
はじめに
はじめまして、NTTドコモ コアネットワークデザイン部の木戸です。
私は業務で、モバイルネットワークの音声領域(IMS)に関する仕様検討や課題解決を担当しています。まだ入社1年目で、専門用語が飛び交う世界に日々奮闘中です。
そんな中、「認識合わせってめちゃくちゃ時間かかるな…」と感じました。新入社員として、既存の仕様を理解したり、理解した仕様を説明することの難しさを痛感し、どうにか効率的に技術的なコミュニケーションをとれないかと考えました。
今回はM365 Copilotを使った技術的なコミュニケーションの分析とその結果から考えた業務勉強の仕方について紹介します。
メインの想定読者
- ネットワーク系に興味のある学生
- ネットワーク系業務に取り組む新入社員
※本記事でいう「ネットワーク系」は、一般に想定されるL2/L3のNWインフラ業務ではなく、サービス制御・シグナリング(アプリケーション層寄り)のような少し上位レイヤーに関する業務を対象としています。
参考: IMS(IP Multimedia Subsystem)とは
IMS(IP Multimedia Subsystem)は、携帯ネットワークで音声通話やビデオ通話などのサービスをIPベースで提供する仕組みです。
SIPというプロトコルを使ってセッションを制御し、認証や課金などの機能も統合します。
VoLTEや5Gの通話サービスの基盤となる重要なアーキテクチャです。
業務での課題
入社して最初に思ったことはとにかく会議が多い!しかも専門用語だらけで、議論のポイントをつかむのが難しいです。 さらに、仕様検討では「認識合わせ」がとても重要です。ここでズレると後工程で大きな手戻りが発生します。
実際、ある仕様検討では調査に26時間、認識合わせに35時間かかったこともありました。 「この時間はなんとかならないのか」というのが今回の出発点です。
M365 Copilotを用いて議事録を分析!
どんなコメントに対応できるようになれば認識合わせを効率化できるか。それを見つけるために議事録を分析することにしました。
