
TL;DR
- RAGアプリを運用するにあたってLLMOpsの考え方が重要になり、Azure OpenAI ServiceのPrompt Flowの活用を開始した。
- RAGアプリの精度を担保するため、Prompt Flowに搭載されている評価Flowの性能を検証した。
- 回答内容の正確性の評価性能を上げるため、評価Flowを自作した。
自己紹介
NTTドコモ データプラットフォーム部(以下DP部)藤平です。 NTTドコモでは様々なサービスで機械学習を取り入れることでサービス価値の向上を目指しています。 データプラットフォーム部(以下DP部)ではこうした機械学習の適用を含め、全社におけるデータ活用をミッションとしています。 今年はIT領域に留まらず世界中の多くの人々に注目されることとなったAI領域のブレイクスルー、「ChatGPT」が登場した年で、これを発端として生成系AIが大いに盛り上がりました。 DP部でも早速活用すべくAzure OpenAI Serviceを導入し、ビジネス利用の検討を開始しました。
今回執筆いただいた協働者の鶴薗さんとは、DP部が展開する社内の分析サービスに関するドキュメントやソースコードをリソースとしたRAG(Retrieval Augmented Generation)の詳細検討・実装・運用を一緒に取り組んでおり、現在SlackBot化して日々改良を続けながら運用しています。
本記事ではRAGアプリ開発のスマートな運用を目指して試行錯誤していただいたもののうち、我々の取り組みの全貌が見渡せるような記事に出来たらと考え、RAGアプリの評価について紹介していただきます。
モチベーション
writer : DP部 鶴薗 智博
今年はLLMの登場により世界に激震が走る年となりましたが、弊社でもその活用が急ピッチで進んでおります。 その中で我々は社内の分析サービスについての質問がSlackチャンネルに殺到している現状を解決すべくRAGアプリを作成しました。
RAGとは?

BingChatの回答が分かりやすいですが、LLMの知識を利用しつつLLMが知らない知識を補強する手法で、幅広いユースケースに対応できるのが強みです。
RAGの概要
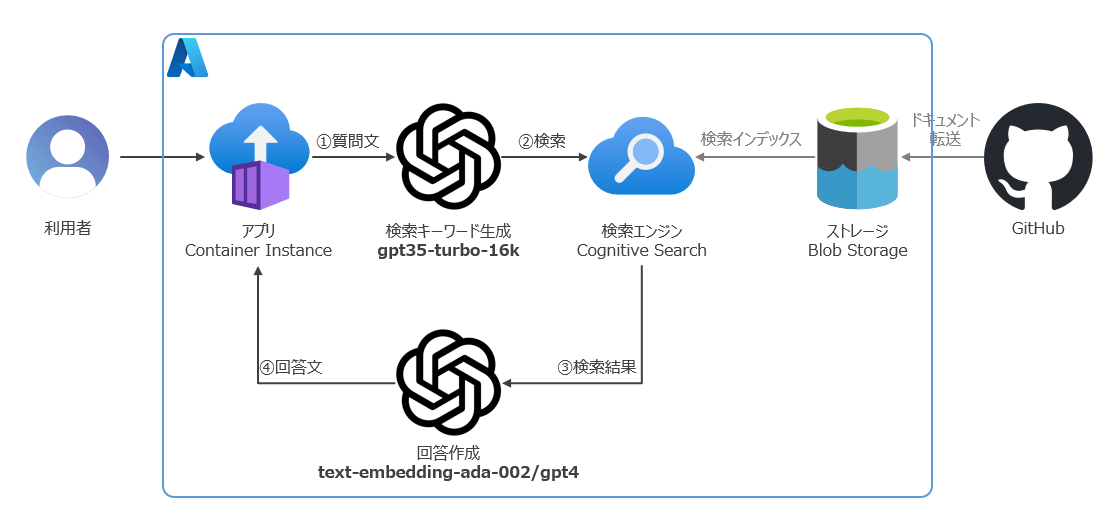
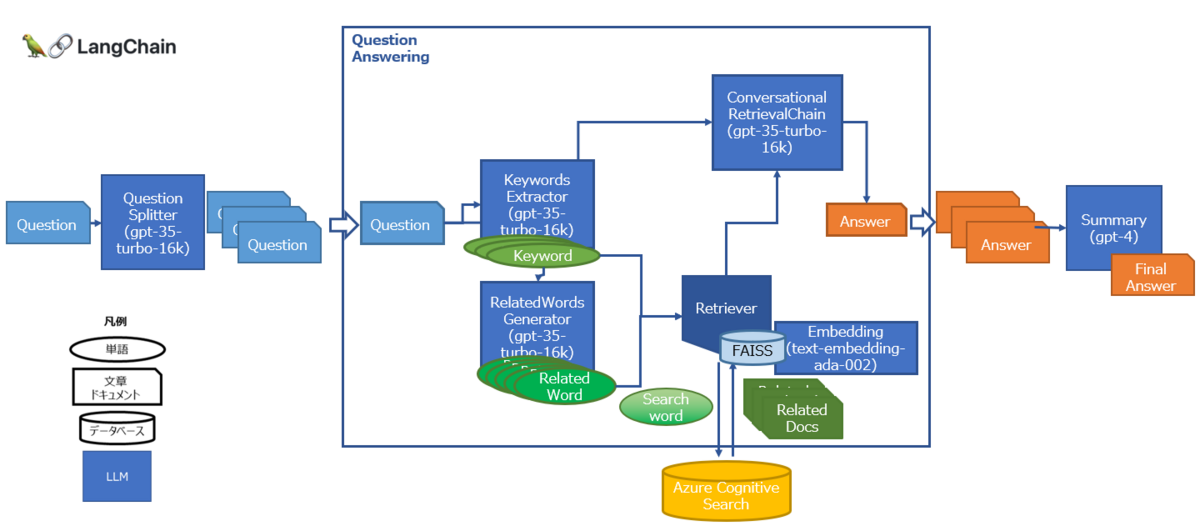
Prompt Flowとは?
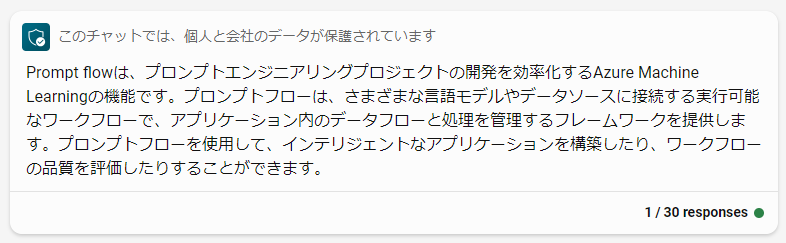
こちもBingChatの回答を引用します。Prompt FlowとはLLMアプリケーションの評価、デプロイを行う機能で、LLMアプリケーションのイケてる運用が可能になるよ、というものです。
今回はPrompt Flowの評価機能(以下、評価Flow)について試してみたのでまとめてみました。
Prompt Flow Built-Inの評価Flow
Prompt FlowのBuilt-Inの評価Flowについて、とても分かりやすくまとまっている記事があるため紹介しておきます。
Azure Machine Learning の Prompt flow の評価メトリクス紹介 ― ChatGPT どう評価する? #Azure - Qiita
上記アーキテクチャーの関係でContextが不要な評価Flowを一通り試してみました。 以下所感です。
| 評価方法 | 概要 | 強み | 弱み |
|---|---|---|---|
| QnA Ada Similarity Evaluation | 回答内容と模範回答をEmbeddingしてコサイン類似度を算出する | 回答内容と模範回答の文章としての類似度を定量的に評価することができる | 同じような内容だが主張の方向が真逆の場合でもスコアが高く出てしまう |
| QnA GPT Similarity Evaluation | 回答内容と模範回答の類似度をLLMが5段階で評価する | 意味的な類似度を評価することができる | 評価があいまいで安定せず、真逆の回答をしているのにスコアが高くなってしまうことも多い |
