
はじめに
この記事はドコモアドベントカレンダー19日目の記事になります。
NTTドコモサービスイノベーション部2年目社員の上田です。
業務では主に、AI等デジタルマーケティング技術の企業活動適用を行っております。
最近はVUCA (Volatility、Uncertainty、Complexity、Ambiguity) の時代で、不確実性が高く将来の予測が困難とも言われております。
しかし、予測しづらいから何もしなくていいや〜というのではなく、過去蓄積されてきたデータと最新のAI技術を用いてある程度定量的に未来を予測したいですよね。
ということで、今回はPythonで将来の時系列予測を行うことができる、Greykiteという、2021年にLinkedInが開発したライブラリを紹介いたします。
執筆当時は実装に関する日本語の記事がほとんどなく、Greykiteを利用する際はぜひ本記事をご参考にしていただけたら幸いです。
対象者
- Pythonでの時系列予測に興味がある方
- Greykiteを実際に使ってみた所感を知りたい方
内容
- Greykiteについて
- 公式ドキュメントを元にGreykiteを試した結果
- Silverkite (Greykiteのメインアルゴリズム)、Prophet、Autoarimaの結果比較
Greykiteとは
概要
LinkedInが開発した、Pythonによって時系列の予測を行えるライブラリです。
LinkedInの多くの事業部門でGreykiteが活用されているそうです。
本ライブラリについての論文は、機械学習分野のトップカンファレンスであるKDD 2022で採択されておりました。
主要な特徴は以下の4つです。
- 簡単に始められる
- 高速なアルゴリズム
- 柔軟な設計
- 解釈可能なアプローチ
実装してみたところ、時系列の知識があまりいらなく、割と容易に実装ができる感触でした。
メインのアルゴリズムはSilverkiteであり、他にもMetaが開発した Prophet と、時系列モデルの定番であるARIMAを用いた Auto-ARIMA(pmdarima)のインターフェースも含まれています。
つまり、Greykiteを利用することで、Silverkite、Prophet、Auto-ARIMAを用いることができます。
Silverkiteのアーキテクチャ図は以下の通りです。(論文より)

理論部分として、日本語記事ではこちらの記事が参考になりましたのでご紹介いたします。
時系列ライブラリの例
時系列ライブラリにどのようなものがあるか、こちらの記事で調査されていた結果を引用させていただきます。(2022/9/30現在)
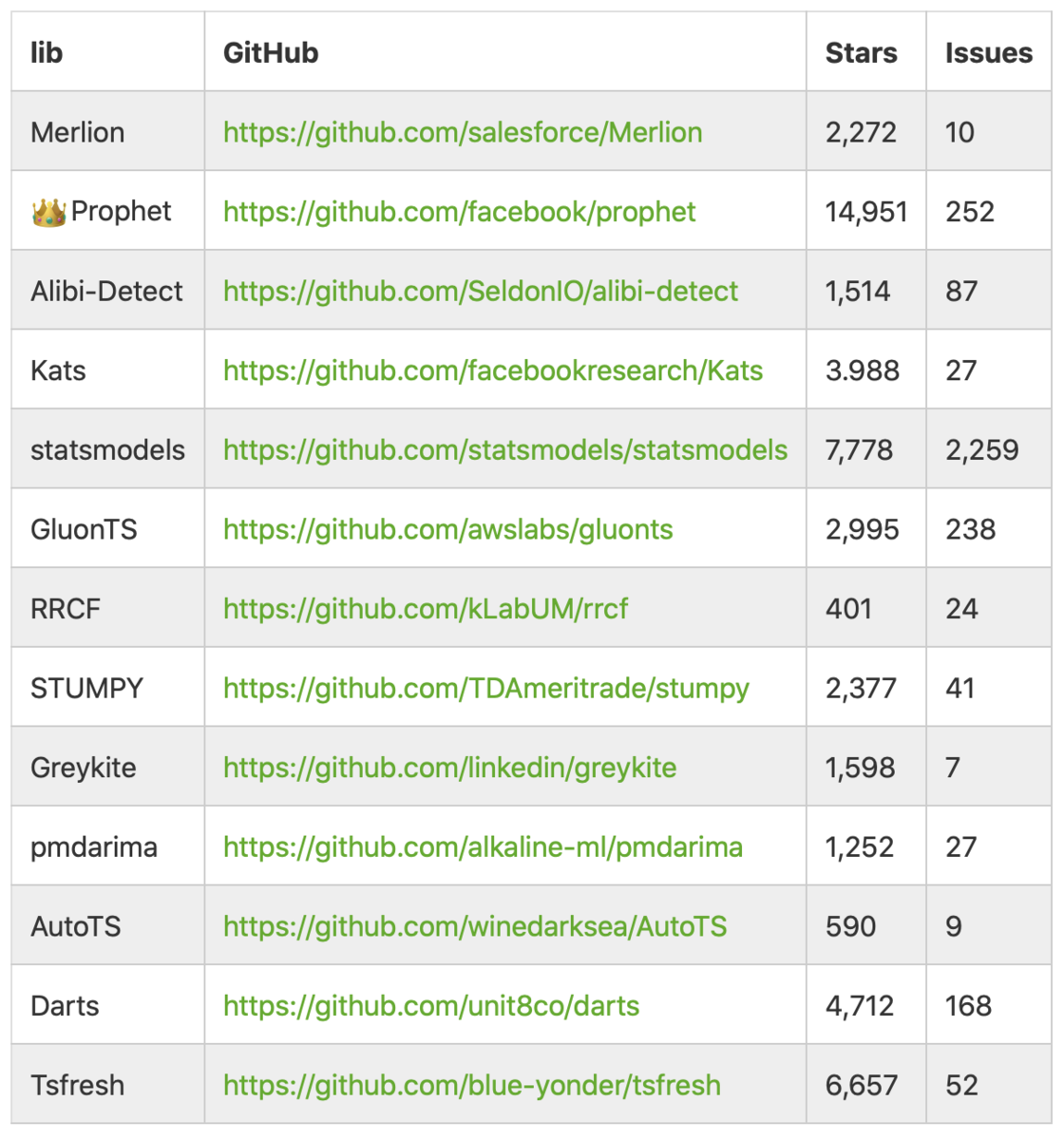
ProphetのStars数が他を圧倒していますね。
Greykiteは最近発表されたものでまだ多くはなく、これからの発展に期待です。
Greykiteを用いたSilverkite
本章では、GreykiteのメインアルゴリズムであるSilverkiteの実装を進めていきます。
環境構築
Greykiteは以下のpipコマンドでインストールすることができます。
!pip install greykite
依存関係にある他ライブラリも同時にインストールしてくれます。
詳細なインストール手順やFAQは、こちらをご確認ください。
筆者の環境は以下の通りです。
Python 3.8.12 Greykite 0.4.0
以下で、あらかじめGreykiteのモジュールをimportしておきます。
モジュールのimport