今回はMicrosoft社が提供しているLLMである「M365 Copilot」を使用して、議事録を分析してみました。ちなみに使用モデルはGPT-5です。
まずはステークホルダーを知る
会議の相手が何を気にするのかがわかれば、資料の準備も楽になり、コミュニケーションも取りやすくなるのでは?と思い、会議相手についてチームメンバーにヒアリングしてみました。
| ステークホルダー | 説明 | 議論ポイント | 1週間のやり取り数 |
|---|---|---|---|
| IMS開発チームメンバー | 同じチームのメンバー | 音声開発に関するすべての内容 | 8 |
| IMS設備計画・保全メンバー | 設備の設置をしたり、ネットワーク運用をするメンバー | 機能開始手順や運用するにあたっての差分 | 1 |
| 部長・組織長 | 組織のトップ | IMS開発に関するすべての内容(粒度は大きめ) | 3 |
| 他の開発担当 | IMS以外のネットワークを構築しているシステムの開発をしている | IMSノードとその他の担当のノード(5GCなど)の接続についての内容 | 2 |
| 開発依頼元 | 開発をしてくださいという要望を出している人たち | 機能分担やお客様影響についての内容 | 2 |
| ベンダ | 検討した仕様を実現してくれる人たち(他社) | IMSノードの仕様の詳細な内容 | 5 |
この表から、さまざまなステークホルダーとの議論があり、ステークホルダーごとに議論ポイントが全く違うこともわかります。
では、各ステークホルダーが何を気にしているのかを詳しく分析してみれば、コミュニケーションの取り方も工夫できるのではないかと考え、過去の議事録をLLM分析してみることにしました。
また、先の表から開発チーム内でのコミュニケーションが最も多く、次いでベンダとのコミュニケーションも多いことが分かっています。なので、この記事では開発チーム内とベンダの議事録をLLM分析した結果を見ていきます。