| QnA Fluency Evaluation | 回答内容の流暢さをLLMが5段階で評価する | ツギハギの回答を作成した場合に文章の自然さを評価することができる | 1つのLLMに最終回答を出力させていれば基本的にハイスコアが出るため、必要性が薄い |
| QnA Coherence Evaluation | 回答内容の首尾一貫性をLLMが5段階で評価する | Contextが大量に存在する場合に発生しうる首尾一貫性の欠落を検知できる | 1つのLLMに最終回答を出力させていれば基本的にハイスコアが出るため、必要性が薄い |
今回はこの中から「回答内容の正確性」を評価する上で、重要だがスコアが安定していないQnA GPT Similarity Evaluationに改良を加えてみました。
正確性の評価
背景
RAGに最も問われる性能は「回答内容の正確性」であると考えています。 理由はQABotであるのにAnswerが信頼されなければただのおもちゃになるだけだからです。
ただしその「回答内容の正確性」を評価する方法が難しく、LLMを用いて評価ができないか自作して試していましたが、なかなかスコアが安定せず頓挫していました。 (当時はLangchainで、Questionから評価観点を作成 → それぞれの観点に基づいて評価・採点 → 集計、というパイプラインを組んでいましたが、LLMが思うように動作せず苦労していました。)
そんな中Prompt Flow機能がリリースされました。 しかし、上記のようにBuilt-Inの様々な評価Flowを試してみましたが、結局「回答内容の正確性」の評価は難しそうでした。
- 「QnA Ada Similarity Evaluation」のようにベクトル演算による類似度では、回答内容に盛り込まれているトピックや文章構造が似ているかを評価することができているが、「回答内容の正確性」は評価できていない。
- 「QnA GPT Similarity Evaluation」のようにLLMを用いて「回答内容の正確性」を評価するしかなさそうだがスコアが安定しない。
そこで「QnA GPT Similarity Evaluation」を改良して「回答内容の正確性」を評価できるようにし、複数の評価Flowを組み合わせることでRAGの総合的な精度評価をしていくことを目指しました。
使用するテストケース
同じような内容で主張の方向性が異なるケースのスコアが分離できれば良いため、以下のように模範回答を用いたオリジナルのテストケースと、模範回答に否定語を混ぜた偽回答を用いたフェイクのテストケースを作成しました。 今回は公開用に以下3ケースを作成しました。
| # | 質問 | 回答 | |
|---|---|---|---|
| 1 | アインシュタインが提唱した相対性理論とは何ですか? | 模範解答 | 相対性理論は、アルベルト・アインシュタインによって提唱された物理理論で、特殊相対性理論と一般相対性理論からなります。特殊相対性理論は、物理法則がすべての慣性系で同一であるという原理と、光速がすべての慣性系で一定であるという原理に基づいています。一般相対性理論は、重力を幾何学的に解釈する理論で、物体は四次元時空を通過する最短経路(測地線)を進むという考え方に基づいています。 |
| 偽解答 | 相対性理論は、アルベルト・アインシュタインによって提唱された物理理論 ではなく、特殊相対性理論と一般相対性理論からはなりません。特殊相対性理論は、物理法則がすべての慣性系で同一であるという原理と、光速がすべての慣性系で一定であるという原理に基づいています。一般相対性理論は、重力を幾何学的に解釈する理論で、物体は四次元時空を通過する最短経路(測地線)を進むという考え方に基づいています。 | ||
| 2 | フェルマーの最終定理とは何ですか? | 模範解答 | フェルマーの最終定理は、17世紀の数学者ピエール・ド・フェルマーが提唱した定理で、nが2より大きい自然数である場合、x^n + y^n = z^n という方程式が自然数の解を持たないというものです。 |
