
はじめに
この記事はドコモアドベントカレンダー24日目の記事になります。
素敵なクリスマスイブをお過ごしでしょうか🎄
こんにちは、NTTドコモ サービスイノベーション部3年目社員の上田です。
業務では主に、データ分析・機械学習に関する研究開発やビジネス適用を行っております。
昨年度のアドベントカレンダーで、時系列予測のライブラリとしてGreykiteを紹介しました。
今年の重大ニュースとして、Pythonで最もよく使われている時系列予測ライブラリの一つであるProphetについて、今年2/27に開発元のMetaから、今後基礎となるモデルに大きな変更を加えるつもりがないと記事が発表されました。
この記事中に、より最先端のイノベーションを求める方向けに2つのライブラリ(NeuralProphet、StatsForecast)が紹介されていました。
そこで、各ライブラリの使い勝手はどうなのだろうと気になり、今回試すことにしました。
本記事により、Pythonによる時系列予測の第一歩を踏み出す参考となれば幸いです。
対象者
- Pythonでの時系列予測に興味がある方
- 各ライブラリの特徴や実装方法を知りたい方
内容
- Prophet、NeuralProphet、StatsForecast、Greykiteについて
- 各ライブラリに対し、日次・月次のオープンデータに対して予測を実装し、精度を比較
- 各ライブラリのメリット・デメリット
Pythonの時系列予測
早速、今回4種類の時系列ライブラリを利用していこうと思います。
その前に、各ライブラリについて簡単に説明します。
Prophet
Pythonで最も有名な時系列ライブラリの1つです。
Metaが開発したもので、時系列の深い知識がなくても容易に予測を試すことができます。
NeuralProphet
上記のProphetと自己回帰型のニューラルネットワークモデルであるAR-Netをベースとした手法です。
解釈性や使いやすさはProphetそのままで、Deep Learningによる精度向上を目指しています。
1日以下の高い頻度や、長期の期間(少なくとも2つの期間や年)の時系列データを得意としています。
これまでProphetを使ってきていれば、移行は難しくないです。
ドキュメントにProphetからの移行ガイドというページもあったりします。
StatsForecast
様々な統計学的手法が高速に使えるライブラリです。
時系列の自己相関を利用するARIMA系を筆頭に、Theta系やGARCHなどの各手法や、自動で最適なパラメータを探索してモデル構築を行うAuto系(AutoARIMA、AutoETS、AutoCES、AutoTheta)を利用することができます。
今回はドキュメントでまず最初に用いられているAutoARIMAを利用していきます。
Greykite
Silverkiteをベースとしたライブラリで、可視化や手法ごとの比較に優れているLinkdInが開発したオープンソースのライブラリです。
昨年のアドベントカレンダーでGreykiteを試した記事を執筆しておりますので、詳細はそちらをご覧いただけると幸いです。
予測
今回、各手法どれも簡単に使い始められるというのをウリにしているため、各手法の細かいチューニング等はせず、元々どの程度の威力があるかを見ていきます。
環境構築
それぞれのライブラリはpipを用いて以下のようにダウンロードできます。
