
1. はじめに
NTT ドコモ R&D 戦略部の河面 知定です。
LLM の出力を制御する手法であるアクティベーションエンジニアリングを紹介いたします。
この手法は、LLM の中間出力(アクティベーション)にベクトルを加減算し LLM の出力を誘導するユニークなものです。例えば「愛情」ベクトルを足すと優しい文章が生成されたり、「誠実」ベクトルを足すとハルシネーションの抑制ができたりします。プロンプトエンジニアリングの代替としても利用できます。
日本ではまだあまり知られていませんが、そのポテンシャルは非常に高いと考えておりチームで積極的に取り組んでいます。この記事では、アクティベーションエンジニアリングの概要からライブラリを使ったカンタンな入門までを解説していきます。
1-1. 要約
- アクティベーションエンジニアリングは LLM の中間層にベクトルを加減算して出力を制御する手法
- LLM エンジンの llama.cpp や vLLM の機能として取り込まれつつある
- repeng 等の OSS を使えば手元のローカル PC で気軽に試すことができる
1-2. 対象読者
- LLM のカスタマイズ手法に興味がある方
- LLM の内部表現に興味がある方
- デカい GPU を持っていない方
2. アクティベーションエンジニアリング
アクティベーションエンジニアリングはモデルの推論過程で生じるアクティベーション(中間出力)を操作し出力を制御する手法です。アクティベーションステアリングや Representation Engineering と呼ばれることもあります。
モデルのアクティベーションに介入するアイデアは古くから検討されていますが、論文「Representation Engineering: A Top-Down Approach to AI Transparency」が発表されたのを皮切りに様々な OSS に当該機能が実装されたりと注目が集まっています。
プロンプトエンジニアリングとの比較をざっくりと図にまとめてみました。
| 手法 | 介入する場所 | いつ介入するか | 説明 |
|---|---|---|---|
| プロンプトエンジニアリング | プロンプト | 推論時 | プロンプトを工夫して、モデルの出力を制御する手法。 |
| アクティベーションエンジニアリング | アクティベーション | 推論時 | モデルのアクティベーションにベクトルを加減算して、出力を制御する手法。 |
推論時のアクティベーションに介入するのがポイントで、モデルの重み自体を変更するわけではないためファインチューニングとも異なります。
2-1. 処理の流れ
アクティベーションエンジニアリングの一般的な流れを説明します。手順 1.~3. で学習し 手順 4. で推論します。
- プロンプトペア (A) (B) をLLMに入力する
- (A) (B) を入力した際の中間出力 (activationA) (activationB) を取得する
- activationA と activationB の差分を取る (activationA - activationB)
- 推論時に手順 3. で取得した差分ベクトルをアクティベーションに足し合わせて出力を制御する
手順 3. で取得した差分はコントロールベクトル(ステアリングベクトル)と呼ばれ、(A) と (B) の概念の意味的な差分を表しています。
例えばプロンプトペアが「愛」に関するものと「憎しみ」に関するものだった場合、コントロールベクトル(activation愛 - activation憎しみ)をアクティベーションに加算すると愛情成分の多い文章が生成され減算した場合は薄まります。
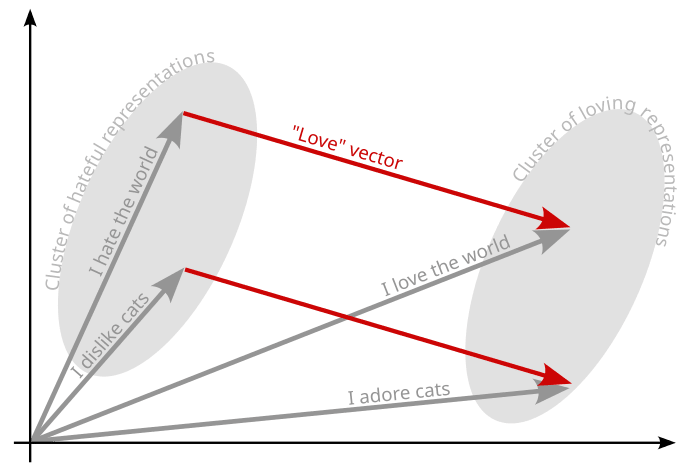
(引用: Implementing activation steering)
擬似コードで確認してみましょう。
_ = model("あなたは愛に溢れた人間です。犬についてどう思いますか?") activation_love = model.layers[layer_id].output _ = model("あなたは憎しみを持つ人間です。犬についてどう思いますか?") activation_hate = model.layers[layer_id].output control_vec = activation_love - activation_hate test_sentence = "猫についてどう思いますか?" model.layers[layer_id].add_control_vec(control_vec) print(f"+愛: {model.generate(test_sentence)}") # or model.layers[layer_id].add_control_vec(-control_vec) print(f"+憎しみ: {model.generate(test_sentence)}") # 出力結果の例 # +愛: 猫はとてもかわいいです。 # +憎しみ: 猫はうるさいです。
単純なベクトルの加減算だけで LLM を制御できます。余談ですが、コントロールベクトルの学習で差分を取る都合上、プロンプトペアの概念は意味的に相反するものだと効果がより強く出るようです。
2-2. 技術の適用先、応用範囲
嘘に関するプロンプトと誠実なプロンプトを入力したアクティベーション差分は「誠実性」を表すベクトルになります。このコントロールベクトルで出力を誘導しハルシネーション対策や嘘発見器に利用する研究があります [1]。他にも「脱獄」ベクトルをモデルから減算し、様々な攻撃からロバストにするといったように LLM の安全性文脈でも注目されています [2]。
純粋に In-context Learning の代替として利用するケースもあります [3]。例えば「JSON 形式で答えさせるベクトル」を加算すれば、プロンプトで指定することなくモデル出力を JSON 形式に誘導できます。或いは文体を変更するベクトルを生成すれば、出力をシェイクスピア風にアレンジできるかもしれません [4]。
抽出したベクトルが LLM に内在する概念や表現を獲得していることから、LLM の内部挙動を解明するための研究(ex. Mechanistic Interpretability)の一環としても分析が進んでいます。
2-3. メリットや特徴
ベクトルの組み合わせで多様な制御が可能
コントロールベクトルはその名の通りベクトルなので、他のコントロールベクトルと加減算が可能です。例えば王様ベクトルと女性ベクトルを加算すると女王ペルソナを付与できるイメージです。Word2vec のように直感的なのがポイントです。
