題について、上流テーブルに障害が発生した際に、影響範囲を調べるのが困難な上に、障害影響を受けるテーブルが多いことがほとんどのため、復旧用のSQLを大量に実行する必要があるので、リカバリ作業に膨大な稼働が持っていかれ、リカバリにかかるコンピューティング費用も発生してしまいます。
さらに不運なことに、上流テーブルの障害は頻繁に起きてしまうため、これらのリカバリ作業をほとんど毎日行う必要があります。
2.3. ドキュメント修正が煩雑な問題
後者のドキュメント修正が煩雑な問題について、CX分析基盤では利用者向けにデータフロー図や項目定義書を提供しているので、テーブルに変更を加えた際に、そのテーブルに関するドキュメントについても修正する必要があります。
このドキュメント修正は、変更のあったテーブルのSQLと連動させながら変更する必要があるのですが、変更テーブルそのものだけでなく、その変更影響を受けるその他のテーブルに関するドキュメントについても修正する必要があります。
CX分析基盤では各テーブルが複雑に関係しているので、一つのテーブルを変更すると、その他のたくさんのテーブルが変更影響を受けることが多いため、修正項目の抜け漏れが発生していました。
また、項目定義書をExcelで管理していたため、Gitなどで変更差分を確認できないという問題も抱えていました。
2.4. 取り組むべき2つの課題
したがって、
- 運用におけるリカバリに係る稼働とコンピューティング費用を削減する
- テーブル変更時に発生するドキュメント修正を抜け漏れなく対応できるような開発環境を構築する
という課題に取り組む必要がありました。

また、CX分析基盤において、メインの運用人材、メインの開発人材それぞれは1名ずつのため、これらの課題を解消することの優先度は高いです。
(トップへ)
3. 課題に対するソリューション(= dbt導入)
3.1. dbtとは?
そこで、これらの課題を解消するためにdbtを導入してみたいと思います。
dbtとは、データ変換のためのデファクトスタンダードツールで、標準SQLでは表現できない描き方(Jinja)を可能にしたり、データ変換SQLからデータリネージュを自動で生成したり、タグ付けしたテーブル変換処理の一括実行など、データマート運用を簡単にするためのツールが多数取り揃えられています。

CX分析基盤の抱えるそれぞれの課題に関して、dbtの次の機能を使って解決を目指します。
- 運用におけるリカバリ稼働と費用を削減する → タグ付けによる変換処理の一括実行
- テーブル変更時に発生するドキュメント修正を抜け漏れなく対応できるような開発環境を構築する → データリネージュ自動生成
dbtのタグ機能は、データ変換処理の前後関係を把握した上で、タグをつけられたモデルについて、クエリを実行してくれます。
これにより従来のように前後関係を把握しながら逐一クエリを実行する必要がなく、手戻り作業も発生しづらいため、稼働とコンピューティング費用の削減が見込まれます。
また、データリネージュ自動生成機能では、モデルを記述するSQLと連動して自動で関連ドキュメントへアップデートが加わり、さらにGitで変更履歴を追跡できるようになるため、抜けもれなく更新できるような環境構築が期待できます。
ここでの記述例は読者の皆さんが、ご自身のケースでも実行できるようにhogeやfugaを使っていますので、用途に応じて書き換えるようにしてください。
3.2. 課題に対する考え方・実装方針
dbtの機能を活用するにあたって、まずは標準SQLで記述したデータ変換SQLをdbtの形式に書き換える必要があります。
ここで、dbtではmodelと呼ばれる粒度でデータ変換を管理します。通常の標準SQLではDDLなどでテーブル作成の宣言をしたうえでテーブル作成等を行いますが、dbtでは(基本的には2)DML(SELECT文)のみでモデルを作成することが可能です。
また、modelのDMLで出力される結果をTABLEやVIEWとして自身の環境に作成することができます。
出力結果の種別はmaterializedというパラメータにて、TABLE, VIEWなどを指定できます。
例えば、次のような標準SQL→modelのような書き換えが可能となります。
## 標準SQLでのテーブル作成例 CREATE TABLE <table名> AS SELECT hoge FROM TABLE ;
## dbtでのテーブル作成例 select hoge from table ;
障害対応の費用削減に向けて、最低限のSQL実行でリカバリが完了するようようにしたいので、モデル作成の粒度を各データ変換の粒度に合わせるようにします。
例えば、あるテーブル作成SQLにA→B→Cという変換が含まれている場合は、modelA、modelB、modelCという3つのモデルを作成します。
上記のような例では、次のような標準SQL→modelのような書き換えを行います。
## 標準SQLでのデータ変換処理 -- 変換A CREATE TABLE intermediate_A AS SELECT hoge, fuga FROM source_table ; -- 変換B CREATE TABLE intermediate_B AS SELECT function_1(huga, fuga) AS hoge FROM intermediate_A ; -- 変換C CREATE TABLE TARGET_TABLE AS SELECT function_2(hoge) FROM intermediate_B ;
## dbtによるデータ変換処理modelA(modelA.sql) -- 変換A {{ config( materialized='table', ) }} SELECT hoge, fuga FROM {{ source('SCHEMA名', 'source_table') }} ;
,
## dbtによるデータ変換処理modelB(modelB.sql) -- 変換B {{ config( materialized='table', ) }} SELECT function_1(huga, fuga) AS hoge FROM {{ ref('intermediate_A') }} ;
,
## dbtによるデータ変換処理modelC(modelC.sql) -- 変換C {{ config( materialized='table', ) }} SELECT function_2(hoge) FROM {{ ref('intermediate_B') }} ;
ここで、dbtで作成する場合はmodelCで作成されるテーブルが作りたかったテーブルです。