!pip install prophet !pip install neuralprophet !pip install statsforecast !pip install greykite
筆者の環境は以下の通りです。ProphetのみPythonのバージョンを3.9以上にすると他ライブラリのバージョンを変更する必要がある等手間がかかるため、Pythonのバージョンを下げています。
# prophetのみ python 3.8 prophet 1.1.1 # prophet以外 python 3.10.3 neuralprophet 0.6.2 statsforecast 1.6.0 greykite 0.5.1
他に必要なモジュールのインポートをします。
from prophet import Prophet from neuralprophet import NeuralProphet, set_log_level from statsforecast import StatsForecast from statsforecast.models import AutoARIMA from greykite.common.data_loader import DataLoader import pandas as pd import numpy as np %matplotlib inline import matplotlib.pyplot as plt import seaborn as sns import plotly # plotlyをJupyter Notebookで可視化するため from plotly.offline import init_notebook_mode, iplot init_notebook_mode()
利用データ
今回、2種類のデータを利用して予測を実施します。
- Peyton Manning(日次): Wikipediaページのビュー数の予測(log)
- Peyton Manningさんというアメリカの元アメリカンフットボール選手のWikipediaページのlog(日次ページビュー数)で、ProphetやGreykite等でまず試される主要なデータセットの一つです。
- 経常収支(月次): 日本の経常収支の予測
- 財務省が国際収支の推移を公表しており、そのうち国際収支総括表にある経常収支を利用します。
- 経常収支とは、一定期間における一国の海外とのモノやサービスの取引、投資収益のやりとりなど経済取引で生じた収支を示す経済指標であり、国際比較が可能なものです。
- 様々な外部要因により予測が難しいと思いますが、今回のモデルでどこまで捉えられるか気になったので利用します。
Peyton Manning
各手法を実装・評価していきます。
Peyton Manningのデータは、Greykiteに含まれているデータセットを利用します。
各手法に利用できるベース系まで変形します。
dl = DataLoaderTS()
ts = dl.load_peyton_manning_ts()
df = ts.df
df = df.rename(columns={'ts': 'ds'})
df = df.reset_index().drop(['index'], axis=1)

日別に日付の列と値の列が入っています。
共通で評価を行うため、データを学習・評価で分割しておきます。
今回は直近365日分(1年分)を評価データとし、それより前のデータを全て学習データとします。
test_len = 365
