
TL;DR
- 機械学習基盤をKubernates上で構成することで、機械学習にかかわる一連の処理の再現性を担保できるようになった。
- AutoML製品(DataRobot)の機能をKubernates(以下k8s)上で実行させることで、バッチ予測を並行実行し、大幅に高速化することができた。
- データサイエンティストが自分自身で容易に機械学習パイプラインの定義・デプロイができるようになった。
自己紹介・モチベーション
NTTドコモ データプラットフォーム部(以下DP部)藤平です。
NTTドコモでは様々なサービスで機械学習を取り入れることでサービス価値の向上を目指しています。 データプラットフォーム部(以下DP部)ではこうした機械学習の適用を含め、全社におけるデータ活用をミッションしており、 毎月5000万件以上のユーザーデータ対して、数十個の機械学習モデルによる機械学習の予測処理を行っています。
機械学習の運用に当たっては、実行の再現性の担保・迅速なデプロイ・スケーラビリティが求められますが、 DP部では、AutoML製品(DataRobot)・Kubernates・Apache Airflow等を最大限に活用することで 3名でも安定して上記の機械学習の処理を運用できるCloudNativeな機械学習基盤に進化させてきました。
本記事では具体的にどのようなアーキテクチャを採用することでこれを実現しているかを紹介します。
なお、本記事の掲載の取り組みについてはNTTデータの支援メンバーである辰己さん・兼子さんの2名に
詳細検討・実装を進めてもらっており、以下についてはお二人に執筆いただいています。
処理の再現性の担保・デプロイの迅速化
writer:NTTデータ モバイルビジネス事業部 辰己 勝俊
まず、機械学習モデルの動かす基盤全体で 処理の再現性を担保・デプロイの迅速化をできる環境にするために、 以下を実現させることを目指しました。
実現したかったこと
- コードの再現性を担保する(以前作ったコードを必ず再実行できるようにする)
- データサイエンティスト自身が簡単に機械学習タスクの実行パイプラインを書けるにすることで、デプロイまでの時間を短縮する
- ノートブックファイルを、そのままの形でパイプラインに組み込めるようにすることで、データサイエンティスとのデプロイまでの手順を減らす
1. コードの再現性を担保する
機械学習のワークロードでは、前処理・モデル学習・予測に至るまで処理の再現性を担保できることが求められます。再現性を担保できない場合、以前に学習したモデルと、新しく作ったモデルを比較することができない、同等のデータを準備できないために、本当に精度向上できたのかどうかわからないといった問題が発生するためです。
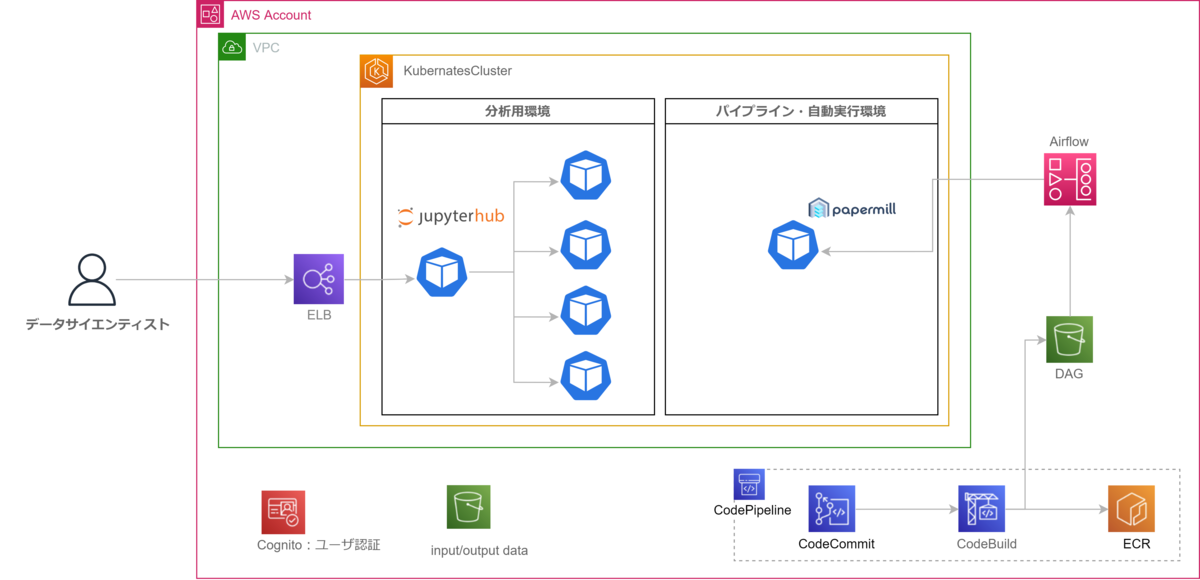
DP部ではこの問題に対応するため、分析環境をk8s上にJupyterHubというマルチユーザjupyter環境を構成するOSSを導入しています。JupyterHubをk8s上で使うことで、jupyter環境をコンテナベースで提供することができ、Pythonバージョン・ライブラリの意図せぬ構成変更により、昨日書いたコードが動かないといったトラブル(※)を防いでいます。
※AWS SageMaker Notebook Instancesのように自動でクラウドベンダ側が環境をupdateしてくれるサービスを利用している際、注意が必要になります。

引用元・参考:
- 画像引用元:https://jupyterhub.readthedocs.io/en/stable/
- Jupyterhub Z2JH:https://z2jh.jupyter.org/en/stable/
2. 簡単に機械学習タスクの実行パイプラインをかけるようにする
機械学習モデルの運用に当たっては、機械学習モデルにデータを投入する前の前処理、モデル学習、予測という複数のタスクを順番に実行していく必要があります。かつ、前述の通り、運用しているモデル数が非常に多岐にわたるため、機械学習エンジニア側でパイプラインを都度すべて書いていくのは現実的ではありませんでした。
そこでDP部では、シンプルにデータサイエンティスト自身が、自分が作ったノートブックの実行順序を指定すれば簡単に自動実行できるパイプラインを作っています。具体的には、Apache AirflowというPythonベースでタスクの依存関係を記述できるツールを使うことで、データサイエンティスト自身で機械学習のパイプラインを定義することを実現しています。