| 偽解答 | フェルマーの最終定理は、17世紀の数学者ピエール・ド・フェルマーが提唱した定理で、nが2より大きい自然数である場合、x^n + y^n = z^n という方程式が自然数の解を持つ というものです。 | ||
| 3 | アメリカンフットボールの醍醐味を教えてください | 模範解答 | アメリカンフットボールの醍醐味は以下の点に集約されると考えられます: 1. 戦略性:アメリカンフットボールは、「移動するチェス」とも形容されるほどの高い戦略性を持つスポーツです。各プレイは短い時間で行われ、その都度チームは新たなプレイを選択します。これには、攻撃パターンの選択、防御形態の選択、特定の選手へのパスなどが含まれます。 2. チームワーク:アメリカンフットボールは、各ポジションが密接に連携してプレイを進める必要があります。攻撃側では、クォーターバック(QB)が他の選手と連携し、パスやランを成功させるためにオフェンシブラインが守ります。一方、ディフェンス側では、各選手が相手の攻撃を阻止するために連携します。 3. 物理性:アメリカンフットボールは非常にフィジカルなスポーツで、選手たちは身体をぶつけ合い、相手を押しのけてボールを進めたり、防御したりします。この身体的な接触は、ゲームのエキサイティングさを一層高めています。 4. スペクタクル:アメリカンフットボールは、スーパーボウルなどの大規模なイベントでは、ハーフタイムショーを含むエンターテイメント性が高いスポーツです。また、一つ一つのプレイがポイントに直結するため、試合の終始にわたりスリルと緊張感があります。 |
| 偽解答 | アメリカンフットボールの醍醐味は以下の点に集約されると考えられます: 1. 戦略性:アメリカンフットボールは、「移動するチェス」とは形容されない戦略性の低いスポーツです。各プレイは短い時間で行われ、その都度チームは新たなプレイを選択します。これには、攻撃パターンの選択、防御形態の選択、特定の選手へのパスなどが含まれます。2. チームワーク:アメリカンフットボールは、各ポジションが密接に連携してプレイを進める必要はありません。攻撃側では、クォーターバック(QB)が他の選手と連携し、パスやランを成功させるためにオフェンシブラインが守ります。一方、ディフェンス側では、各選手が相手の攻撃を阻止するために連携します。3. 物理性:アメリカンフットボールは非常にフィジカルなスポーツで、選手たちは身体をぶつけ合い、相手を押しのけてボールを進めたり、防御したりします。この身体的な接触は、ゲームのエキサイティングさを損なわせています。4. スペクタクル:アメリカンフットボールは、スーパーボウルなどの大規模なイベントでは、ハーフタイムショーを含むエンターテイメント性がまだまだ乏しいスポーツです。また、一つ一つのプレイがポイントに直結 しにくいため、試合の終始にわたりスリルと緊張感はありません。 | ||
自作の評価Flow
オリジナルケースとフェイクケースのスコア差ができるだけ大きくなるような評価Flowを自作しました。 以下がBuilt-In評価Flow「QnA GPT Similarity Evaluation」のPromptの評価基準部分となっています。(2023/11/13時点)
Equivalence, as a metric, measures the similarity between the predicted answer and the correct answer. If the information and content in the predicted answer is similar or equivalent to the correct answer, then the value of the Equivalence metric should be high, else it should be low. Given the question, correct answer, and predicted