
- 1. 動画生成の自動化を目指して
- 2. 技術選定:なぜGodotなのか?
- 3. Agentic Codingの実践(AIとの協業ログ)
- 4. 成果物:Agent Movie Maker
- 5. まとめと今後の展望
こんにちは、R&D戦略部の北川です。 タイトルにUE勢とありつつも、私はUEに精通しているわけではありませんが、Unreal Engineの表現力に魅了され、去年・一昨年とUEネタで以下のような記事を書いてきました。 しかし今年は、あえてGodot Engine (4.5.1 .NET) を選定しました。
「えっ、あんなにUE推しだったのに何故?」と思われるかもしれませんが、その理由は、描画性能でも機能の多さでもありません。 「生成AI(AIエージェント)との親和性が、Godotはずば抜けて高かったから」です。
今回は、「動画を作るのが面倒なら、動画を自動生成するツールを作ればいいじゃない」と発想し、私とAIエージェント(Claude Opus 4.5)がペアプロで作り上げるまでの「Agentic Coding」の記録と、そこから得られた様々な示唆についてお話しします。
重要: 本記事における検証および開発は、筆者の個人的な興味に基づいて行われたものであり、業務内容とも無関係かつ業務環境とも分離された個人環境で実施しています。
1. 動画生成の自動化を目指して
これまでUEを使った映像・空間表現、キャラクター表現を模索してきましたが、大きな課題がありました。 「撮影と編集に時間がかかりすぎる」ことです。
もちろん、UEにはSequencerやMovie Render Queueなど強力なツールが揃っています。しかし、私自身がUEを使いこなせているとは言い難く、そうした機能を駆使して効率化するにはまだ修行が足りません。 それに、そこで素晴らしい画が撮れても、それをタイムラインに並べ、音を合わせ、エンコードする……この物理的な作業コストが重くのしかかります。 そこで私は思いました。