Airfowは非常に柔軟にタスクの依存関係を定義できる一方、データサイエンティストがゼロベースでタスクを記述していくのはハードルが高いため、最低限必要なパラメーターをデータサイエンティストが記載すれば簡単に自動実行できるテンプレートファイルを用意することで、データサイエンティストによっての利用ハードルを下げています。
<DAGサンプルコード>
######################################################################### #user_config:利用者側で変更するパラメータ。 ######################################################################### #DAG params DAG_NAME = "template_dag" #DAG名称 RETRIES = 0 #リトライ回数 TAGS = ["template","dev"] #商用には prod を入れてください。あとはプロジェクト名等 OWNER = "xxxx.xxx.xx" #DAGの作成者 SLACK_NOTIFICATION_CHANNEL = "slack-channl-name" #実行失敗時の通知Slackチャネル名称。 SLACK_NOTIFICATION_RECEIVER = ["<@XXXXXX>"] #メンションしたいslack user id SCHEDULE_INTERVAL = None #cron式で記入。 START_DATE = datetime(2021, 11, 25) #UTCベース #Spec param DOCKER_IMAGE_TAG = 'xxxxxxxxx' #jupyterhub上で動作確認したときのdocker imageタグ INSTANCE_TYPE = 'r6i-2xlarge' #実行させるインスタンスタイプ #Excution params CODECOMMIT_REPO_NAME = "Notebook-Repo" #Notebookを保存したCodeCommitレポジトリ名称 EXECUTE_FILE_BASE_PATH = "Project-XXX" #Codecommit内のパス EXECUTE_NOTEBOOK_FILE_NAME = "model_train" #実行対象ノートブック名。 OUTPUT_BUCKET = "Output-Bucket-Name" #実行完了したノートブックの出力先バケット OUTPUT_BUCKET_BASE_PATH = "project-XXX" #出力先バケット内のパス
引用元・参考:
- ApacheAirflow:https://airflow.apache.org/
- KubernetesPodOperator:https://airflow.apache.org/docs/apache-airflow-providers-cncf-kubernetes/stable/operators.html
3. ノートブックファイルを、そのままの形でパイプラインに組み込めるようにする
1点目のノートブックファイル(ipynbファイル)をそのまま実行できるようにするために、Netflixで作られたOSSであるPapermillを利用しています。一般的にはデータサイエンティストが作成したノートブックから商用実装する際には、pyファイルへの変換やリファクタリングをするのが一般的ですが、DP部管理のモデル数は非常に多く、都度リファクタリングしての運用は現実的ではなかったため、ノートブックをそのまま実行パイプラインの一部として利用できるようにしました。

上図のように、Papermillを実装したコンテナ上でノートブックに任意のパラメーターを渡して実行が可能です。
引用元・参考:
- 画像引用元:https://netflixtechblog.com/scheduling-notebooks-348e6c14cfd6
- Papermill:https://papermill.readthedocs.io/en/latest/
スケーラビリティの確保
writer:NTTデータ D&I事業部 兼子 菜緒見
上述のアーキテクチャ構成によって、データサイエンティストが簡単に機械学習モデルをパイプライン化・自動運用化することができるようになりました。 一方で、この基盤上で扱う機械学習モデルが増えてくるにつれて、モデルを使った予測処理の部分についても動的にスケールアウトできる構成にすることが求められてきました。
その解決として、MLモデルの構築に利⽤していたDataRobotのAutoML機能と上述の機械学習パイプラインを組み合わせる構成をとることで、予測のスケール化を図りました。