分析の流れ
分析は以下の画像のような流れで実施しました。

- TeamsやSharePointから過去の議事録コメントを収集する(社内ではM365製品をメインで使用しています)
- 議事録コメントから観点を抽出
- 抽出した観点(タグ)で議事録のコメントを分類
- 分類結果を集計し、可視化
議事録を集めてタグ設計
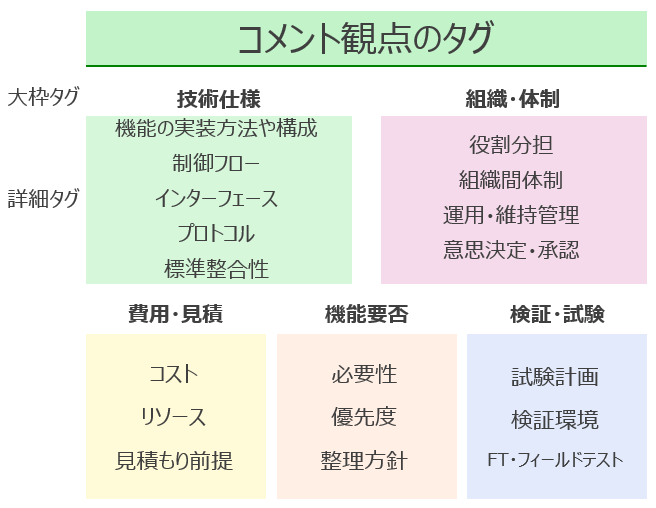
TeamsやSharePointから過去の議事録コメントを収集し、議論の観点を整理してタグを設計しました。 まず、M365 Copilotにコメントを分析させ、どんなタグが作れそうかを出力させました。 その結果を確認してから、自分の手でタグの過不足を修正するという形でタグを決定しました。 大枠のタグと詳細なタグで二段階用意し、理解しやすい分類ができるよう心掛けました。
このタグについては改善の余地ありかと思うので、今後も修正はしていく予定です。
タグ例
詳細な説明については 参考 をご確認ください。
M365 Copilotでコメント分析
M365 Copilotにて上記の観点タグを使ってコメントを分類しました。 以下にプロンプト例を示しています。こだわりポイントは結果集計と可視化を自動でしやすいように出力形式をJSONにしたところでしょうか(JSONを選んだのは気まぐれですが、とにかくすぐにプログラムから読み込める形式の必要がありました)。
これで「どの観点が多いか」「誰がどんな話題を重視しているか」が分かるようになりました。
プロンプト例
前提
- NTTドコモのコアネットワーク IMS開発に取り組んでいる
- 開発に関わる認識合わせの難易度が高いことを改善したい
- そのための前段階として、認識合わせの場でのコメントの傾向を分析しようとしている
依頼 以下のタグに沿って、下記の議事録のコメントを分類してください。出力形式は以下の#出力形式 に従って分類してください。
タグ
- 技術仕様(大枠タグ)
- 機能の実装方法や構成 (詳細タグ)