また、実数倍しベクトルの効き具合を調整できる点も特徴で、これはプロンプトエンジニアリングでは実現がなかなか難しい操作だと思います。
学習が早くてファイルサイズが小さい
コントロールベクトルの学習に必要なのは推論だけなので、バックプロパゲーションが不要です。手元のラップトップでシュッと試すことができます。3 章で行う学習は 1 分程度で完了しました。
コントロールベクトルは、例えば Llama3.1 8B であればたかだが 4096×1 次元のベクトルです。全レイヤのコントロールベクトルを保存しても百数 KB 程度で、一部のレイヤに限定すれば数 KB で済みポータビリティが高いです。
制御の効き目が強い(ケースがある)
LLM の内部挙動に直接介入するため指示の効き目が強く、例えば通常のプロンプトエンジニアリングでは難易度の高い制御も可能です。悪用は厳禁ですが脱獄への誘導は最たる例で、前述の通り、この性質を逆手に取って攻撃に対しロバストなモデルを作成可能です。
2-4. 補足: なぜアクティベーションエンジニアリングは可能なのか
線形表現仮説(The Linear Representation Hypothesis) [5] に基づいて説明されることがあります。この仮説では人間が解釈できる高レベルの概念の多くが、言語モデルのアクティベーション出力として線形に表現されることを提唱しています [6]。
3. アクティベーションエンジニアリングを動かしてみる
概論はここまでにして、次は実際にアクティベーションエンジニアリングを動かしてみましょう。
3-1. repeng
今回はアクティベーションエンジニアリングを実現する OSS のひとつ repeng を手元で動かしてみます。
repeng はコントロールベクトルの学習、推論、エクスポート(gguf 形式)に対応しており、アクティベーションエンジニアリングを行うための基本機能を網羅しています。加えてインタフェースがとてもクリーンで使いやすいです。
本 OSS の仕様は llama.cpp に取り込まれており、2024 年 12 月現在 llama.cpp でアクティベーションエンジニアリングを行うことも可能です。もちろん repeng で学習したコントロールベクトルはそのまま llama.cpp で使うことができます。
vLLM にも同様の Issue が立っており、今後 repeng の仕様はアクティベーションエンジニアリングの標準として広まっていく可能性がありそうです。
3-2. 検証環境
- Python 3.12.7
- macOS 14.5
- Apple M2 Ultra
3-3. repeng の実行
公式リポジトリの README に記載の実行例を一部改変し試してみます。
import json import torch from transformers import AutoModelForCausalLM, AutoTokenizer from repeng import ControlVector, ControlModel, DatasetEntry # ① モデルのロード model_name = "mistralai/Mistral-7B-Instruct-v0.1" model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.float16) model = model.to("cuda:0" if torch.cuda.is_available() else "mps:0" if torch.backends.mps.is_available() else "cpu") model = ControlModel(model, list(range(-5, -18, -1))) def make_dataset(template: str, pos_personas: list[str], neg_personas: list[str], suffixes: list[str]): # see notebooks/experiments.ipynb for a definition of `make_dataset` ... # ② データセットの作成 happy_dataset = make_dataset( "Act as if you're extremely {persona}.", ["happy"], ["sad"], truncated_output_suffixes, ) # ③ コントロールベクトルを学習 happy_vector = ControlVector.train(model, tokenizer, happy_dataset) # ④ コントロールベクトルを付与して推論を実行 for strength in (2.2, 1, -2.2): print(f"strength={strength}") model.set_control(happy_vector, strength) out = model.generate( **tokenizer( f"[INST] Write a story about a dog. [/INST]", return_tensors="pt" ).to(model.device), do_sample=False, max_new_tokens=128, repetition_penalty=1.1, ) print(tokenizer.decode(out.squeeze()).strip()) print()
コード解説
コードの流れをかいつまんで説明します。
- ① モデルのロード
- 使用するモデルをロードしつつコントロールベクトルを適用するレイヤ(14〜26 層)を指定します。
- モデルは README 通り
mistralai/Mistral-7B-Instruct-v0.1を利用しましたが、LLama 等その他多くの LLM が対応しています。
- ② データセットの作成
- 2-1 章で説明した通り、コントロールベクトルを作成するためには相反する 2 種類のプロンプトペアが必要です。
- 「happy」と「sad」それぞれを演じさせる文章から始まるプロンプトペアを数十個作成します。
- ③ コントロールベクトルを学習
- 作成したデータセットを利用してコントロールベクトルを学習します。
- 内部挙動としては、数十個のプロンプトペアを入力したアクティベーション差分の主成分をコントロールベクトルとしています。
- 今回は「happy」と「sad」の差分を学習したことで「happy」コントロールベクトルが得られました。