DataRobotについて
DP部では、機械学習モデルを迅速に作成するため、DataRobotのAutoML機能を活用しています。DataRobotはKaggleのGrandMasterが監修に携わり、特徴量エンジニアリングや複数のモデル比較・ハイパーパラメーターチューニングなど、機械学習モデルを効率的、かつモデルの頑健性を担保した形で学習・生成してくれる製品です。

スコアリングコード機能
DataRobotでは、生成した機械学習モデルをjarファイルに変換してDataRobotのプラットフォーム外でも予測できるスコアリングコードという機能が近年新たに利用できるようになりました。こちらの機能を先述の基盤上で動かすことで、予測処理の実行時だけ数十台の仮想サーバを動的にデプロイし、それぞれのサーバ上で予測処理実行用のコンテナを実行させることで、5千万レコードレベルの予測処理を大幅に短縮することが可能になりました。

引用元・参考:
- DataRobot: https://www.datarobot.com/jp/
- ScoringCode:https://docs.datarobot.com/ja/docs/predictions/scoring-code/index.html
実装上のポイント
本構成をとるにあたっては、様々な工夫や実装上はまったポイントがありました。 各ポイントについて詳細を記載すると冗長になってしまうため、ここでは簡単にポイントだけご紹介させていただきます。
工夫点
- 各ワーカーpodはマルチスレッド処理をさせることで、予測に利用するpodのリソースを最大限に利用した。
- AirflowのDAGは、モデル毎にtask groupを動的につくること構成にすることで同一データソースで複数モデルを運用する場合、モデル数が増えてもDAGをほぼ書き換えることなくを使いまわせるようにしている。
- 商用適用はまだできていないが、DataRobot側に予測に利用したデータを送付することで、データドリフトやコンセプトドリフトを検知できるようにし、MLOpsで必要な機械学習としてのモニタリングも可能な構成にした。
はまったポイント
- モデルで利用するカラム数が多く、1レコードの容量が大きいと、メモリあふれになってしまうことがしばしばあった。
利用するデータは予めパーティショニングしたうえでS3に保存しておき、かつ、
一度で読み込めるデータ量を任意のレコード数に調整可能にしておくことで、メモリあふれを回避した。 - Airflowについては、AWSのマネージドサービス(MWAA)を利用しているが同時実行可能なタスクインスタンスを増やそうとして、 celory_autoscaleを無暗に推奨値以上にすると、スケジューラーがハングしやすいため、推奨値のまま利用したほうが良かった。
- ManagedSparkの利用も検討したが、クラスター起動までのオーバーヘッド時間が想定的に長くかかるため、今回は非採用とした。
所感
Airflowは2.0系になってからより柔軟なDAG設計を記述することが可能になり、今回はそのおかげでタスクの依存関係の記述もしやすく、非常に便利だなと感じました。今回検討したアーキテクチャによってバッチ予測を並列実行することは可能になりましたが、相対的にデータロードの部分が時間がかかっている点など、さらなる効率化にむけて挑戦していきたいと考えています。
あとがき
DP部では本記事でご紹介したような機械学習パイプライン(MLOpsパイプライン)を利用していますが、アーキテクチャに関してこれが必ず正解というものはなく、各ユースケースにおいて最も適している構成をとれることが大事だと考えています。
あるアーキテクチャを採用することは、常に何らかのトレードオフを選択することになります。 我々のアーキテクチャでは、データサイエンティストが容易に利用できること重視しているため、 例えばKubeflowPipelineなど、より厳密な形で機械学習のアーティファクトの依存関係まで定義できる製品もありますが、 そこまでの厳密な依存関係の制御はAirflowではできないため、敢えて諦めている部分でもあります。
いずれの技術も日進月歩の変化があり、従来できなかったことができるようになる、 また、それに伴って最適なアーキテクチャ構成は動的に変化していくため、 常に利用可能な様々な技術の動向を追いながら、自分自身もアーキテクチャも進化させ続けていきたいと考えています。
引用元・参考:
- KubeflowPipeline:https://www.kubeflow.org/docs/components/pipelines/v2/