- 制御フロー (詳細タグ)
- インターフェース (詳細タグ)
- プロトコル (詳細タグ)
- 標準整合性 (詳細タグ)
- 費用・見積(大枠タグ)
- コスト (詳細タグ)
- リソース (詳細タグ)
- 見積もり前提 (詳細タグ)
- 機能要否(大枠タグ)
- 必要性 (詳細タグ)
- 優先度 (詳細タグ)
- 整理方針 (詳細タグ)
- 検証・試験(大枠タグ)
- 試験計画(詳細タグ)
- 検証環境 (詳細タグ)
- FT・フィールドテスト (詳細タグ)
- 組織・体制(大枠タグ)
- 役割分担 (詳細タグ)
- 組織間体制 (詳細タグ)
- 運用・維持管理 (詳細タグ)
- 意思決定・承認 (詳細タグ)
出力形式
{ "title": "<会議名>", "stakeholder": "", "comments": [ { "コメント": "<コメント1>", "大枠タグ": "<タグ1>", "詳細タグ": "<タグ1>", "コメント者": "<コメント者名1>", "回答": "<回答1>" }, … ] }なお、コメント者キーが不明な場合は"不明"という値を入れてください。また、stakeholderキーにはなにも記入しないでください。矢印の先がコメントに対する回答になっていることが多いですが、コメントと回答の分類はあなたの判断で実施してください。
議事録 <ここに議事録を貼る>
出力をJSON形式にしたのは気分です、、
ちなみに、この分類作業は自力で1つずつコメントをタグに分けることもできますが、膨大な時間がかかるのでM365 Copilotに任せました。
1議事録当たり1分程度で仕上げてくれますが、これを人手でやっていると1時間以上かかっていたと思うので、かなり効率的にコメントを分類できました。
分析結果と考察
結果の集計
タグごとにコメント数を集計する作業やグラフを作成するPythonプログラムもCopilotに作成させました。プログラムは省略しますが、1分程度でそれなりの質のプログラムを作ることができて、ここでもLLMの進化を感じました。
