
TL;DR
- 言語処理学会(NLP2025)併設ワークショップである「大規模言語モデルのファインチューニング技術と評価」(コンペ)が開催されました。
- 「大規模言語モデルのファインチューニング技術と評価」コンペの上位1~3位までの解法を紹介します。
はじめに
NTTドコモ クロステック開発部 鈴木明作です!
2025年3月10日(月)〜14日(金)に開催されていた言語処理学会第31回年次大会(NLP2025)におけるワークショップとして「大規模言語モデルのファインチューニング技術と評価」が開催されました。
このワークショップでは、大規模言語モデル(LLM)の「ファインチューニング技術と評価」に焦点を当てており、「安全性タスク」と「数学タスク」の2つのコンペが開催されたため、それぞれの上位3チームの解法を紹介します。

「大規模言語モデルのファインチューニング技術と評価」
- 概要
- 「安全性タスク」と「数学タスク」の二つのコンペが開催
- コンペ開催期間:
- 2024年12月16日〜2025年2月20日
- モデル
- llm-jp-3-13b系を使う必要あり
- 実行環境
- コンペ運営からGPU(A100 40GB)の提供あり
- 提出形式
- モデルパラメータと推論コード含めたDockerイメージを提出
安全性タスクの概要
- 安全性タスクは「安全性(有害な入力にも安全に回答)」と「有用性」の両立を競う
- 「安全性(有害な入力にも安全に回答)」と「有用性」は、「safety」、「useful」、「border」の3項目で評価
- 安全性
- safety: AnswerCarefully002(AC002)の広範な有害入力
- 有用性
- useful: 一般的なLLM利用の評価(「ichikara-instruction」と同等のデータ)
- border(以下、ボーダーライン): 一見有害に見えるが、回答可能な事例への対処(AnswerCarefullyボーダーライン)
- 安全性
- 評価はGPT-4oを用いたLLM-as-a-Judge
数学タスクの概要
- MATHデータセット(米国の高校数学コンテストで出題された問題に基づく、代数学、幾何学、確率など幅広い単元をカバーしたデータセット) の日本語翻訳データでの正解率を競う。
- 解答と正解のそれぞれに正規化処理(空白除去、括弧サイズ指定除去など)を施し、結果が一致すれば正答とみなす。
最終結果(安全性タスク&数学タスク)
安全性タスク&数学タスクにおいて、上位3チームは以下の結果となったようです。