from greykite.common import constants as cst from greykite.common.data_loader import DataLoader from greykite.common.evaluation import EvaluationMetricEnum from greykite.common.features.timeseries_features import build_time_features_df from greykite.common.features.timeseries_features import convert_date_to_continuous_time from greykite.common.constants import TIME_COL from greykite.common.viz.timeseries_plotting import add_groupby_column, plot_multivariate, plot_univariate from greykite.algo.changepoint.adalasso.changepoint_detector import ChangepointDetector from greykite.algo.forecast.silverkite.constants.silverkite_holiday import SilverkiteHoliday from greykite.algo.forecast.silverkite.constants.silverkite_seasonality import SilverkiteSeasonalityEnum from greykite.algo.forecast.silverkite.forecast_simple_silverkite_helper import cols_interact from greykite.framework.benchmark.data_loader_ts import DataLoaderTS from greykite.framework.input.univariate_time_series import UnivariateTimeSeries from greykite.framework.constants import MEAN_COL_GROUP, OVERLAY_COL_GROUP from greykite.framework.utils.result_summary import summarize_grid_search_results from greykite.framework.templates.autogen.forecast_config import ModelComponentsParam from greykite.framework.templates.autogen.forecast_config import ComputationParam from greykite.framework.templates.autogen.forecast_config import EvaluationMetricParam from greykite.framework.templates.autogen.forecast_config import EvaluationPeriodParam from greykite.framework.templates.autogen.forecast_config import ForecastConfig from greykite.framework.templates.autogen.forecast_config import MetadataParam from greykite.framework.templates.forecaster import Forecaster from greykite.framework.templates.model_templates import ModelTemplateEnum from greykite.framework.benchmark.data_loader_ts import DataLoaderTS from