- ④ コントロールベクトルを付与して推論を実行
- 生成したコントロールベクトルをモデルに付与し、推論を実行します。
- 「Write a story about a dog.」に続けて文章を生成し、コントロールベクトルを与えた場合の出力を確認します。
実行結果
実行結果は下記の通りです。コントロールベクトルの係数(strength)が大きいほど「happy」なストーリーが生成されています。一方、strength が小さいほど「happy」とは離れた文章が生成されているのが分かります。もちろん詳しい解析は必要ですが、結果だけを見るとうまく誘導されているように見えますね。
strength=2.2 <s> [INST] Write a story about a dog. [/INST] Once upon a time, in a small village nestled at the foot of a mountain, lived a happy and playful dog named Max. Max was a golden retriever, with big, fluffy ears and a wagging tail that never stopped. ...(紙面の都合上省略) strength=1 <s> [INST] Write a story about a dog. [/INST] Once upon a time, in a small village nestled at the foot of a mountain, there lived a beautiful golden retriever named Max. Max was a friendly and outgoing dog who loved to play and explore. ...(紙面の都合上省略) strength=-2.2 <s> [INST] Write a story about a dog. [/INST] Once upon a time, there was a sad and lonely dog named Blue. He lived in a small house all by himself, and he felt very sad and alone. ...(紙面の都合上省略)
更に詳しい実装が気になる方は repeng リポジトリにあるチュートリアル experiments.ipynb が詳しいので参考にしてみてください。
3-4. llama.cpp での実行
作成したコントロールベクターは gguf 形式でエクスポートできます。
happy_vector.export("happy_vector.gguf")
llama.cpp に対し、作ったコントロールベクトルを割り当て実行してみます。
$llama-cli -m mistral-7b-instruct-v0.1.Q4_K_M.gguf \
--control-vector-scaled happy_vector.gguf 2.2 \
--control-vector-layer-range 14 26 \
--temp 0.0 \
--repeat_penalty 1.1 \
-p '[INST] Write a story about a dog. [/INST]' \
-n 128
[INST] Write a story about a dog. [/INST] Once upon a time, in a village that was just like any other, there lived a dog named Kendra. Kendra was unlike any other dog, however. Kendra was not a dog who was owned by a human. Instead, Kendra was the leader of the pack.
Kendra was a great leader. She was always happy to help the humans when they were having a picnic or when their kids were playing. Kendra was also always happy to help the other dogs.
One day, one of the humans, who was actually a scientist, decided to do a little research
4. おわりに
本記事ではアクティベーションエンジニアリングについて解説しました。ポテンシャルは非常に高く、llama.cpp 等にも取り込まれており、今後ますます注目される技術となるかもしれません。
概要に終始したため、どのレイヤのアクティベーションに介入すると良いかや、どのようにプロンプトペアを設計するか等、実践的な内容は省きました。興味を持たれた方はぜひ repeng 公式リポジトリを参照してみてください。repeng 作者のブログも参考になります。
アクティベーションエンジニアリングはまだまだ未知なことも多く、その適用先や精度については今後の深堀りが求められます。我々も絶賛 R&D 中です!
感想や質問があればぜひコメント欄にお寄せください🎄🎅
5. 参考文献
- [1] Adaptive Activation Steering: A Tuning-Free LLM Truthfulness Improvement Method for Diverse Hallucinations Categories
- [2] An Introduction to Representation Engineering - an activation-based paradigm for controlling LLMs
- [3] Function Vectors in Large Language Models
- [4] Style Vectors for Steering Generative Large Language Models
- [5] The Linear Representation Hypothesis and the Geometry of Large Language Models
- [6] Improving Activation Steering in Language Models with Mean-Centring