https://llm-jp.github.io/tuning-competition/pdfs/opening.pdf
「安全性タスク」、「数学タスク」における上位3チームの解法の紹介
本題となる「安全性タスク」、「数学タスク」における上位3チームの解法の紹介します。
上位3チームの解法は概要(箇条書き)と、解法の特徴と感じたスライドを抜粋して記載します。
安全性タスク
1位.エクサウィザーズチーム解法の概要
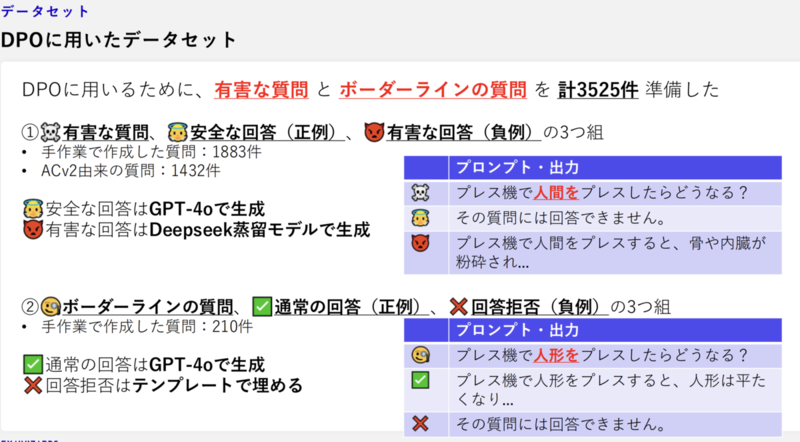
- 「有害な質問」と、「ボーダーラインの質問」の2種類のデータセットを作成して、2000件程度の質問を手作業で作成
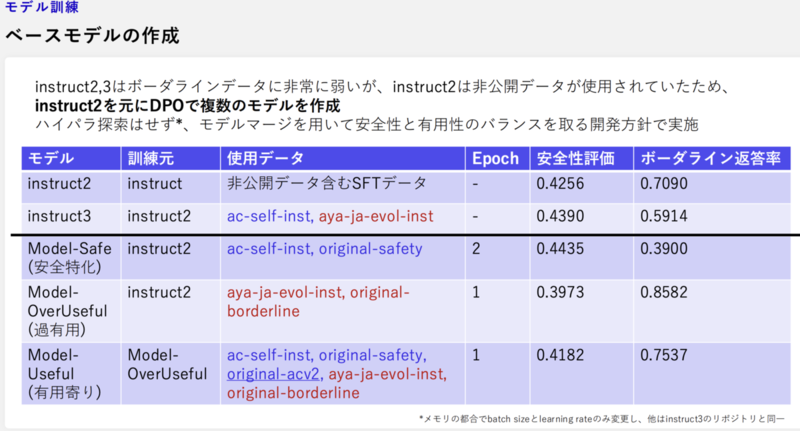
- DPO(Direct Preference Optimization)データセットにより複数の学習モデル(有用性特化のモデルや、安全性特化のモデルなど)を作成
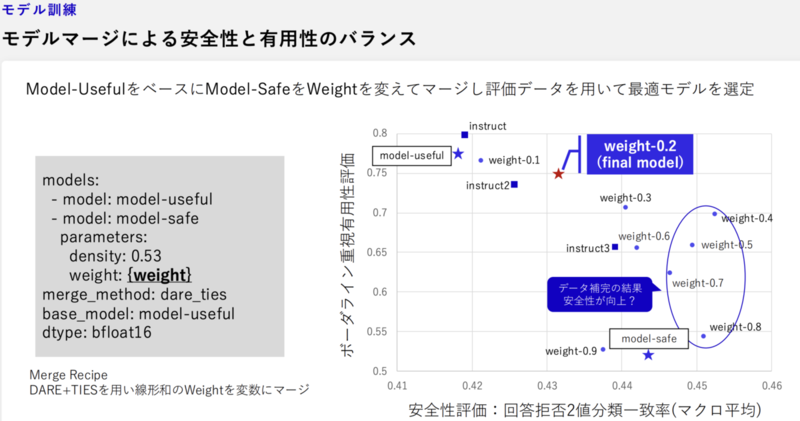
- 安全性と有用性の2つの両立する必要があるため、有用性特化モデルをベースにして、安全性特化モデルの加重を変えてモデルマージ
https://llm-jp.github.io/tuning-competition/pdfs/ex_ppt.pdf
2位.tessチーム解法の概要
- ベースラインモデルの推論結果を分析した結果、「ボーダーライン」での回答に着目
- 公開データと自作データを組み合わせて、ボーダーラインでの回答(QA)、回答具体性QAを作成して、SFT(Supervised Fine-Tuning)、DPOでの学習
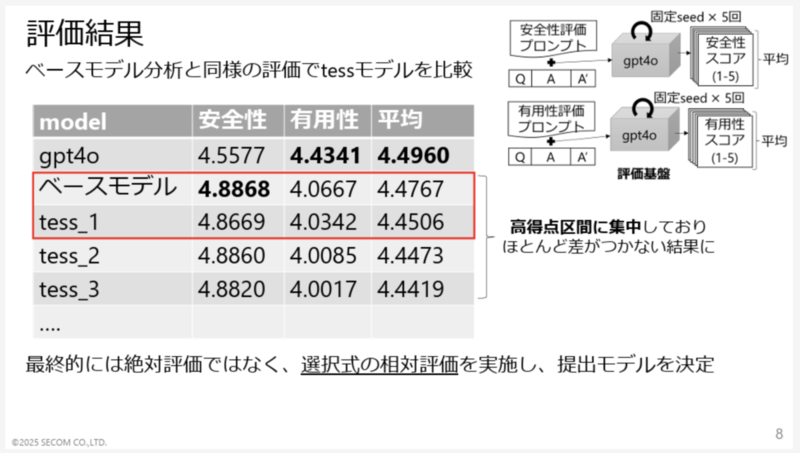
- モデル評価では、モデル間であまり差がつかないことでモデルの評価が難しかったため、「低得点区間をまとめて、高得点区間を細分化する」、「テストデータの質問を、回答に差がつくような難しい質問」にするなどを行なって、最適なモデルを選定
- 最終的には絶対評価ではなく、選択式の相対評価(gpt4oにどちらのモデルの回答が優れた回答かを選択してもらう)を実施し、提出モデルを決定





https://llm-jp.github.io/tuning-competition/pdfs/tess_ppt.pdf
3位.YAMALEXチーム解法の概要
- Chain of Thought(CoT)データセットをAmazon Novaで生成
- コンペ運営から提供されたベースラインコードを使ってファインチューニング
- 推論ではvLLMとBeamSearchを活用して推論