greykite.framework.input.univariate_time_series import UnivariateTimeSeries from greykite.framework.benchmark.benchmark_class import BenchmarkForecastConfig from greykite.framework.benchmark.data_loader_ts import DataLoaderTS from greykite.framework.templates.autogen.forecast_config import(ComputationParam,EvaluationMetricParam, EvaluationPeriodParam, MetadataParam, ForecastConfig,ModelComponentsParam) from greykite.sklearn.cross_validation import RollingTimeSeriesSplit
また、Greykiteの可視化にはPlotlyが用いられており、Jupyter Notebookを利用する方は、結果を表示するために以下も実行させておくと良いです。
from plotly.offline import init_notebook_mode, iplot init_notebook_mode()
データ取得
今回はGreykiteのライブラリに含まれているデータセットの中で、Daily Peyton Manning datasetを用いていきます。
こちらはPeyton Manningさんというアメリカの元アメリカンフットボール選手のWikipediaページのlog(日次ページビュー数)が格納されております。
Prophetのデモに使われた主要なデータセットの一つです。
dl = DataLoaderTS() ts = dl.load_peyton_manning_ts() df = ts.df df
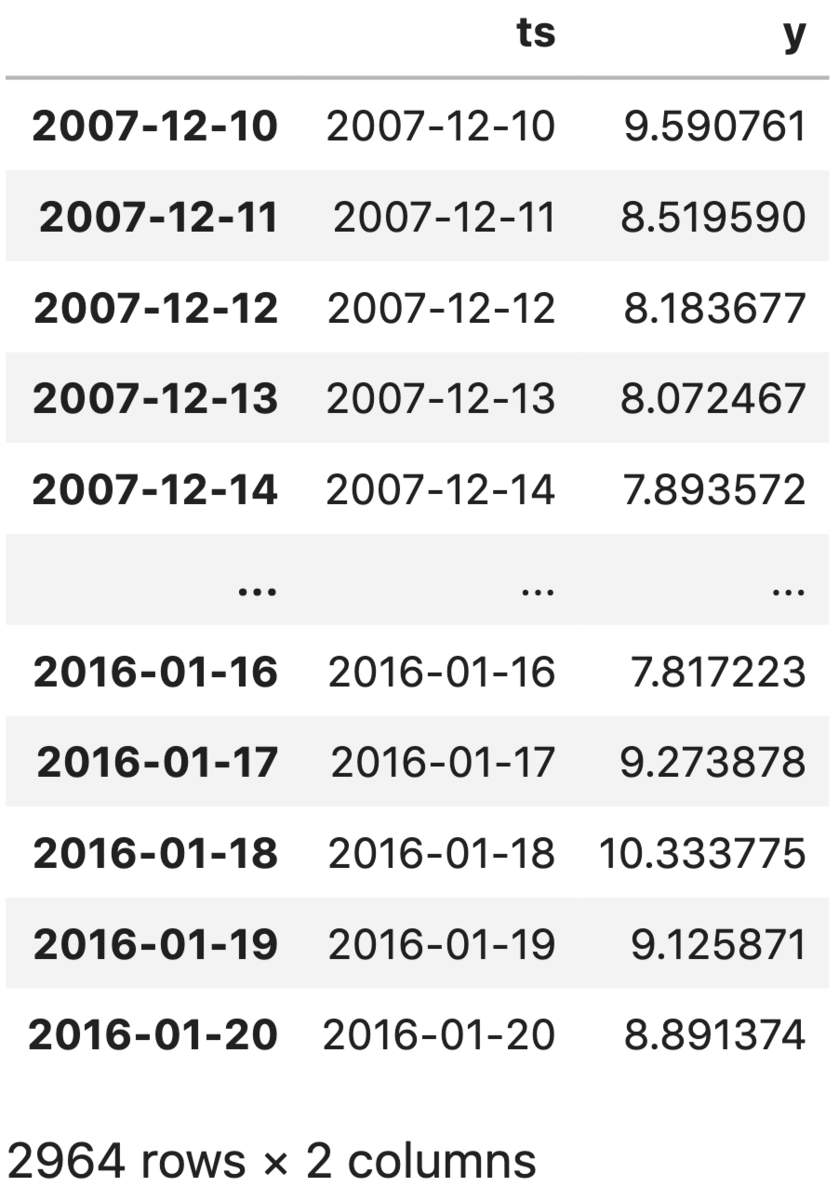
他にも、DataLoaderTS() を用いて、バーミンガム市内の駐車場稼働率やcapital bikeshareの1時間ごとのレンタルバイク台数などといったデータセットを利用することができます。
日付をdatetime型、予測したい数値をint型やfloat型で保持していれば良いです。
EDA
どういったデータか確認していきます。
まず、時間と実績値の統計量を確認します。
print(ts.describe_time_col()) print(ts.describe_value_col())

時間についても統計量を簡単に出してくれるの良いですね。
時間ごとの実績値について可視化してみます。
fig = ts.plot() plotly.io.show(fig)
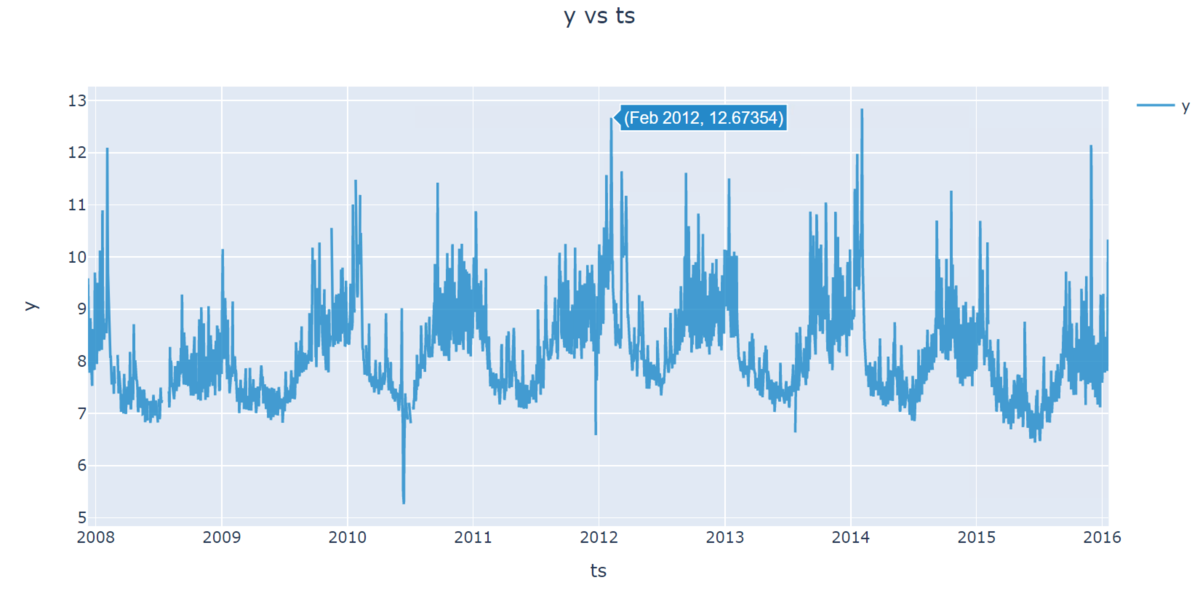
アメフトのシーズンは秋から冬頃のため、その時期で閲覧数が増えていることが確認できます。
また、可視化はPlotlyで行っているので、カーソルをグラフに近づけるとどの時点でどの値かを表示してくれます。モダンですね。
年ごとの傾向をより詳細に把握するために、日毎の実績値を年別に可視化してみましょう。
年毎の平均も併せて可視化してみます。
fig = ts.plot_quantiles_and_overlays(
groupby_time_feature="month_dom",
show_mean=True,
show_quantiles=False,
show_overlays=True,
overlay_label_time_feature="year",
overlay_style={"line": {"width": 1}, "opacity": 0.5},
center_values=True,