「台本(テキスト)さえ渡せば、勝手にキャラが喋って動いて、動画ファイルが出てくるツールがあればいいのに」
もちろん、UEにもPython APIによる自動化や、最近ではMotion Designモードのような効率化機能が充実してきています。さらにUE5.7ではAIアシスタント機能も搭載されているので、UE×Agentic Codingが可能になる未来も近いかもしれません。
しかし、私が今回求めているのは、超高品質なシネマティック映像ではありません。「とりあえずキャラが動いて動画になればいい」というシンプルな要件です。 そう考えた時、バイナリ管理が中心で重厚長大なUEよりも、全てのファイルがテキストで構成され、AIが直接読み書きしやすいGodotの方が、今の私とAIエージェントのペアには相性が良いのではないか?
UEの知識はあってもGodotの知識はゼロの私よりGodotエンジニアとして優秀な彼らに「これ作って」と頼んだら、一体どうなるのか? そんな実験からこのプロジェクトは始まりました。
ちなみに2日ちょっとで出来たものはこちら(GIFなので音声が無いですが、実際には合成音声が喋っています)
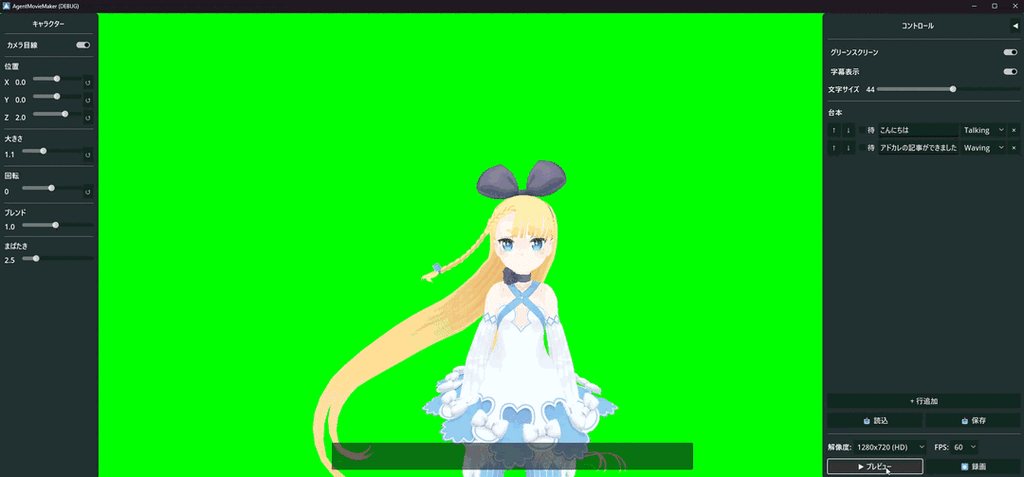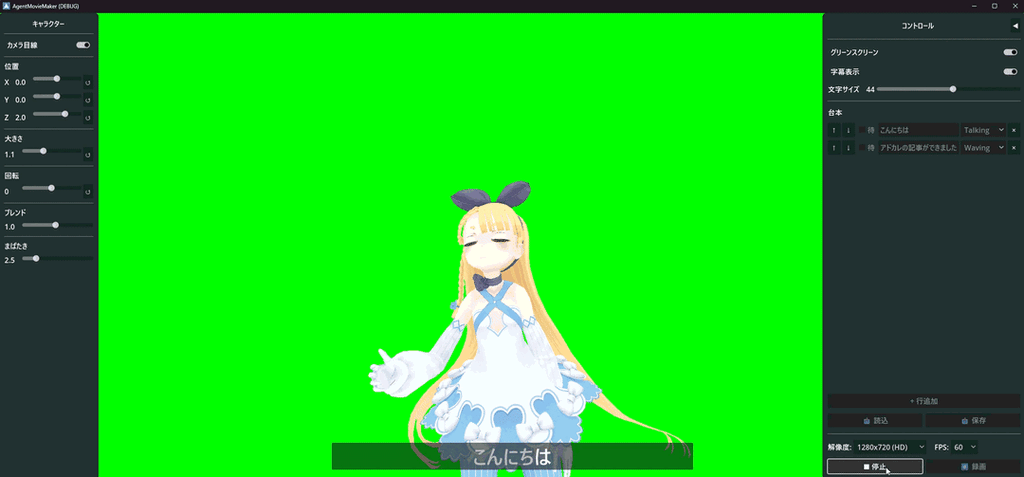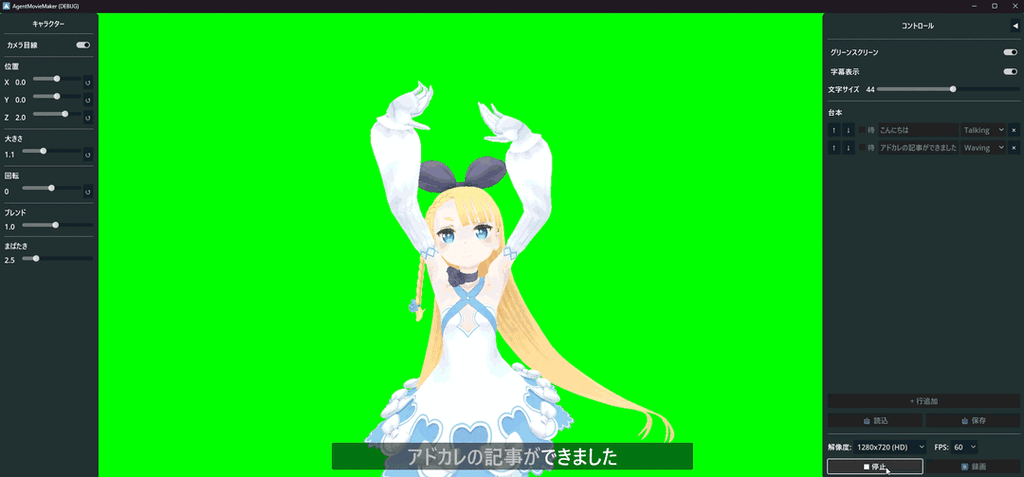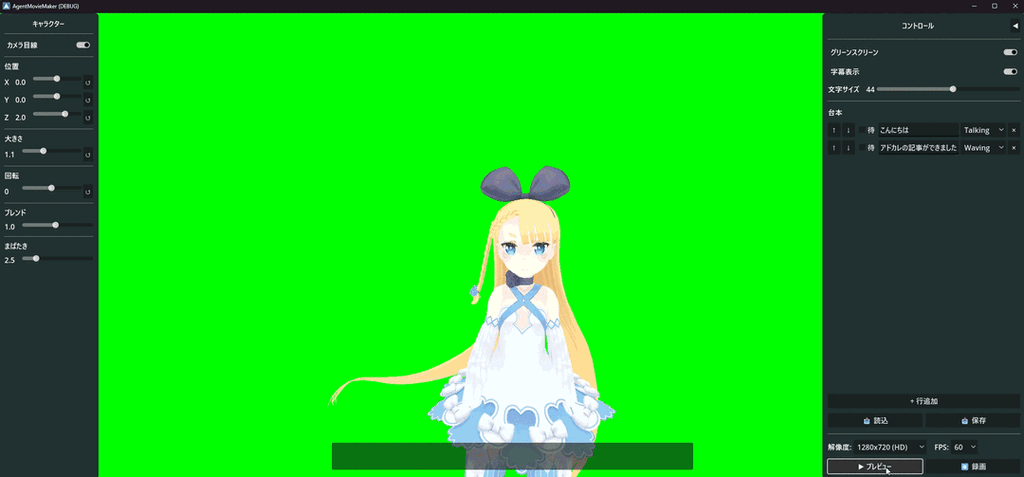
2. 技術選定:なぜGodotなのか?