では、分析結果を見ていきましょう。
分析結果
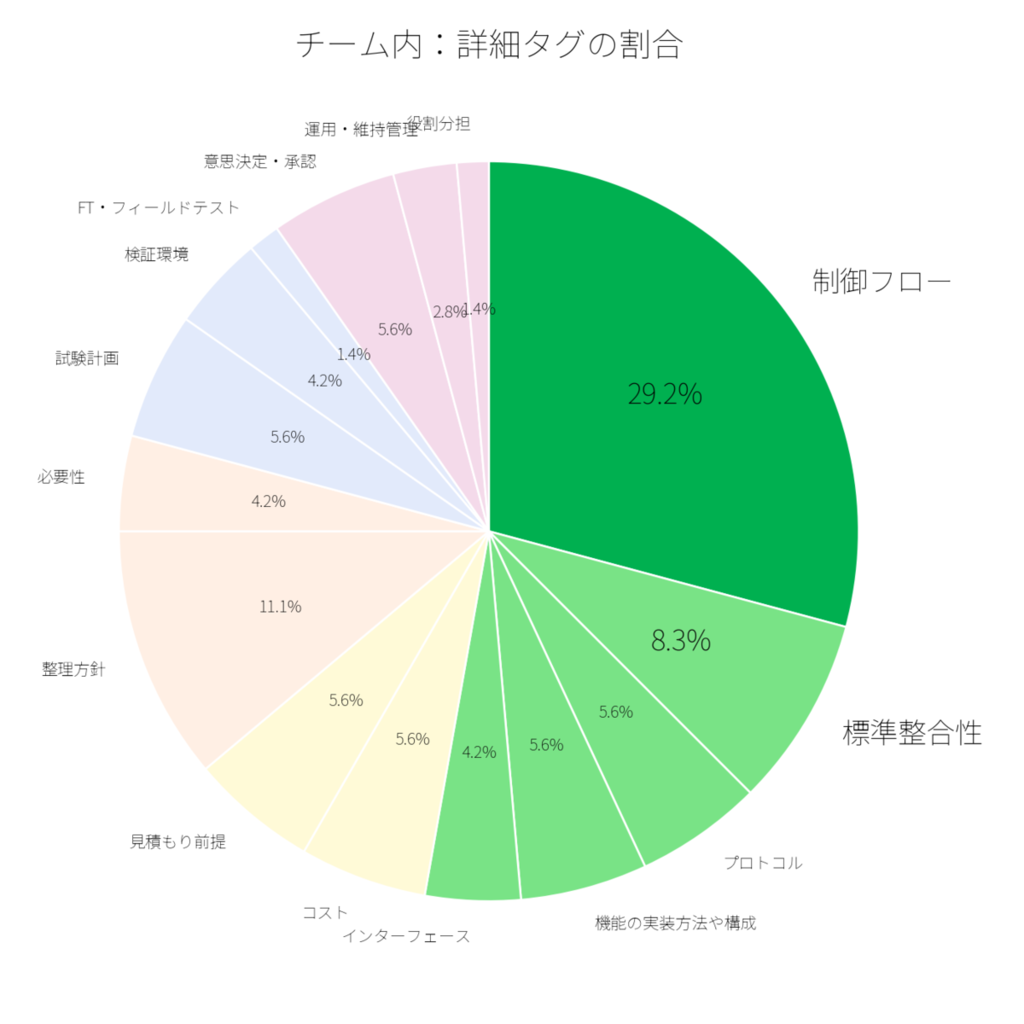
チーム内の結果は以下のようになりました(n=72)。 大枠タグでは技術仕様についてのコメントが多数を占めていると分かります。 その中でも、詳細タグでは制御フローの割合が特に多いと分かりました。
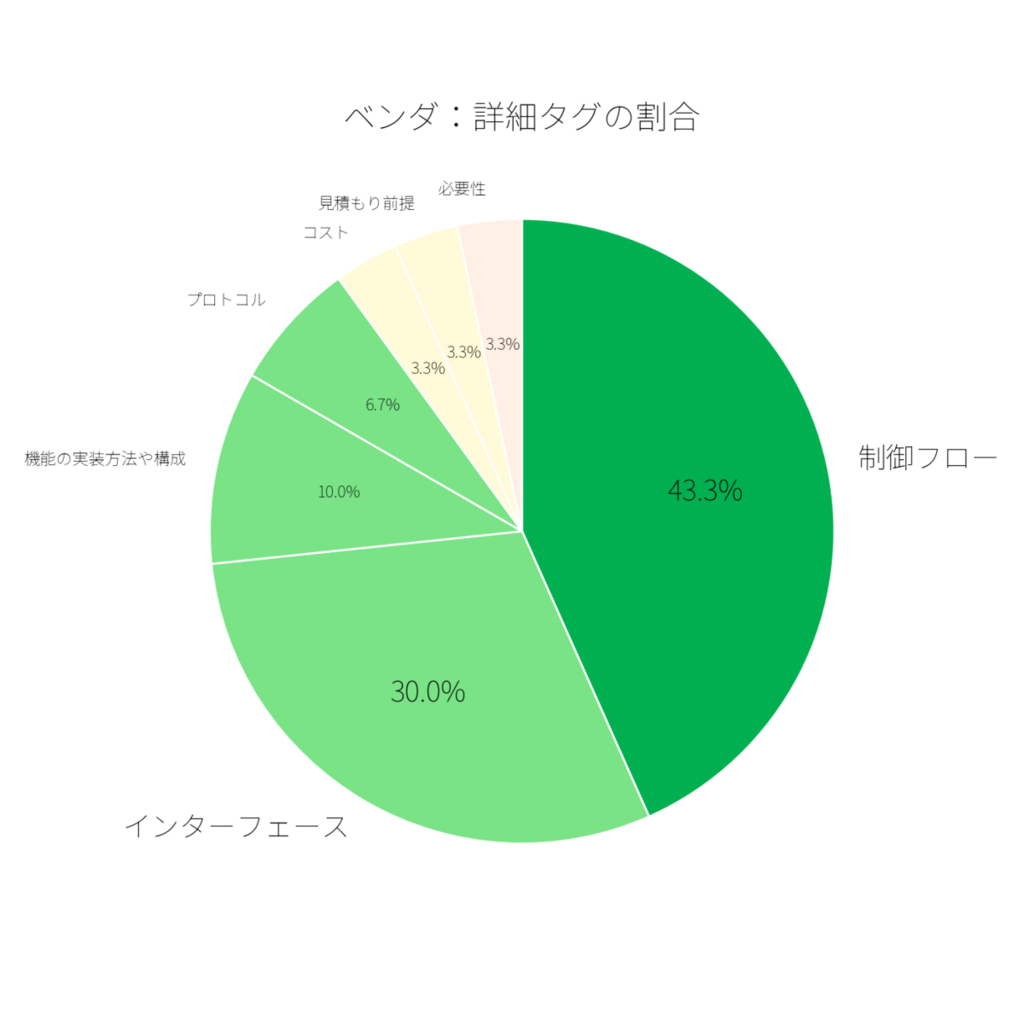
ベンダの結果は以下のようになりました(n=62)。 ここでも圧倒的に技術仕様のコメントが多いですね。
その他のステークホルダーについても技術仕様のコメントが多数派を占めていました。
考察
技術仕様に関するコメントが圧倒的に多い
チーム内での認識合わせとベンダとの認識合わせのどちらも技術仕様の割合が最大となりました。
これは、今回結果を示していない、他のステークホルダー(IMS設備計画・保全メンバーや開発依頼元など)でも同様の傾向でした。
当たり前ですが、開発メンバーは技術仕様についての深い理解が求められていることが分かりますね。
技術仕様の詳細タグの中でも特に多かった制御フロー
制御フローは下記の参考にも示していますが、『機能やサービスが「どんな順序で動作するか」や「動く契機」に関するコメント』につけられるタグです。これを我々はシーケンス図として仕様に残しています。
シーケンス図はUMLで規定されており、下図のようにクラスやオブジェクト間のやり取りを時間軸に沿って視覚的に表現する図です。ネットワーク分野では横方向にノード(装置)を並べ、上から時系列順に処理を1つずつ示す形で表現します。
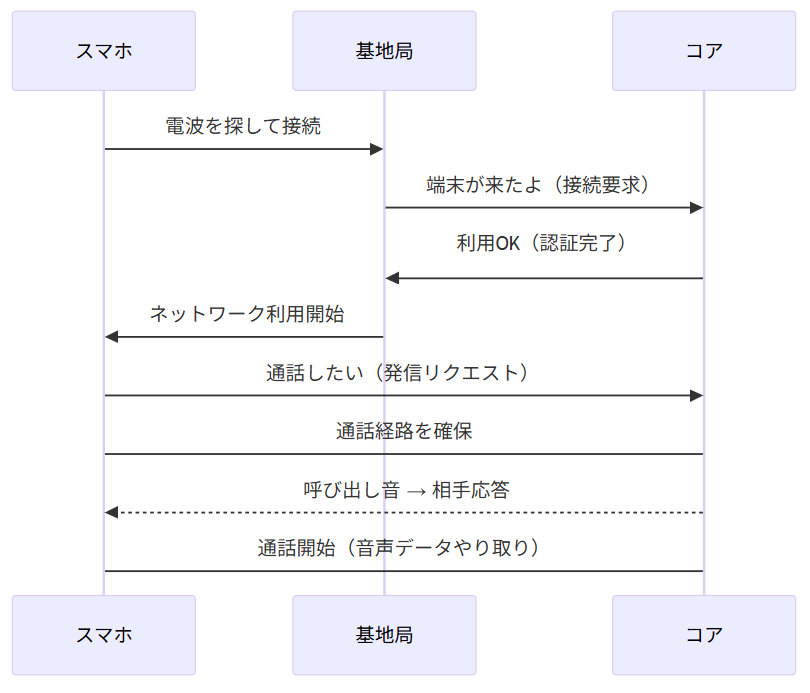
シーケンス図を使えば視覚的に処理の流れ(制御フロー)を追うことができます。
つまり、シーケンス図をしっかり理解することが認識合わせの近道だと考えることができます。
モバイルネットワーク系新入社員はシーケンス図への理解を深めよ!!