xlabel="day of year",
ylabel=ts.original_value_col,
title="yearly seasonality for each year (centered)"
)
plotly.io.show(fig)
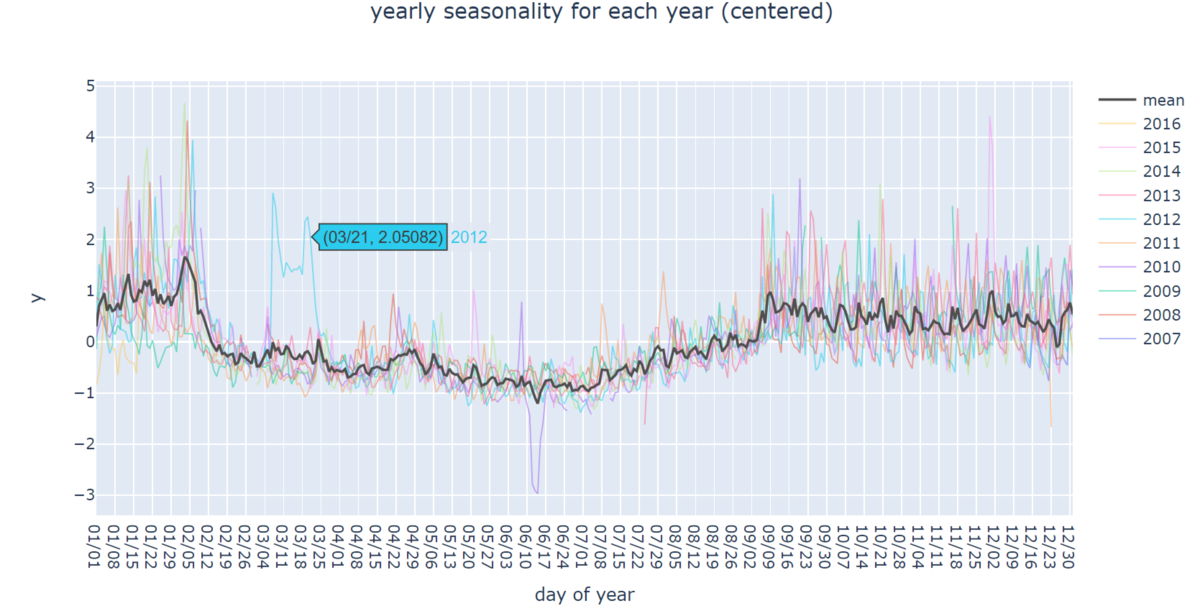
どの年でも、秋から冬頃は閲覧数が増えることが分かりました。
また、2012年の3月や2010年の6月は例年と比べ、値が異常となっていることも確認できました。
時系列のトレンドについても確認します。
model = ChangepointDetector()
res = model.find_trend_changepoints(
df=df, # data df
time_col="ts",
value_col="y",
yearly_seasonality_order=10,
regularization_strength=0.5,
resample_freq="7D",
potential_changepoint_n=25,
yearly_seasonality_change_freq="365D",
no_changepoint_distance_from_end="365D")
fig = model.plot(
observation=True,
trend_estimate=False,
trend_change=True,
yearly_seasonality_estimate=False,
adaptive_lasso_estimate=True,
plot=False)
plotly.io.show(fig)
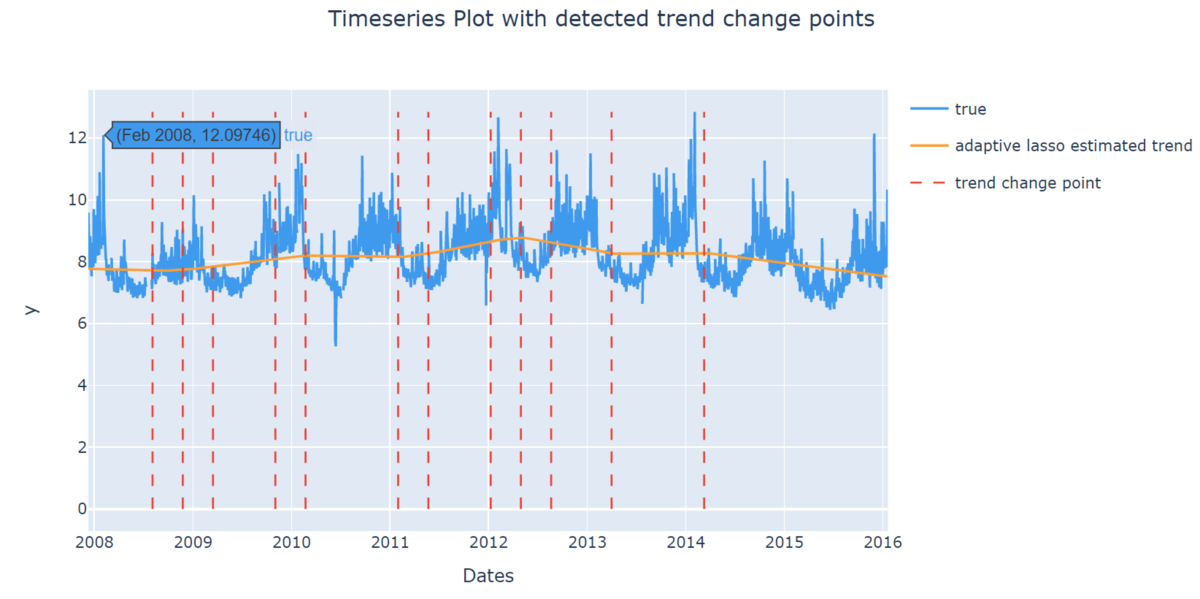
自動で検出されたトレンドの変化点を見ることができます。
これを見ると、2012年まで増加傾向で、そこから減少傾向になっていることが分かります。
この変化は、Peyton Manningさんの所属チームがこの前後で変わったことが要因の一つと考えられます。
シーズン内外かで曜日と相互作用がありそうなため、週毎の季節性を月別に確認してみます。
fig = ts.plot_quantiles_and_overlays(
groupby_time_feature="str_dow",
show_mean=True,
show_quantiles=False,
show_overlays=True,
center_values=True,
overlay_label_time_feature="month", overlays by month
overlay_style={"line": {"width": 1}, "opacity": 0.5},
xlabel="day of week",
ylabel=ts.original_value_col,
title="weekly seasonality by month",
)
plotly.io.show(fig)
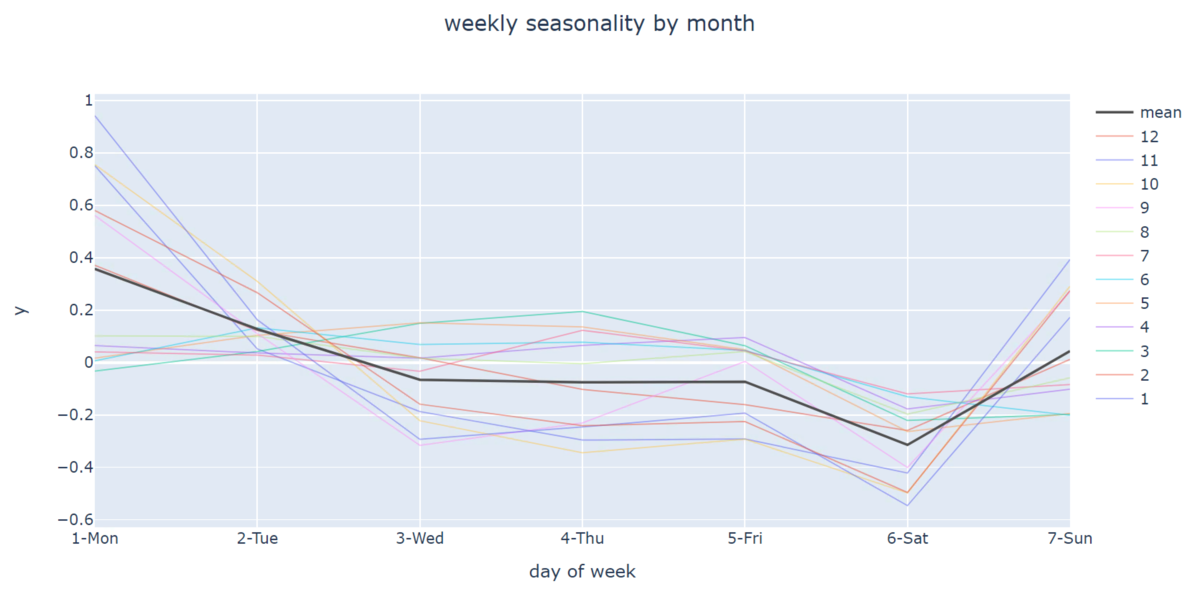
シーズンかどうかにより、週毎の傾向が分かれていることを確認できました。
※ログ集計結果は翌日に反映のため、1日ずれております。
今回実施した可視化は一部になります。
Greykiteには他にも豊富な可視化手段があり、詳しくはドキュメントをご確認ください。
モデル構成要素の作成
前項までのEDAからモデル構成要素を作成していきます。
構成要素としてどういうものを入れられるかは、主に以下の通りです。
| 要素 | 内容 |
|---|---|
| growth | 成長曲線(線形や二次関数など) |
| changepoints | トレンドの変化点 |
| seasonality | 季節性(年次、四半期、月次、週次、日次など) |
| events | 祝日や長期休暇等の短期的な事象 |