df_train = df.iloc[:-test_len]
df_test = df.iloc[-test_len:]
データを可視化すると以下の通りです。
黒線より左側が学習データ、右側が評価データです。
いくつかの外れ値はあるものの、過去傾向は結構安定しており、予測はしやすそうです。
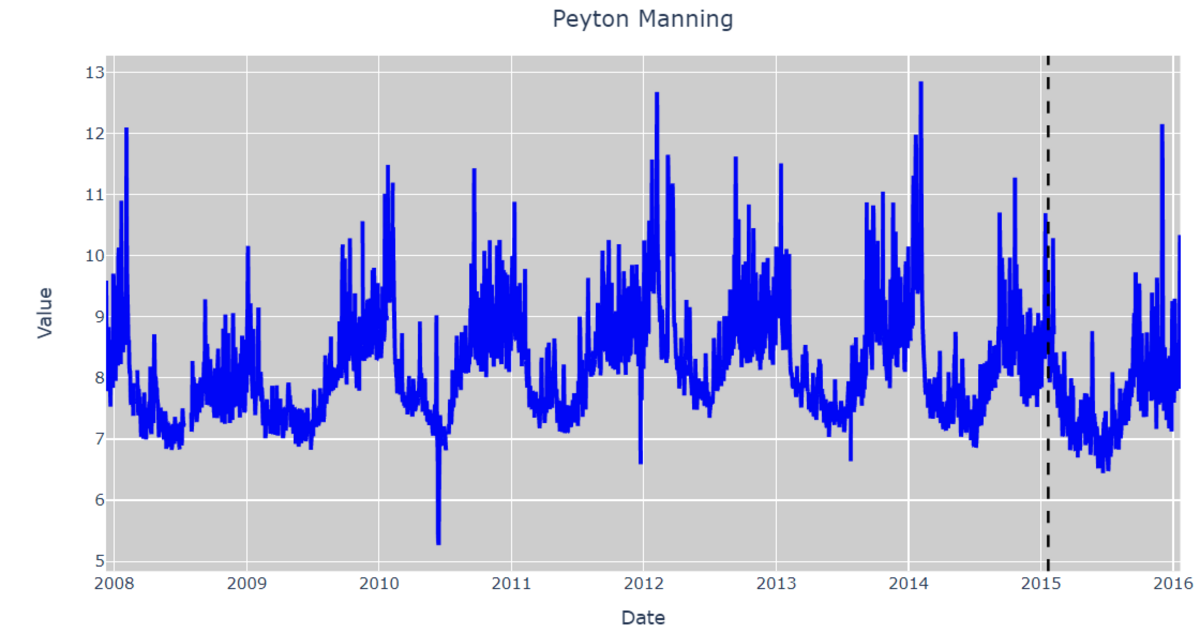
ここから各手法でモデル構築をします。
評価値は共通でMAPE(平均絶対パーセント誤差)とします。
Prophet
日別予測を想定して作られているので、データの形式が問題なければ容易に学習できます。
# Prophet用のデータ用意 df_train_prophet = df_train.copy() df_test_prophet = df_test.copy() # 学習 m = Prophet() m.fit(df_train_prophet) # 予測 future = m.make_future_dataframe(periods=test_len) forecast = m.predict(future) # 評価 test_forecast = forecast.tail(test_len) df_test_prophet['y_pred'] = test_forecast['yhat'].values print('MAPE: ', np.mean(np.abs((df_test_prophet['y_pred'] - df_test_prophet['y']) / df_test_prophet['y'])) * 100) # 可視化 m.plot(forecast)
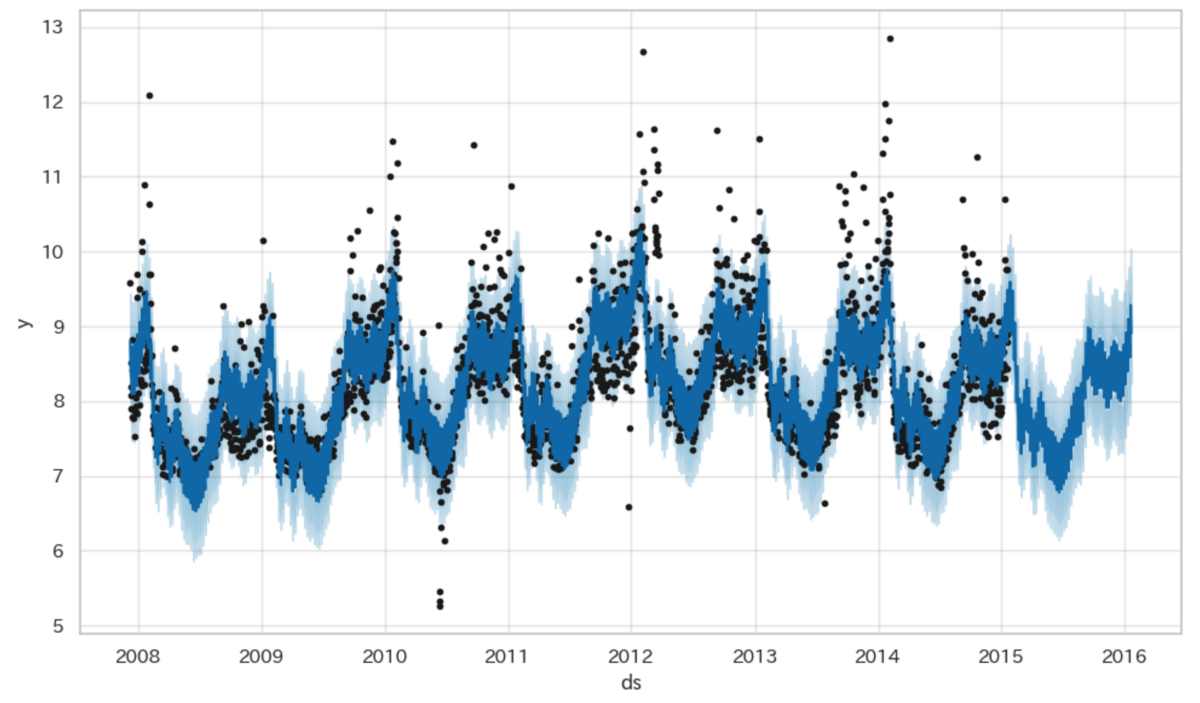
誤差は5.3%となりました。
ある程度の傾向は捉えられています。
NeuralProphet
NeuralProphetはProphetと似ている方法でモデル構築をすることができます。
# NeuralProphet用のデータ用意 df_train_neuralprophet = df_train.copy() df_test_neuralprophet = df_test.copy() # 余計なinfoを減らし、ログを見やすくする # これを実行しないと結構な数のinfoが出てくる set_log_level("ERROR") # 学習 m = NeuralProphet() # plotly-staticはエラーで利用できなかったため、こちらを指定 m.set_plotting_backend("plotly") metrics = m.fit(df_train_neuralprophet, progress=None) # 予測 df_future_neuralprophet = m.make_future_dataframe(df_train_neuralprophet, n_historic_predictions=True, periods=test_len) forecast = m.predict(df_future_neuralprophet) # 評価 df_test_neuralprophet['y_pred'] = forecast.iloc[-test_len:]['yhat1'] print('MAPE: ', np.mean(np.abs((df_test_neuralprophet['y_pred'] - df_test_neuralprophet['y']) / df_test_neuralprophet['y'])) * 100) # 可視化 m.plot(forecast)

誤差は6.1%となりました。