上述の結果は先輩チームメンバーの肌感覚とも一致しているようでした。もちろんシーケンス図だけ理解していればいいというわけではありませんが、右も左もわからない若手社員は、まずシーケンス図をたくさん読んでみるのがいい学習方針と言えますね!
シーケンス図の勉強法
新入社員からしたらここからの内容の方が大切です!
「シーケンス図の理解が大切」と分かってもどうやって理解すればいいかが分からなければ動き出せません。
ではどうすればいいかというと...
壊して覚える
従来のシーケンス図の勉強は、①読む → ②写す → ③覚えるのステップに終始しがちです。
もちろん、この3ステップが王道だと思いますし、実際私もこのステップでシーケンス図の勉強をしています。
でも、ネットワークエンジニアとして本当に求められる力は、「図面を暗記すること」ではないとも思っています。
私が特に気にしているポイントは、“図のどこで人が議論につまずくか” を嗅ぎ分ける力 です。
ここからは、まだ実践できていませんが、私が考えている勉強方法を紹介します(勉強方法を調査する中で考え付いたものです)。
シーケンス図を壊してみる
技術仕様コメント、とくに“制御フロー”が圧倒的に多い という結果が出ていました。
この制御フローの議論は、実務では以下の場所で荒れがちです。
- 条件分岐(if文相当)
- 例外処理(Error/Failure)
- 並列処理(Parallel)
- 再送やリトライの契機
- タイマー値
- 先に動くべきノードは誰か
シーケンス図を読むとき、「きれいな成功パスを見る」のではなく、“議論の衝突点” に印をつける習慣を持つ と、理解速度が一気に上がるはずです。
たとえば、
- このメッセージは失敗したらどうなる?
- タイムアウトはどこが握ってる?
- この順序は入れ替えたら破綻する?
といった観点で “突っ込みどころ” を探しながら読んでいく。
これは実際に上級エンジニアたちが無意識にやっている読み方で、新人のうちから意識的に身につけておくと強い武器になるのではないかと考えています。
LLMを使った勉強方法
LLMを使ったシーケンス図やネットワーク仕様の勉強方法を考えてみるのも楽しそうだなと思ったのですが、シーケンス図とLLMの相性が悪い...
LLMはテキストデータには強いですが、画像の読み込みはまだ意外とできないんですよね...
最近は少しずつできるモデルも増えてきたようですが、完璧ではないです。特に大規模なシーケンス図は読み込めません。
ただし、LLMでシーケンス図を読み込む手段として、Mermaid記法※を使ってみれば、精度も上がるようです!
※Mermaid記法は以下のようにテキストでシーケンス図を表現できるMarkdown言語です。