| autoregression | 過去の時系列観測値とその集計値 |
| regressors | 外部変数 |
| custom | その他自作の構成要素 |
まず、2012年まで増加傾向でそこから減少傾向になっている特徴を入れ込みます。
これにはトレンドの変化点をそのまま入れ込んであげます。
growth = {
"growth_term": "linear"
}
changepoints = {
"changepoints_dict": dict(
method="auto",
yearly_seasonality_order=10,
regularization_strength=0.5,
resample_freq="7D",
potential_changepoint_n=25,
yearly_seasonality_change_freq="365D",
no_changepoint_distance_from_end="365D"
)
}
季節性として、年次、週次での傾向があることを入れます。
yearly_seasonality_order = 10 weekly_seasonality_order = 5 seasonality = { "yearly_seasonality": yearly_seasonality_order, "quarterly_seasonality": False, "monthly_seasonality": False, "weekly_seasonality": weekly_seasonality_order, "daily_seasonality": False }
祝日やイベントの情報を入れます。
祝日は前後2日間、イベントにはアメフトの優勝決定戦であるスーパーボウルの日を指定します。
events = {
"holidays_to_model_separately": SilverkiteHoliday.ALL_HOLIDAYS_IN_COUNTRIES,
"holiday_lookup_countries": ["UnitedStates"],
"holiday_pre_num_days": 2,
"holiday_post_num_days": 2,
"daily_event_df_dict": {
"superbowl": pd.DataFrame({
"date": ["2008-02-03", "2009-02-01", "2010-02-07", "2011-02-06",
"2012-02-05", "2013-02-03", "2014-02-02", "2015-02-01", "2016-02-07"],
"event_name": ["event"] * 9
})
}
}
シーズン内外で傾向が違うため、シーズンかどうかの外部変数を入れます。
df_full = ts.make_future_dataframe(periods=365) df_features = build_time_features_df( dt=df_full["ts"], conti_year_origin=convert_date_to_continuous_time(df_full["ts"][0]) ) is_football_season = (df_features["woy"] <= 6) | (df_features["woy"] >= 36) df_full["is_football_season"] = is_football_season.astype(int).tolist() df_full.reset_index(drop=True, inplace=True) regressors = { "regressor_cols": ["is_football_season"] }
シーズン内外と曜日の相互作用も入れてあげます。
football_week = cols_interact(