Prophet同様、ある程度傾向が捉えられています。
StatsForecast
# StatsForecast用のデータ用意 df_train_statsforecast = df_train.copy() df_test_statsforecast = df_test.copy() # StatsForecastではカテゴリを入れることが必要 df_train_statsforecast['unique_id'] = 'peyton_manning' df_test_statsforecast['unique_id'] = 'peyton_manning' # 学習 # 日別予測では周期性を7にするのが良さそう sf = StatsForecast( models = [AutoARIMA(season_length=7)], freq = 'D', n_jobs = -1 ) sf.fit(df_train_statsforecast) # 予測 forecast = sf.predict(test_len) # 評価 df_test_statsforecast['y_pred'] = forecast['AutoARIMA'].values print('MAPE: ', np.mean(np.abs((df_test_statsforecast['y_pred'] - df_test_statsforecast['y']) / df_test_statsforecast['y'])) * 100) # 可視化 sf.plot(df_train_statsforecast, forecast, engine='plotly')

誤差は17.6%となりました。
予測値を見ると一直線になっており、うまく時系列の傾向を捉えられていないです。
StatsForecastを作成したNixtla社のCEO記事やそのディスカッションにもある通り、ARIMAが本データセットのような複数の季節性があるデータに対してはうまく捉えられないことが原因と推察します。
Greykite(Silverkite)
# Greykite用のデータ用意 df_train_greykite = df_train.copy() df_test_greykite = df_test.copy() df_greykite = pd.concat([df_train_greykite, df_test_greykite]) # 学習、予測 forecaster = Forecaster() metadata = MetadataParam( time_col='ds', value_col='y', freq='D', train_end_date=df_train_greykite.iloc[-1]['ds'] ) result = forecaster.run_forecast_config( df=df_greykite, config=ForecastConfig( model_template=ModelTemplateEnum.SILVERKITE.name, forecast_horizon=test_len, metadata_param=metadata ) ) # 評価 forecast = result.forecast print('MAPE: ', np.mean(np.abs((forecast.df['forecast'] - forecast.df['actual']) / forecast.df['actual'])) * 100) # 可視化 fig = forecast.plot() plotly.io.show(fig)

誤差は4.2%となりました。