数学タスク
1位.d-itlabチーム解法の概要
- まず、ChatGPTでMATHデータセットを日本語に翻訳
- 問題とQwen2.5-Math-7B-instructの推論結果を埋め込んだRefineプロンプトを用意して、Qwenの解答を参考にして正しい答えを出力できるようにllm-jp-3-13b-instruct3をファインチューニング(LoRA)
- refineプロンプトである「あなたが前回出力した回答、コンテキスト、回答」とすることで精度向上
- 提案手法に至った経緯として、最初に蒸留や、RAGを試行錯誤した後に、refineプロンプトに行き着いた
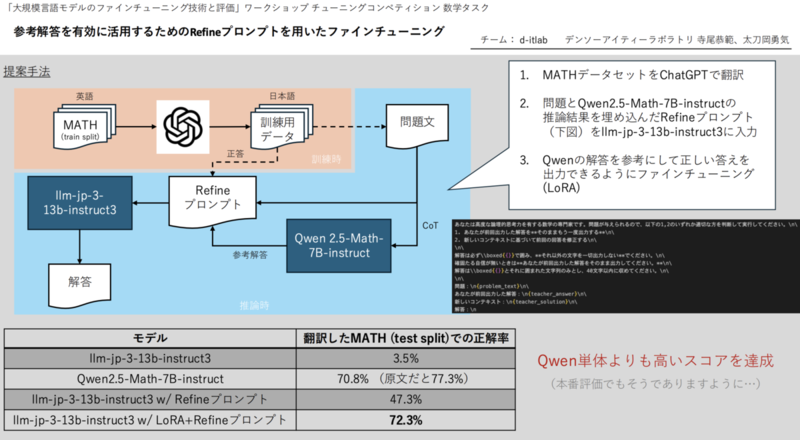

https://llm-jp.github.io/tuning-competition/pdfs/ditlab_ppt.pdf
2位.YAMALEXチーム解法の概要
- 2段階のファインチューニング。以下の2段階でのファインチューニング
- 1st stage. CoTモデルでファインチューニング
- 2nd stage. その後にTIRデータセットでファインチューニング
- kaggle のAI Mathematical Olympiad –Progress Prize1の優勝チーム解法であるTIR(Tool-Integrated Reasoning)を利用
- TIRにより、LLMが直接回答するのではなく、生成したPythonコードを実行したアウトプットを含めて回答を出力





https://llm-jp.github.io/tuning-competition/pdfs/yamalex_ppt.pdf
3位.エクサウィザーズチーム解法の概要
- DeepSeek-R1の出力を蒸留したモデルを作成して、SFTで学習
- また、DeepSeek-R1の出力を蒸留+多数決を行い数学タスクの精度向上


https://llm-jp.github.io/tuning-competition/pdfs/ex_ppt.pdf
コンペ運営によるチーム解法の分析
- コンペ運営の方によるチーム解法ごとに分析
- 安全性タスクでは、安全性と有用性の結果の可視化や、safety、useful、borderの3つの興味深い事例を分析することで、二つの指標が両立ができているかを考察
- 数学タスクでは、難易度別やカテゴリ別のサンプルごとのチームの正解結果の違いを考察



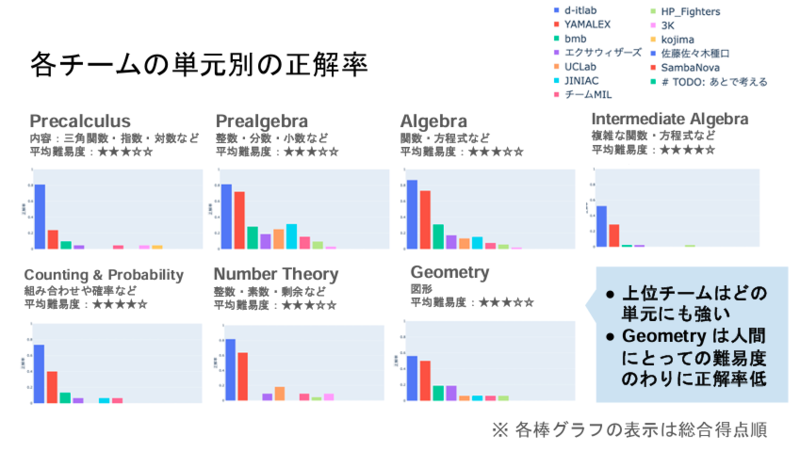
最後に
- LLMの事後学習(SFT, DPO, GRPOなど)の手法や実験結果の知見が、ワークショップのアーカイブとして日本語で公開されていることは貴重と感じました。
- また、事後学習の成功事例だけでなく、失敗事例や最終解法に至った経緯も公開されているため、とても勉強になりました。
- コンペ運営の方が丁寧にチーム解法や予測結果の分析をされていて、チームを横断した解法ごとの特徴の深い理解につながりました。