static_col="is_football_season",
fs_name=SilverkiteSeasonalityEnum.WEEKLY_SEASONALITY.value.name,
fs_order=weekly_seasonality_order,
fs_seas_name=SilverkiteSeasonalityEnum.WEEKLY_SEASONALITY.value.seas_names
)
extra_pred_cols = football_week
上記で作成した全てを入れ込んで、モデルの構成要素を作成します。
metadata = MetadataParam(
time_col="ts",
value_col="y",
freq="D",
train_end_date=datetime.datetime(2016, 1, 20)
)
model_components = ModelComponentsParam(
seasonality=seasonality,
growth=growth,
events=events,
changepoints=changepoints,
autoregression=None,
regressors=regressors,
uncertainty={
"uncertainty_dict": "auto",
},
custom={
"fit_algorithm_dict": {
"fit_algorithm": "ridge",
},
"extra_pred_cols": extra_pred_cols
}
)
学習結果
実際に学習させて評価を見てみましょう。
forecaster = Forecaster()
result = forecaster.run_forecast_config(
df=df_full,
config=ForecastConfig(
model_template=ModelTemplateEnum.SILVERKITE.name,
forecast_horizon=365,
coverage=0.95,
metadata_param=metadata,
model_components_param=model_components
)
)
result.backtest.test_evaluation
実行させると様々な評価指標での結果が出てきますが、時系列でよく用いられるMAPE (平均絶対誤差率) のテストデータにおける精度を確認します。
小さいほど精度が良いのですが、今回は 4.55(%)とまずまずのものを獲得できておりました。
予測結果を可視化させてみると
fig = result.backtest.plot() plotly.io.show(fig)
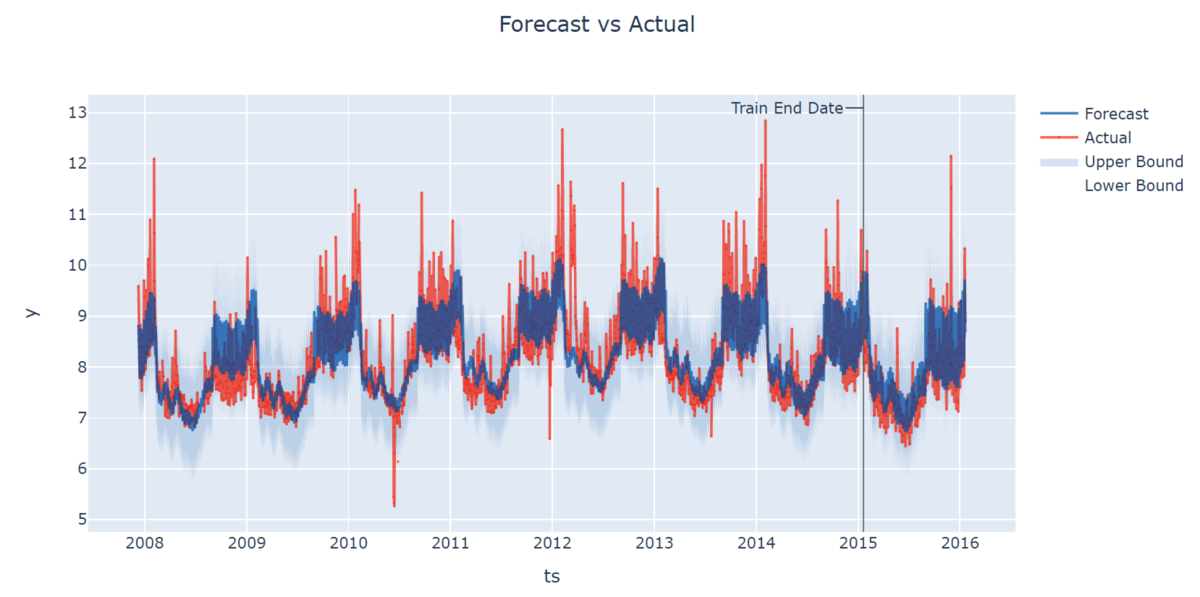
テストデータでもおおよその傾向を捉えられていることを確認できました。
以下のように、モデルサマリーとして回帰係数を出力して特徴量の影響度を参照できます。
今回はレイバー・デーやクリスマス、サンクスギビングデーの1、2日前といった祝日、アメフトのシーズン内外の効果がとても大きいものとなっておりました。(出力結果は長いので省略します。)
summary = result.model[-1].summary()
summary
また、今回ハイパラチューニングを実施していませんが、グリッドサーチによるハイパラチューニングを実施できる機能もあります。
Prophetでは、Optunaと組み合わせたハイパラチューニングの記事を、2020年のアドベントカレンダーにおいて島田さんが執筆しておりますので、良ければこちらもご覧ください。
Silverkiteと他時系列手法の比較
「他時系列手法と精度や実行時間はどのくらい違うのか?」
ということを簡単に検証できる BenchmarkForecastConfig がGreykiteには用意されています。