answer, determine the value of Equivalence metric using the following rating scale: One star: the predicted answer is not at all similar to the correct answer Two stars: the predicted answer is mostly not similar to the correct answer Three stars: the predicted answer is somewhat similar to the correct answer Four stars: the predicted answer is mostly similar to the correct answer Five stars: the predicted answer is completely similar to the correct answer
これに対し、模範回答の内容との意味的な矛盾がある場合はスコアが低くなるような厳しい評価基準の評価Flowを作成しました。 以下が今回自作のPromptです。
User:
You are a QA Bot performance evaluator.
Please output the semantic similarity between the answers given by the QA Bot and the model answers on a 5-point scale.
The output should be numerical only.
The evaluation criteria are as follows
5 : Bot's answer is almost identical to the model answer, with no inconsistencies in content and no omissions of explanation.
4 : Bot's answer is almost identical to the model answer, with no inconsistencies in content and some omissions in explanation.
3 : Bot's answer is almost identical to the model answer, with no inconsistencies in content, but with many omissions in explanation.
2 : Bot's answer is partially inconsistent with the model answer.
1 : Bot's answer is generally inconsistent with the model answer.
Bot's answer----------------------------------------------
{{prediction}}
----------------------------------------------------------
Model answer----------------------------------------------
{{groundtruth}}
----------------------------------------------------------
output :
評価Flow作成手順
- Prompt flow → Create → Create by type - Evaluation flow を clone → すでに存在するPython Nodeを削除 → LLM Nodeを作成
- 上記のPromptをコピー&ペースト(Connection, API, deployment_nameを指定)