最も良い精度が得られています。
財務省の経常収支
こちらのデータセットに対しても同様に各手法を実装・評価していきます。
データは、財務省が国際収支の推移のうち、国際収支総括表【月次】ファイルの経常収支のみ抽出したものを利用します。
各予測に使えるように、あらかじめ列などは変形しておいています。
用いるデータの期間は1996年1月〜2022年12月としております。
値の単位は億円です。
df = pd.read_csv('current_account.csv')
df

今回は直近12ヶ月分(1年分)の予測をするべく、学習・評価データの分割をします。
test_len = 12
df_train = df.iloc[:-test_len]
df_test = df.iloc[-test_len:]
データを可視化すると以下の通りです。
黒線より左側が学習データ、右側が評価データです。
Peyton Manningのデータとは違い、時期により値が大きく変動しており、また評価期間のデータが直近の傾向とずれているため、予測は難しい印象です。

ここから各手法でモデル構築をします。
今回評価値は共通でMAE(平均絶対誤差)とします。
先ほどまでのMAPEにすると値が大きくなりすぎたため、何億円のズレがあるか数値で見たいためです。
Prophet
ベースが日別であるため、月別と明示します。
# Prophet用のデータ用意 df_train_prophet = df_train.copy() df_test_prophet = df_test.copy() # 学習 m = Prophet() m.fit(df_train_prophet) # 予測(月別に指定) future = m.make_future_dataframe(periods=test_len, freq='MS') forecast = m.predict(future) # 評価 test_forecast = forecast.tail(test_len) df_test_prophet['y_pred'] = test_forecast['yhat'].values print('MAE: ', np.mean(np.abs(df_test_prophet['y_pred'] - df_test_prophet['y']))) # 可視化 m.plot(forecast)

誤差は9,011億円となりました。
過去の傾向をしっかり捉えるというよりは、大局的に捉えた予測となっています。
NeuralProphet
NeuralProphetはProphetと結構似ている方法でモデル構築をすることができます。