Silverkite vs Prophet
SilverkiteとProphetの違いは、Greykiteのドキュメントに表でまとめられております。
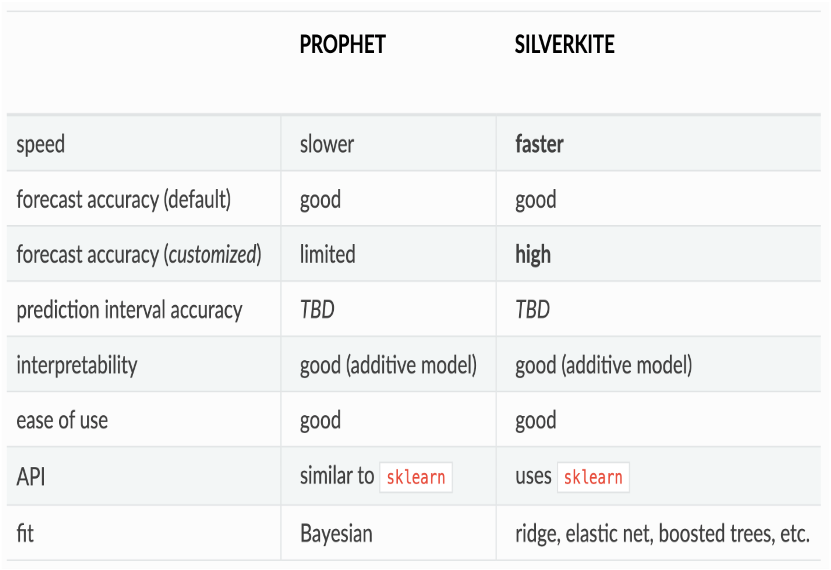
主な違いは学習時間、カスタムした際の精度、モデリング手法といったところでしょうか。
学習
Greykiteで用意されたテンプレートを利用し、各手法の結果の違いを見てみます。
今回は、Silverkite、Prophet、Autoarimaの3種類で試してみます。
まずデータセットを用意します。今回は先ほどまでと同じ、Daily Peyton Manning datasetを利用します。
dl = DataLoaderTS() ts = dl.load_peyton_manning_ts() df = ts.df
次に、共通のコンポーネントを定義します。
metadata = MetadataParam(
time_col="ts",
value_col="y",
freq="D"
)
forecast_horizon = 7
coverage = 0.95
evaluation_metric = EvaluationMetricParam(
cv_selection_metric=EvaluationMetricEnum.MeanAbsolutePercentError.name,
cv_report_metrics=None
)
evaluation_period = EvaluationPeriodParam(
cv_max_splits=1,
periods_between_train_test=0
)
computation = ComputationParam(
hyperparameter_budget=None,
n_jobs=-1,
verbose=3
)
common_config = ForecastConfig(
metadata_param=metadata,
forecast_horizon=forecast_horizon,
coverage=coverage,
evaluation_metric_param=evaluation_metric,
evaluation_period_param=evaluation_period,
computation_param=computation
)
次に各モデル個々の設定を行います。
# Prophet model_components = ModelComponentsParam( seasonality={ "seasonality_mode": ["additive"], "yearly_seasonality": ["auto"], "weekly_seasonality": [True], }, growth={ "growth_term": ["linear"] } ) param_update = dict( model_template="PROPHET", model_components_param=model_components ) Prophet = replace(common_config, **param_update) # Silverkite model_components = ModelComponentsParam( changepoints={ "changepoints_dict": { "method": "auto", } }, autoregression={ "autoreg_dict": "auto" } ) param_update = dict( model_template="SILVERKITE", model_components_param=model_components ) Silverkite = replace(common_config, **param_update) # Autoarima