こうすることによって、modelBに関連する上流テーブルに障害が発生した際に、modelB以降のSQLのみ実行できるので、modelAに相当する不要な加工処理を省略できるようになります。
また、データ変換粒度でモデルが構成されているので、障害が発生した際に障害影響のあるモデルとそのつながりをデータリネージュから確認できるため、一目でデータ変換過程のどこに影響があるのかが分かるようになります。
モデルを作成するときは、テーブル粒度でデータ変換SQLを実行できるようにするために、各モデルに関連するテーブルに相当するタグをつけるようにします。
例えば、下記のようにテーブルAに関連するモデルにはTABLE_Aというタグを付けます。
## タグ付の例
{{ config(
materialized='table',
tags=["TABLE_A"]
) }}
SELECT
hoge
FROM
fuga
;
ところで、上の例からも分かるようにまた、dbt流の描き方ではFROM句に特徴があります。
他のモデルを参照する場合はfrom {{ ref('モデル名') }}のように描くことで、モデル名.sqlの実行結果を参照することができます。
また、各モデルのソーステーブルのsource_tableについては、sources.yamlというファイルを下記のように描いておくことで、呼び出すことができます。
## sources.yamlの記入例 version: 2 sources: - name: <ソース名> database: <データベース名> schema: <スキーマ名> tables: - name: <テーブル名> description: '<テーブルの説明>' columns: - name: '<カラム名>' description: "<カラムの説明>" ... ;
最後にドキュメントの作業漏れを防ぐために、dbtのプロジェクト内におけるmodelsディレクトリの構成を次のようにしておきます3。
dbtではプロジェクトという呼ばれる単位で管理します。
このプロジェクトディレクトリの中にデータマート生成に必要なモデルやドキュメント資材を格納していきます。
├── dbt_project │ ├── models │ │ ├── hoge_table │ │ │ ├── pipeline │ │ │ | ├── modelA.sql │ │ │ | ├── modelB.sql │ │ │ | ├── ... ... │ │ │ ├── doc_hoge_table.md │ │ │ └── schema_hoge_table.yaml │ │ ├── fuga_table │ │ │ ├── pipeline │ │ │ | ├── ... │ │ ├── sources │ │ │ ├──sources.yaml ...
こうすることで、モデル変更が発生した際に、そのモデルに関連するテーブルのその他のすべてのモデルを網羅的に編集することが可能となります。
また、mdやyaml形式で記述するためGitで差分確認ができるので、レビューの際に更新漏れが発見しやすくなります。
3.3. 実装
CX分析基盤ではSnowFlake上にデータマートを作成しているので、SnowFlakeを使用する前提で実装を進めます。
まずは、仮想環境でdbt実行環境を構築していきます。
次のコマンドを実行しつつ、インストラクションに従ってインストールを進めます。
create the environment
python3 -m venv dbt-env
activate the environment
source dbt-env/bin/activate
Install latest version
pip install --upgrade pip wheel setuptools
Install dbt-core and dbt-postgresql plugin
pip install dbt-snowflake
最新のバージョンがインストールされているかを確認します。
dbt --version
これでdbtを動かす環境が作成できました。
実際にSnowFlakeへアクセスできるか確認します。
dbt_debug
を実行し、
All checks passed! と表示されるか確認
表示されたら成功です。
続いて、先ほどの実装方針に基づいて、既存の標準SQLをdbt形式に書き換えていきます(ちなみにですが、この書き換えが一番稼働がかかって大変でした)。
また、ドキュメントの資材も作成していきます。
基本は、mdとyamlの二つを使ってドキュメントを作成します。
各ファイルの役割としては次のようなイメージです。
- md:テーブル全体の説明
- yaml:テーブルの各カラムに関する説明
mdファイルはテーブルごとに次のように記述します。 このフォーマットはCX分析基盤の定義書の形式に合わせているのでお好みで変更してください。
## ドキュメントファイルの例
{% docs doc__TABLE_A %}
| データベース名 | スキーマ名 | テーブル名 | テーブル名(英名) |
| -------------- | ---------- | ---------- | ------------------ |
| DB | SCHEMA | TABLE | TABLE_ENG |
| 更新周期 | 更新日時(開始時刻) | 更新日(更新リミット) | 利用システム | データ鮮度 | 保持形態 | 保持期間 |
| -------- | -------------------- | ---------------------- | ------------ | ---------- | -------- | ----------- |
| 1日 | hh:mm | hh:mm | SFタスク | -n日 | 履歴 | YYYY-mm-dd~ |
# テーブル説明
TABLE_Aの説明
# 利用用途
# 備考
{% enddocs %}
また、yamlファイルは次のように書いていきます。
## yamlファイルの記述方法 version: 2 models: - name: TABLE_A description: '{{ doc("docs doc__TABLE_A") }}' columns: - name: column_A description: 'カラムA' - name: column_B description: 'カラムB' ...