AIエージェントとの協議の結果、今回採用されたのは Godot Engine でした。 その決定的な理由は「テキストベースであること」に尽きます。
テキストベース vs バイナリ
Unreal EngineのBlueprintやアセットファイル(.uasset)はバイナリ形式であることが多く、外部の生成AIが直接読み書きするにはハードルが高いです。 一方、Godotは主要なファイルがテキスト形式です。
- シーンファイル (.tscn): TOMLライクなテキスト。構造が極めてシンプル。
- スクリプト (.gd / .cs): 純粋なソースコード。
- リソース (.tres): 設定ファイルもテキスト。
AIにとって、これらは「読む」のも「書く」のも非常に容易です。Gitでの差分比較も簡単で、「AIがどこを直したか」が人間にとっても一目瞭然です。 これは、何度も修正と実行を繰り返す Agentic Coding(自律的な試行錯誤) において非常に有利な特性となります。
高速なイテレーション
AIエージェントがコードを書き、修正案を出す。人間がそれを実行してエラーログを返す……。 このループを回す時、Godotの「起動の速さ」はそのまま生産性に直結します。UEのエディタ起動やシェーダーコンパイルを待つ数分の間に、Godot×AIなら数回修正ループが回せます。
ライセンスとポータビリティ
そして MITライセンス であること。
成果物のツールとして配布したり、将来的にサービス化したりする際、権利関係がクリアであることは精神衛生上非常に良いです。
今回は使用するライブラリも godot-vrm (MIT) など、完全にクリーンな構成にこだわりました。
3. Agentic Codingの実践(AIとの協業ログ)
開発は、「私が仕様をまたぎ、AIが実装し、私が実行する」というサイクルで進みました。今回私が書いたコードは0文字です。 しかし、単にAIにコードを書かせただけではありません。いくつかの技術的な壁を、AIとの対話で乗り越えてきました。
開発ログ(DevLog)という共有メモリ
まず行ったのは、AIとの会話の内容や決定事項を記録し続けることでした。 具体的には、技術的な選択とその理由、直面した問題と採用した解決策、保留中の課題やTODO、採用したライブラリとそのライセンス情報などを記録しています。 AIのコンテキストウィンドウには限りがありますが、このログを毎回読ませることで、モデルが切り替わっても(内部のAIモデルをClaudeからGeminiへバトンタッチしても)「文脈」や「意図」を失わずに開発を継続できました。このログはAntigravityのルール設定を使って、都度自動更新させていました。
具体的なトラブルシューティング事例
開発中に直面し、AIと協力して解決した課題の一部を紹介します。これらはほぼAIの提案により解決しました。
- リップシンクの遅延対策:
- TTS(合成音声)の生成時間とオーディオ出力の遅延により、口パクがズレる問題が発生。
- AIの提案により、「150msの先読み(Lookahead)」を実装し、さらにTTSが句読点で詰まる癖を
PromptBuilderで強制的に間を入れることで緩和しました。(この調整だけで約25ターンのやり取りを要しました。完全完璧とはいきませんが、アドカレネタとしては許容できるレベルには達しました)