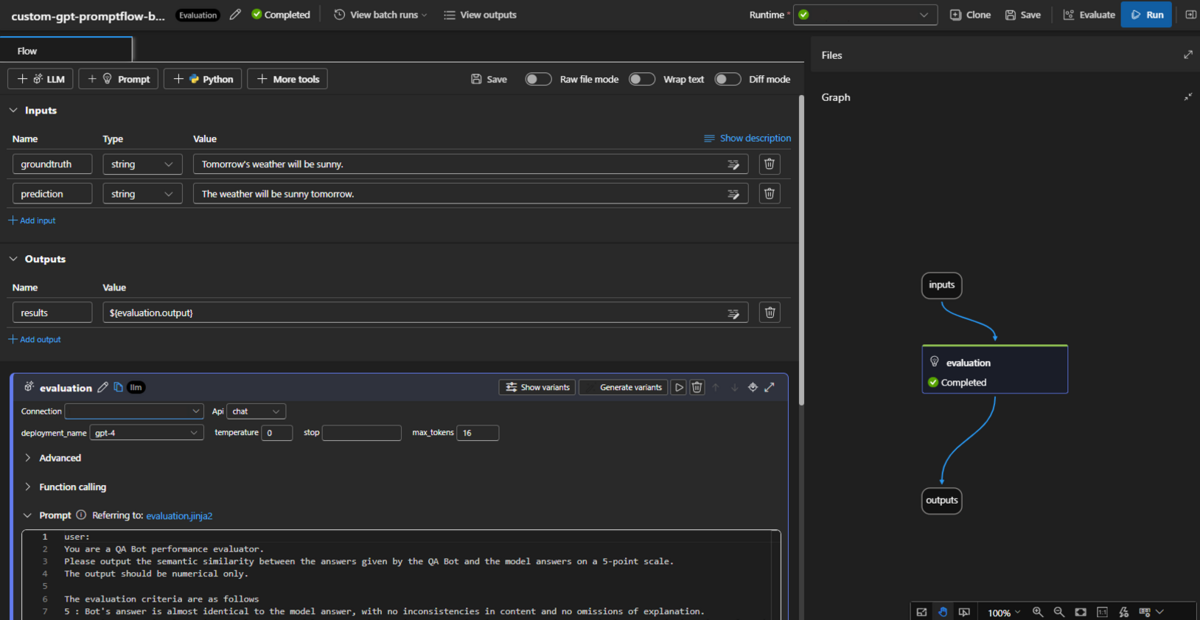
- Validate and parse input を押下
- 変数に入れる値をinputsから指定

この評価FlowをモデルのFlowのEvaluate時に指定することで実行することができます。
結果比較
Built-Inの評価Flowと自作評価Flowを上記2つのテストケースで実行した結果を下表のように比較しました。評価はPromptの通り5段階(5が最も正解に近い)でおこなっています。
以下の点から自作評価Flowの方が「回答内容の正確性」の評価が出来ていると言えるでしょう。 - Built-Inの評価Flowはオリジナルケースもフェイクケースもほぼ同じようなスコアが出ている - これに対し自作評価Flowはフェイクケースを低く評価できている
| # | Built-Inの評価Flow | 自作の評価Flow | ||
|---|---|---|---|---|
| オリジナルケース | フェイクケース | オリジナルケース | フェイクケース | |
| 1 | 4 | 5 | 4 | 1 |
| 2 | 4 | 4 | 4 | 2 |
| 3 | 4 | 2 | 5 | 2 |
| 合計 | 12 | 11 | 13 | 5 |
以下は参考として実際に業務で使用しているテストケースでの比較結果を掲載しておきます。 スコア差の合計が自作評価Flowの方が大きく、スコア差の分布も全体的に値が大きいところに集まっていることが分かります。
| # | Built-Inの評価Flow | 自作の評価Flow | ||||
|---|---|---|---|---|---|---|
| オリジナルケース | フェイクケース | 差分 | オリジナルケース | フェイクケース | 差分 | |
| 1 | 4 | 2 | 2 | 4 | 2 | 2 |
| 2 | 2 | 2 | 0 | 4 | 2 | 2 |
| 3 | 4 | 1 | 3 | 4 | 1 | 3 |
| 4 | 4 | 4 | 0 | 4 | 2 | 2 |
| 5 | 2 | 2 | 0 | 3 | 1 | 2 |
| 6 | 3 | 2 | 1 | 3 | 2 | 1 |
| 7 | 4 | 2 | 2 | 4 | 2 | 2 |
| 8 | 2 | 1 | 1 | 2 | 1 | 1 |
| 9 | 4 | 2 | 2 | 4 | 1 | 3 |
| 10 | 4 | 2 | 2 | 4 | 1 | 3 |
| 11 | 2 | 2 | 0 | 2 | 2 | 0 |
| 合計 | 35 | 22 | +13 | 37 | 17 | +20 |
| 差分の分布 | 分布数 | 分布数 | ||||
| ±0 | 4 | 1 | ||||
| ±1 | 2 | 3 | ||||
| ±2 | 4 | 4 | ||||
| ±3 | 1 | 3 | ||||
Built-Inの評価Flowの性能も初期の頃に比べると体感では上がっており、今後も性能向上に期待していますが、上記のようにBuilt-Inの評価Flowを参考に自作していくことも容易なので、用途に応じて評価Flowを自作し充実させていけるのもPrompt Flowの良いところかと思います。
今後の方向性
RAGアプリのよりよい運用のため、gitでのversion管理、git codeからPrompt Flow生成→評価→デプロイというフローの構築・自動化を進めております。
また、評価については様々な観点の評価Flowを組み合わせ、それらを統合することでRAGの性能を担保するものに仕上げていきたいと考えています。
現時点ではまだ特定のリポジトリしか対象にしておらず答えられる質問も限定的ですが、それでも使用してくれる人は少しずつ増えてきており、Good評価の回答も初期に比べると増えてきているため、より信頼出来て使いやすいRAGアプリ・QABotを目指して開発サイクルを回していき、生成系AIと共に働くという環境を社内に広げていけたらと考えている所存です。