# NeuralProphet用のデータ用意 df_train_neuralprophet = df_train.copy() df_test_neuralprophet = df_test.copy() # 余計なinfoを減らし、ログを見やすくする # これを実行しないと結構な数のinfoが出てくる set_log_level("ERROR") # 学習(月別に指定) m = NeuralProphet() # plotly-staticはエラーで利用できなかったため、こちらを指定 m.set_plotting_backend("plotly") metrics = m.fit(df_train_neuralprophet, progress=None, freq='MS') # 予測 df_future_neuralprophet = m.make_future_dataframe(df_train_neuralprophet, n_historic_predictions=True, periods=test_len) forecast = m.predict(df_future_neuralprophet) # 評価 df_test_neuralprophet['y_pred'] = forecast.iloc[-test_len:]['yhat1'] print('MAE: ', np.mean(np.abs(df_test_neuralprophet['y_pred'] - df_test_neuralprophet['y']))) # 可視化 m.plot(forecast)
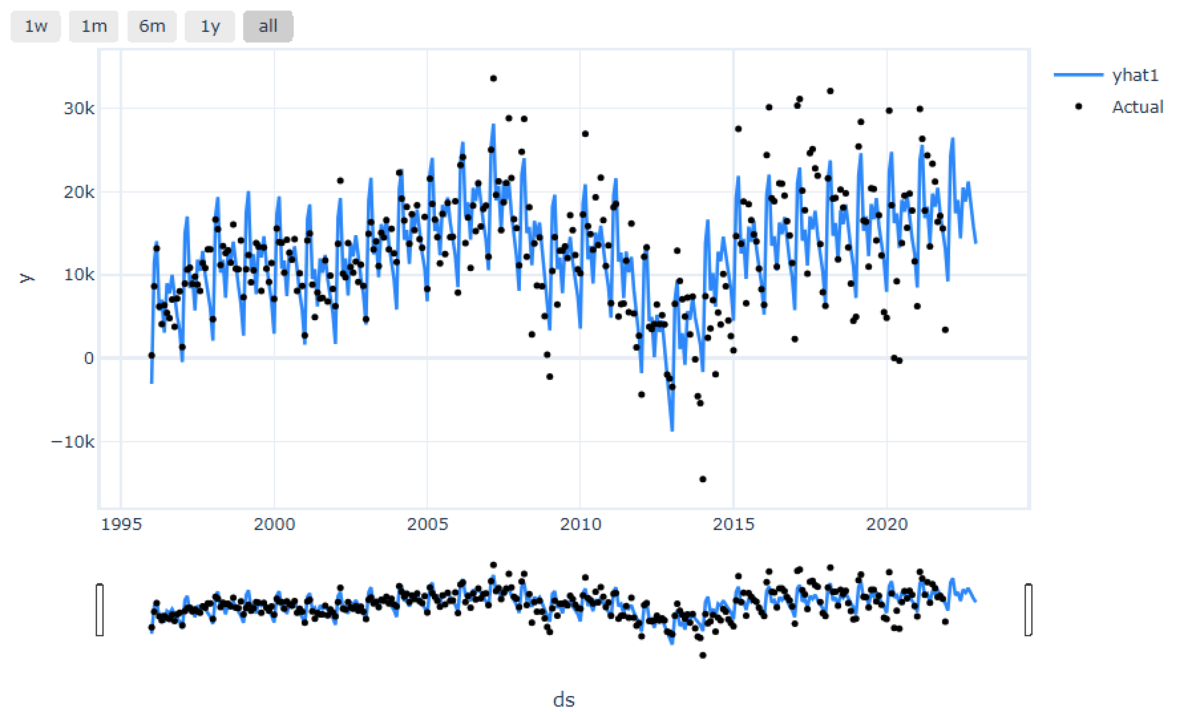
誤差は10,607億円となりました。
Prophetより誤差が大きいですが、過去の増減をある程度捉えられているように見えます。
StatsForecast
# StatsForecast用のデータ用意 df_train_statsforecast = df_train.copy() df_test_statsforecast = df_test.copy() # StatsForecastではカテゴリを入れることが必要 df_train_statsforecast['unique_id'] = 'current_account' df_test_statsforecast['unique_id'] = 'current_account' # 学習 # 月別予測では周期性を12にするのが良さそう sf = StatsForecast( models = [AutoARIMA(season_length=12)], freq = 'M', n_jobs = -1 ) sf.fit(df_train_statsforecast) # 予測 forecast = sf.predict(test_len) # 評価 df_test_statsforecast['y_pred'] = forecast['AutoARIMA'].values print('MAE: ', np.mean(np.abs(df_test_statsforecast['y_pred'] - df_test_statsforecast['y']))) # 可視化 sf.plot(df_train_statsforecast, forecast, engine='plotly')

誤差は9,028億円となりました。
Peyton Manningでは一直線の予測でしたが、こちらは季節性を捉えた予測になっています。
Greykite(Silverkite)