sequenceDiagram participant U as スマホ participant G as 基地局 participant C as コア U->>G: 電波を探して接続 G->>C: 端末が来たよ(接続要求) C->>G: 利用OK(認証完了) G->>U: ネットワーク利用開始 U->>C: 通話したい(発信リクエスト) U->C: 通話経路を確保 C-->>U: 呼び出し音 → 相手応答 U->C: 通話開始(音声データやり取り)
まだ、実際にLLM活用はできていないのですが、以下のような方法を考えています。
LLMに破壊シーケンスを生成させる
既存のシーケンス図をMermaid記法で学習させ、破壊シーケンスを作成させてみるのはどうでしょうか。
破壊シーケンスとは
- 順序を入れ替える
- あるメッセージを削る
- タイマー値を変える
- ノードの応答タイミングをずらす
- リトライ回数を変える
- 並列処理を意図的に被らせる
- 認証前にメッセージを送らせる
など、“破綻しそうな形に意図的にシナリオを変形させたシーケンス図” のことです。
具体的な流れ
例として、一般的なWebアプリのログイン処理をMermaid記法で表現してみます。
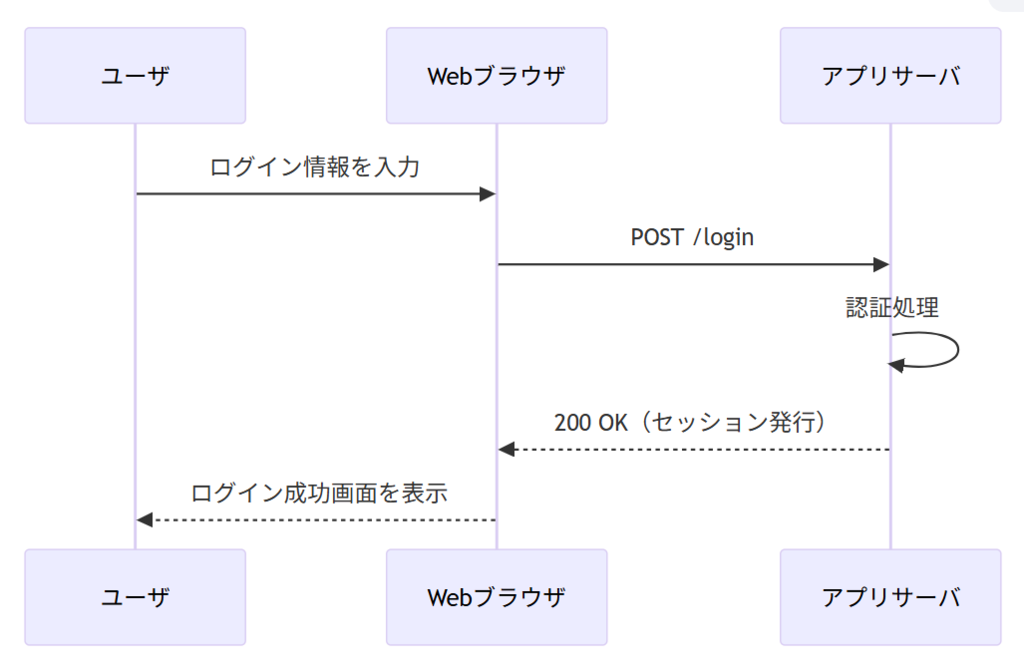
sequenceDiagram participant U as ユーザ participant W as Webブラウザ participant S as アプリサーバ U->>W: ログイン情報を入力 W->>S: POST /login S->>S: 認証処理 S-->>W: 200 OK(セッション発行) W-->>U: ログイン成功画面を表示
破壊シーケンスはこんな感じ
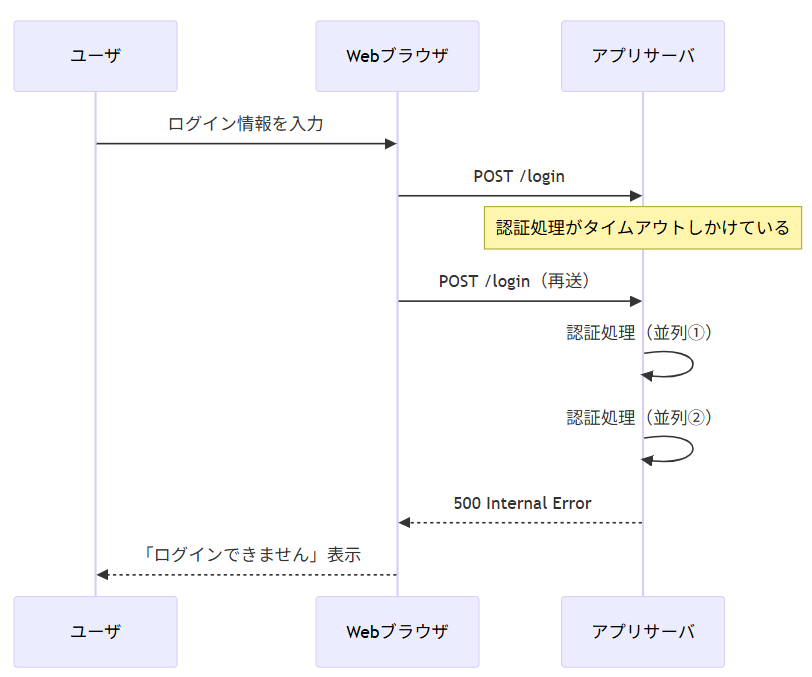
sequenceDiagram participant U as ユーザ participant W as Webブラウザ participant S as アプリサーバ U->>W: ログイン情報を入力 W->>S: POST /login %% 破壊1:認証APIの応答が遅延 Note over S: 認証処理がタイムアウトしかけている %% 破壊2:ブラウザが焦って再送 W->>S: POST /login(再送) %% 破壊3:サーバが並列で2つの認証処理を開始 S->>S: 認証処理(並列①) S->>S: 認証処理(並列②) %% 破綻 S-->>W: 500 Internal Error W-->>U: 「ログインできません」表示
成功時のことだけ想定して書いたらわからないポイントがわかってきます。
上記例だと
- 認証APIは「1回のリクエスト」を前提にしている
- 並列処理されるとサーバ内部の状態が矛盾する
- 遅延が長引くとブラウザは自動再送してしまう