model_components = ModelComponentsParam( seasonality={ "seasonality_mode": ["additive"], "yearly_seasonality": ["auto"], "weekly_seasonality": [True], }, growth={ "growth_term": ["linear"] } ) param_update = dict( model_template="AUTO_ARIMA", model_components_param=model_components ) Autoarima = replace(common_config, **param_update) configs = { "Prophet": Prophet, "Silverkite": Silverkite, "Autoarima": Autoarima }
ここまででモデルの定義を終えたので、学習させていきます。
tscv = RollingTimeSeriesSplit(
forecast_horizon=forecast_horizon,
min_train_periods=2 * 365,
expanding_window=True,
use_most_recent_splits=True,
periods_between_splits=5,
periods_between_train_test=0,
max_splits=4)
for split_num, (train, test) in enumerate(tscv.split(X=df)):
print(split_num, train, test)
bm = BenchmarkForecastConfig(df=df, configs=configs, tscv=tscv)
bm.run()
結果
学習が終わったので、結果を確認していきます。
まず、テストデータにおけるMAPEを出します。
metric_dict = {
"MAPE": EvaluationMetricEnum.MeanAbsolutePercentError,
}
evaluation_metrics_df = bm.get_evaluation_metrics(metric_dict=metric_dict)
error_df = evaluation_metrics_df.drop(columns=["split_num"]).groupby("config_name").mean()
error_df
次に、モデルの実行時間を出します。
runtime_df = bm.get_runtimes() runtimes_df = runtime_df.drop(columns=["split_num"]).groupby("config_name").mean() runtimes_df
結果をまとめると、以下のようになりました。
| 手法 | 精度 | 実行時間 |
|---|---|---|
| Sivlerkite | 4.56(%) | 22(s) |
| Prophet | 5.03(%) | 17(s) |
| Autoarima | 5.12(%) | 33(s) |
Silverkiteの精度が最も良いですね。
ただ、Silverkiteは速度がウリでしたが、今回の実験ではProphetの方が速かったようです。
他にも単独モデルでの学習と同じく、モデルサマリーや各予測結果の詳細な可視化などを実施することができます。
どの手法が解きたいタスクに適しているかを簡単に試せそうで、いい機能だと感じています。
まとめ
本記事ではPythonで将来の時系列予測を行うことができる、Greykiteを紹介いたしました。
可視化や手法ごとの比較に優れていそうということで、他のデータセットに対しても試してみようと思います。
ぜひ皆様もお試しください!
それでは、良いクリスマスを🎅