- VRMロード方式の変更:
- ランタイムで
GLTFDocumentを使ってVRMを再パースすると、リターゲット処理が二重適用されて手足が曲がる問題が発生。 - AIの調査により、Godotエディタで事前インポートされた
.scnファイルをload().instantiate()で読み込む方式に変更して解決。
- ランタイムで
- TTS音声によるネイティブクラッシュ:
- TTSで生成した音声を再生すると、断続的に「Signal 11 (SIGSEGV)」でクラッシュする問題が発生。
- 原因は、
System.Speechが生成するWAVデータにはRIFFヘッダー(44バイト)が含まれているが、GodotのAudioStreamWav.Dataはヘッダーなしの生PCMデータを期待していたこと。ヘッダー込みのまま渡すとメモリ違反が発生していた。 - AIの提案により、WAVヘッダーを解析して生PCMデータのみを抽出する処理を追加してある程度解決。
- ハイブリッド・アーキテクチャ:
- 「ロジックはC#、View(VRM操作)はGDScript」という役割分担。これもGodotのアドオン資産を活かしつつ、型安全な設計にするためのAIからの提案でした。
「人間」というアクチュエータ
面白かったのは、「人間がAIの手足になる」瞬間が多々あったことです。
AI「この機能にはMixamoのアニメーションデータが必要です。以下のURLから...」
私「了解(Mixamoへログイン、ダウンロードポチポチ)」
APIがないWebサイトからのダウンロードや、素材の配置といった物理作業は、まだAIだけでは完結しません。 「高度な判断とコーディングはAIがやり、単純な物理作業は人間がやる」 という、逆転した主従関係のような作業は、Agentic Codingの過渡期ならでは体験かもしれません。
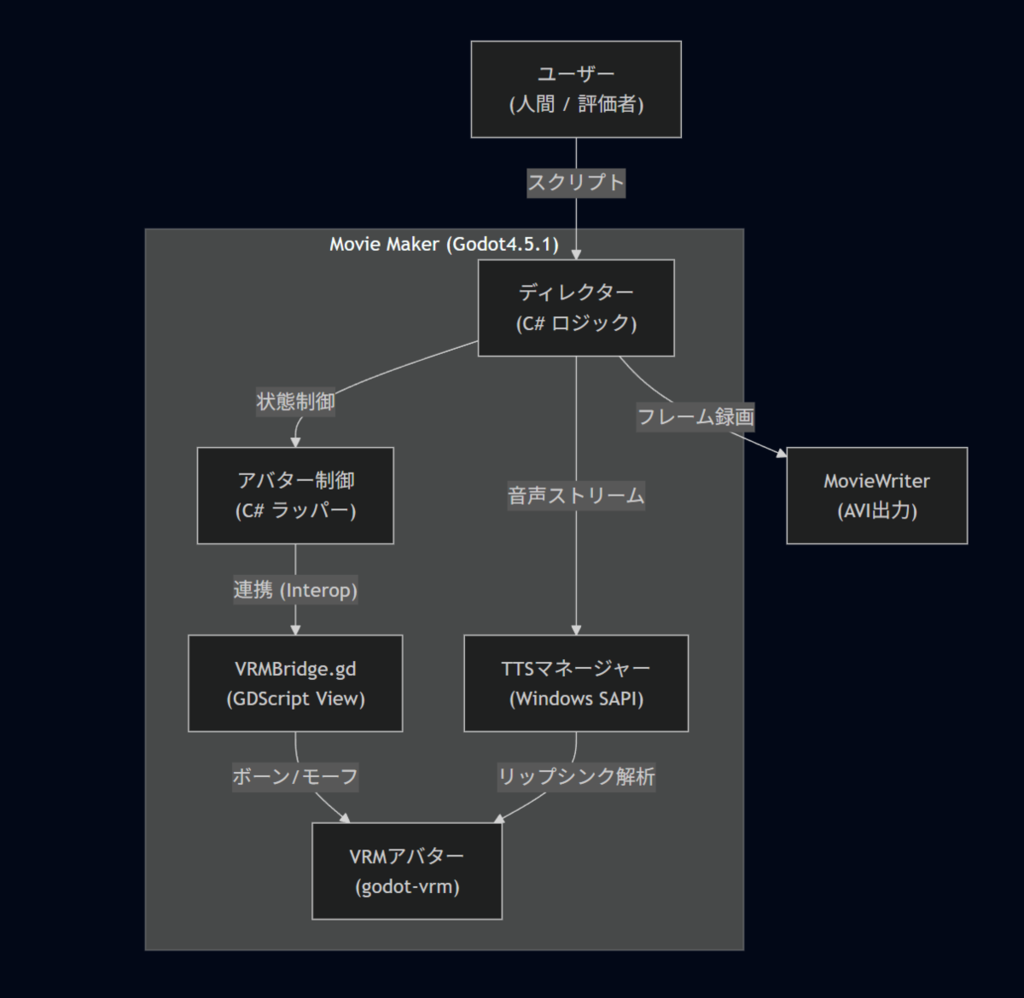
4. 成果物:Agent Movie Maker
こうしてGodot未経験者のAgentic Codingによって完成したのが、自動動画生成ツール 「Agent Movie Maker」 です。動作検証用のVRMモデルには定番のアリシア・ソリッドを使用しています。3d.nicovideo.jp


スクリプトファイル(テキスト形式の台本)を読み込ませて録画ボタンを押すだけで、アバターが身振り手振りとボイスを交えて解説し、最終的に .avi ファイルとして書き出されます。動画出力にはGodotのMovieWriter機能を使っているため、高品質な動画出力が可能です。
Windows標準のTTSを使っているため、追加のAPIキーなども不要で、ローカルで完結して動きます。*1
データ形式(.script サンプル)
台本は以下のような独自のテキスト形式で記述します。ここから位置座標なども指定可能です。このフォーマットもAIが提案してくれました。私は、利用者やスクリプト制作者が『直感的に理解できる書式であること』とだけ指示していました。このフォーマットをLLMに渡せば台本生成も簡単にできるでしょう。
# 台本ファイル例 @設定 位置X=-0.10 @設定 位置Y=0.40 @設定 カメラ目線=True [Waving] こんにちは!今日はNTTドコモについてご紹介します。 [Talking] ドコモは日本最大の携帯電話事業者です。 [idle] @待機 1.0 [Clapping] 家族割やドコモ光とのセット割引でお得に使えるのも魅力です!
実装機能リスト