などの前提条件がありますね。
一つ一つの処理の意図が明確になれば、理解しやすくなっていきます。
「あの処理がなければこんな大変なことになるなんて思わなかった!(大切な親友を失った時の悲しみのような)」なんてことを起こさないために有効です!
新入社員視点でのメリット
LLMで破壊シーケンス図を作成するメリットは以下の通りだと思います。
- 現実の議論ポイントを再現できる
- 状態遷移の前提条件が理解できる
- 自分では思いつかない破綻パターンを生成できる
- 破壊と解説のセットを効率的に生成できる
このように、あえて間違ったシーケンス図を作成することで、議論を追体験でき、シーケンス図への理解も深まるのではないでしょうか。
クイズ形式にしたら楽しめそうですね!
まとめ
お読みいただきありがとうございました。
新入社員として、LLMを使って業務の分析をしてみました。
その上で、シーケンス図の勉強が大事だという気づきを得て、シーケンス図の勉強についてもまとめてみました。
M365 Copilotでコメント分析する作業はすごく楽しかったです。
社内にはいろんな情報があるので、今回のようなちょっとした分析を隙間時間でできるよう今後も精進します!
モバイルネットワークの標準化議論についてもLLMを使ってまとめてみるのも面白そうですね。
シーケンス図の勉強も頑張ります!
今後LLMを使った勉強法でつよつよエンジニアになっているかもしれませんので、次回の記事もぜひ読んでいただけると嬉しいです!
参考: タグの詳細
技術仕様
機能の実装方法や構成
システムや機能の構成や要素に関するコメント
制御フロー
機能やサービスが「どんな順序で動作するか」「動く契機」に関するコメント
インターフェース
NW要素間の「接続点」等に関するコメント
プロトコル
通信プロトコルに関するコメント
標準整合性
標準仕様との整合性に関するコメント
機能要否
必要性
機能や開発の必要性、導入すべきかどうか
優先度
実装順や重要度など、何を先にやるか
整理方針
その内容(問題)をどう扱うか、どう検討するかについて(課題表を使うか、など)
要はどう進めるかの整理について費用・見積
コスト
何にいくらかかるか
リソース
何をどれだけ使うか(端末や人員、時間、設備など)
見積もり前提
何を前提に見積もるか(契約形態、実施タイミング、対象範囲)
検証・試験
試験計画
何をどう試験するか、方針や範囲
検証環境
どんな環境で試験するか(設備や端末など)
FT・フィールドテスト
商用環境での挙動確認について
組織・体制
役割分担
誰が何を担当するかについて
組織間体制
法人と個人の関係など組織同士の連携の仕方について
体制構築なども含む運用・維持管理
契約や設備の運用について、条件など
意思決定・承認
誰が決定するか、判断するか