これらのファイルをデータマートで運用する各テーブルについて作成していきます。
(トップへ)
4. 実際の活用
4.1. リカバリに係る稼働とコンピューティング費用削減
障害が起きた際に該当するモデルのみを修復することを想定します。
影響のあったモデルがmodelAの場合は
dbt run --select modelA+
でmodelAから後続のモデルをすべて更新することができます。
また、データマートのアップデートにより、テーブルをアップデートした場合は、タグを用いてdbt run --select tag:(タグ名)でタグ付けされたモデルをすべて実行できます。
従来では障害のあったテーブルの前後関係をすべて把握して、それぞれのSQLを前後関係に沿って実行する必要があったのですが、dbtを利用することで上記のようにコマンド一発でデータ更新を行うことができます。
4.2. ドキュメント開発環境構築
次にドキュメント作成ですが、dbt docs generate とdbt docs serveを実行するだけで、準備したmdやyamlをもとにドキュメントが生成されます。
生成イメージは下記のとおりです(テーブル名などは社外秘なのでぼかしを入れています)。
Excelから解放されてmdやyamlで管理できるようになり、Gitで差分を確認できるので作業漏れが少なくなりそうです。
4.3. よく使うコマンド集
上記以外でよく使うコマンドをまとめてみした。 他にも便利な機能があるので公式ドキュメントを参照してください。
コマンド一覧
| Command | 実行する処理 |
|---|---|
dbt run |
dbtプロジェクト全体を実行 |
dbt run --select (モデル名) |
対象モデルのみ実行 |
dbt run --select +(モデル名) |
対象モデルとその上流モデル全てを実行 |
dbt run --select (モデル名)+ |
対象モデルとその下流モデル全てを実行 |
dbt run --select +(モデル名)+ |
対象モデルとその上流・下流モデル全てを実行 |
dbt run --select tag:(タグ名) |
対象タグが付与されたモデルを全て実行 |
dbt docs generate |
ドキュメントファイルの作成 |
dbt docs serve |
ドキュメント用サーバーの立ち上げ |
dbt compile |
実行可能なSQLへコンパイルを実行(target配下に生成) |
dbt debug |
デバッグ |
(トップへ)
5. まとめ
複雑なデータ加工処理で生成されるデータマート運用の際に
- 運用におけるリカバリに係る稼働とコンピューティング費用を削減する
- テーブル変更時に発生するドキュメント修正を抜け漏れなく対応できるような開発環境を構築する
といった課題が発生していました。 これらの課題解決に向けて、デファクトスタンダートツールであるdbtを導入した上で、SQL一括実行機能とデータリネージュ作成機能を活用することにしました。
実際に導入すると、
- コマンド一つで必要なところへリカバリが可能になった
- 編集忘れのしにくい開発環境とGitで差分を確認できるドキュメント開発環境が整備された
といった具合に課題をうまく解消することができました。 一方で、管理しているSQLが膨大なため、既存の標準SQLで作成したコードをdbt形式に書き換える作業が大変でした。すでに、大量のSQLソースコードを抱えているシステムへdbtを導入するには、作業量が膨大になるのでそこはハードルが高いかもしれないと感じました。
とはいえ、今後の稼働削減のことを考えると導入してみてよかったですし、同様の課題を抱えている方はぜひトライしていただきたいと考えています。
(トップへ)