- テキスト台本読み込み: 独自形式のパースと再生。アバターの位置、回転、スケールもスクリプトから制御可能。
- VRMアバター制御:
godot-vrmをラップし、表情モーフやボーン制御を行う。 - モーションブレンド: アニメーション切り替え時のクロスフェード処理。
- オートリップシンク: TTSの波形データからのリアルタイム口パク推定。
- 字幕: セリフの字幕表示機能。フォントサイズ調整・ON/OFF切替可能。
- GUI調整機能: アバターの座標や回転などをスライダーで直感的に調整可能。
- 動画書き出し: FPSや解像度、保存パスを指定してAVIとして録画保存。
開発スタッツ
- 開発期間: 約2.5日間(実働時間)
- AIとの対話回数(ターン数): 約 350ターン以上
- 複数のセッションにまたがり、設計から実装、デバッグまで細かく対話を重ねました。
- 人間が書いたコード行数: ゼロ
開発環境・スペック
- OS: Windows 11
- Engine: Godot 4.5.1 .NET Edition
- AIエージェント:
- エディタ: Antigravity
- アーキテクチャ: Claude Opus 4.5 — アーキテクチャ設計や大きな方針決定に強い印象。
- 改善: Gemini 3 Pro — 細かいデバッグ、試行錯誤で使える印象。逆に大きなことをやらせると余計なことをする。
- (開発が詰まったり上限に達したら内部モデルをGeminiに交代する運用でした)
- Tech Stack:
- アバター: VRM (via
godot-vrm) - ボイス: Windows Standard SAPI (System.Speech)
- アバター: VRM (via
5. まとめと今後の展望
今回、AIエージェントとツールを作ってみて感じたのは、「作る」というプロセスの重心が変わったということです。
これまで「どう実装するか(How)」に多くの時間を割いていましたが、AIとの開発では「何を作るか(What)」、そして「どんな体験にしたいか」を定義することに集中できました。
ただし、これは「実装(How)を全く考えなくていい」という意味ではありません。むしろ、描いた体験(What)を正確に形にするために、「的確なアーキテクチャを描く」「細部の品質を自ら調整する」といった、要所での介入は不可欠でした。AIは優秀なパートナーですが、彼らが作ったものが「本当に良い体験になっているか」を評価し、導くのは人間の役割です。
今回の件で言えば『「面白い動画」とは何か。「心地よい動き」とは何か。』——そういった「意思」や「意図」を言語化してAIに伝える能力こそが、これからのクリエイターに求められるスキルになるだろうと実感しました。
来年のアドベントカレンダーは、もしかしたら企画から執筆まで、全て私の代わりにAIがやっているかもしれません。 それでも「読者に何を伝えたいのか」という楽しい部分は人間が考えていたいですね。
*1:もちろん、可愛らしいAIキャラクターにとって「声」が命であることは重々承知しています。本当はリッチな音声合成モデルを使いたいところですが、今回は「完全ローカル・APIキー不要」の手軽さを優先しました。