# Greykite用のデータ用意 df_train_greykite = df_train.copy() df_test_greykite = df_test.copy() df_greykite = pd.concat([df_train_greykite, df_test_greykite]) # 学習、予測(月別を指定) forecaster = Forecaster() metadata = MetadataParam( time_col='ds', value_col='y', freq='MS', train_end_date=df_train_greykite.iloc[-1]['ds'] ) result = forecaster.run_forecast_config( df=df_greykite, config=ForecastConfig( model_template=ModelTemplateEnum.SILVERKITE.name, forecast_horizon=test_len, metadata_param=metadata ) ) # 評価 forecast = result.forecast print('MAE: ', np.mean(np.abs(forecast.df['forecast'] - forecast.df['actual']))) # 可視化 fig = forecast.plot() plotly.io.show(fig)
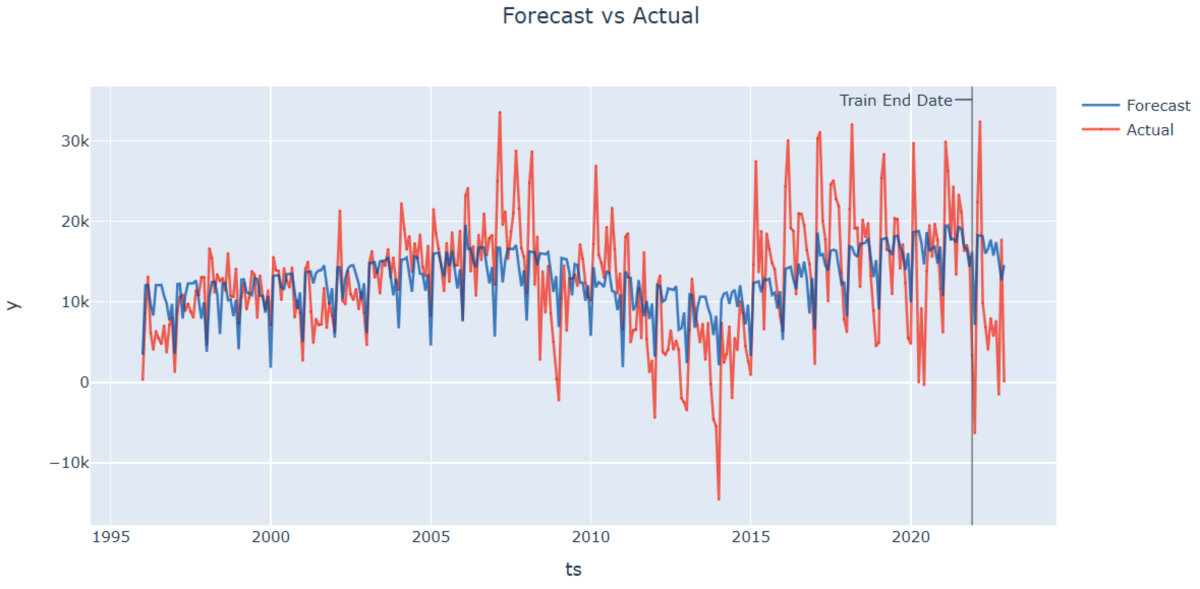
誤差は4,481億円となりました。
こちらのデータセットでも最も精度が良いですね。
結果まとめ
各手法・各データセットにおける精度をまとめると、以下のようになります。
| 手法 | 誤差 Peyton Manning(MAPE) | 誤差 経常収支(MAE) |
|---|---|---|
| Prophet | 5.3(%) | 9,011(億円) |
| NeuralProphet | 6.1(%) | 10,607(億円) |
| StatsForecast(Autoarima) | 17.6(%) | 9,028(億円) |
| Greykite(Silverkite) | 4.2(%) | 4,481(億円) |
精度で見るとGreykite(Silverkite)が最も良いように見えますが、あくまで今回のデータセットとチューニング等をしない場合の精度のため、ベースとしての参考値になります。
所感としては以下になります。
| 手法 | メリット | デメリット |
|---|---|---|
| Prophet | ・最も有名なものの一つで参考記事が多く、最初の実装や精度向上をしやすい | ・今後Meta社による大幅アップデートがない |
| NeuralProphet | ・Prophetと似た実装ができるため、Prophetからの移行がしやすい ・Deep Learningによる精度向上が見込める |
・Prophetより精度が良くなるとは限らない |
| StatsForecast | ・各種統計学の手法を容易に使える | ・精度向上させるのに実装時間がかかる |
| Greykite(Silverkite) | ・ベースとしての精度が良い ・可視化等の機能が優れている |
・実装がやや難しい(解説記事も現状少ない) |
まとめ
今回はPythonで時系列予測が行える4つのライブラリを試して比較してみました。
各手法ごとにメリット・デメリットがあり、これを使えば何にでも完璧というものは存在しないので、用途に合わせて使い分けをしていくのが望ましいと考えています。
時系列予測と共に、良いクリスマスを🎁