
論文紹介
サービスイノベーション部翻訳チーム所属の川原田です。 今回はACL2022で採択された論文の中からいくつかピックアップしてご紹介します。 前回ご紹介したように、近年のACLでは言語モデルを使った研究、特に、Promptingと多言語が大きなテーマとなっています。今回は、多言語に関する論文に注目していきたいと思います。
近年の多言語に関する研究は、多言語対応の言語モデルを用いた上でZero-shotやFew-shotで学習を行うといった研究が多いのが特徴です。 この背景には、多言語対応の言語モデルに関する研究が盛んだということがあります。 今年発表されたものだけでも、文字単位の入力で入力した後、Local TransformerやCNNを使って系列長を圧縮するCANINEやbyte単位でT5を学習するByT5などがあり、今後も様々なモデルが登場すると予想されます。
高性能な多言語対応の言語モデルが次々と登場していますが、その恩恵を受けられていない言語もまだ多く存在します。実際に、多言語の言語モデルの学習に使われるmC4コーパスには101の言語が含まれていますが、世界中に存在する数千という言語と比べるとその数はほんの一部に過ぎません。 今まであまり注目されてこなかった低リソースの言語に対して、どのようにアプローチしていくのかというのも今後のテーマの1つだと言えそうです。
ACL2022でも低リソース言語に関する論文がいくつか発表されています。その中から、以下の2つの論文についてご紹介させていただきます。
- AmericasNLI: Evaluating Zero-shot Natural Language Understanding of Pretrained Multilingual Models in Truly Low-resource Languages
- KinyaBERT: a Morphology-aware Kinyarwanda Language Model
AmericasNLI: Evaluating Zero-shot Natural Language Understanding of Pretrained Multilingual Models in Truly Low-resource Languages
この研究は、低リソース言語用のNLI(Natural Language Inference)の評価データセットであるAmericasNLIを作成し、Zero-Shotの設定で評価を行った研究です。
NLIとは、前提文と仮説文の2つの文を入力した時、前提文が仮説文を含意する(entails)、含意しない(contradicts)、中立(neutral)の3つのうちどれに当たるかを判別するタスクです。 今まで、低リソースデータに対するZero-Shotのタスクは、品詞タグや係り受け解析など、比較的低レイヤーのタスクについてしか研究が進んでいませんでした。この研究は、もう少し高レイヤーなタスクであるNLIに対して、性能評価を行っています。
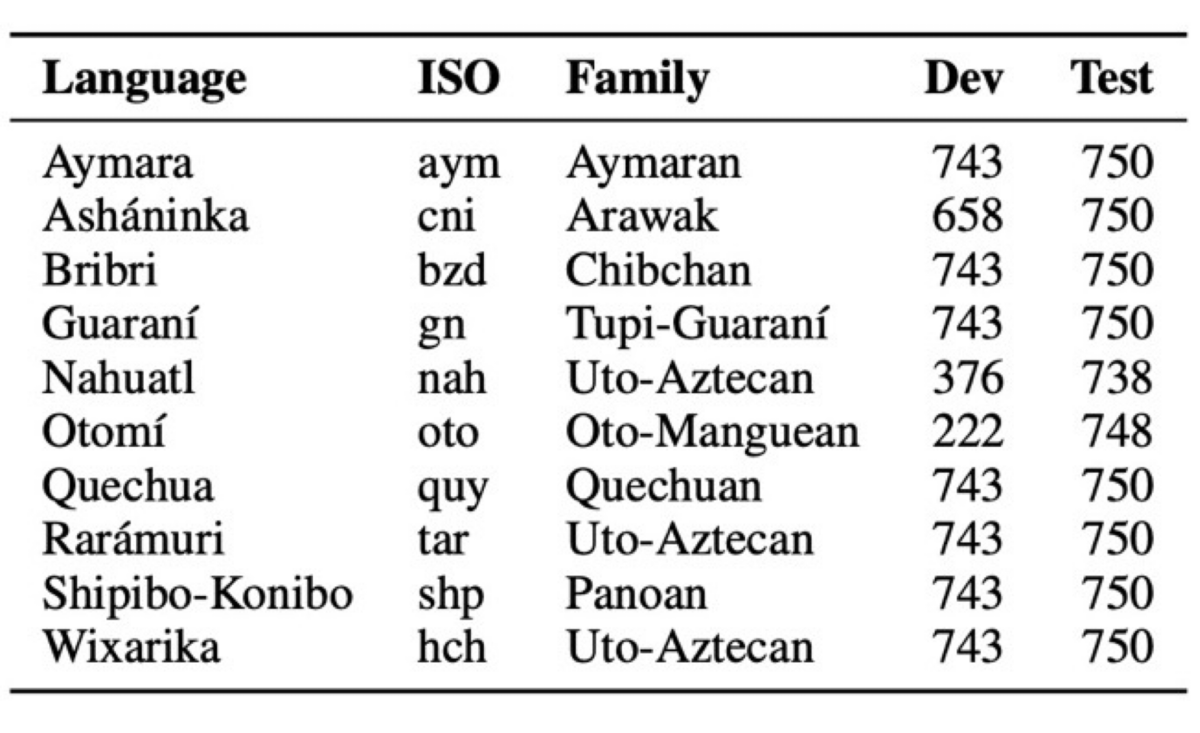
上の表は、作成したデータセットを表しています。このデータセットは、多言語NLIデータセットであるXNLIから低リソース言語であるアメリカ先住民の言語を抽出し、スペイン語に翻訳することで対訳コーパスを作成しています。
この研究では、以下の2つのアプローチを比較しています。
- Zero-shotベースのアプローチ
- Translationベースのアプローチ
Zero-shotベースアプローチでは、XML-Rに対してMNLIというデータセットを用いて、英語orスペイン語でNLIのタスクについて学習させます。 XML-Rは多言語の言語モデルなので、英語やスペイン語でNLIというタスクを理解させることで、別の言語であるアメリカ先住民の言語に対しても同じようなタスクが解けると期待できます。 また、事前にXML-Rに対して、アメリカ先住民の言語を用いた教師なし学習を行った場合も比較しています。
Translationベースのアプローチでは、アメリカ先住民の言語をスペイン語に変換し、スペイン語に対するNLIを解くという2段階の方法で行います。この方法では、アメリカ先住民の言語⇄スペイン語の翻訳モデルとスペイン語用のNLIモデルの2つの学習が必要になります。アメリカ先住民の言語⇄スペイン語の翻訳モデルは少量の対訳コーパスを使ってTransformerで学習しています。スペイン語用のNLIモデルはXML-RをMNLIを使ってfine-tuningしています。
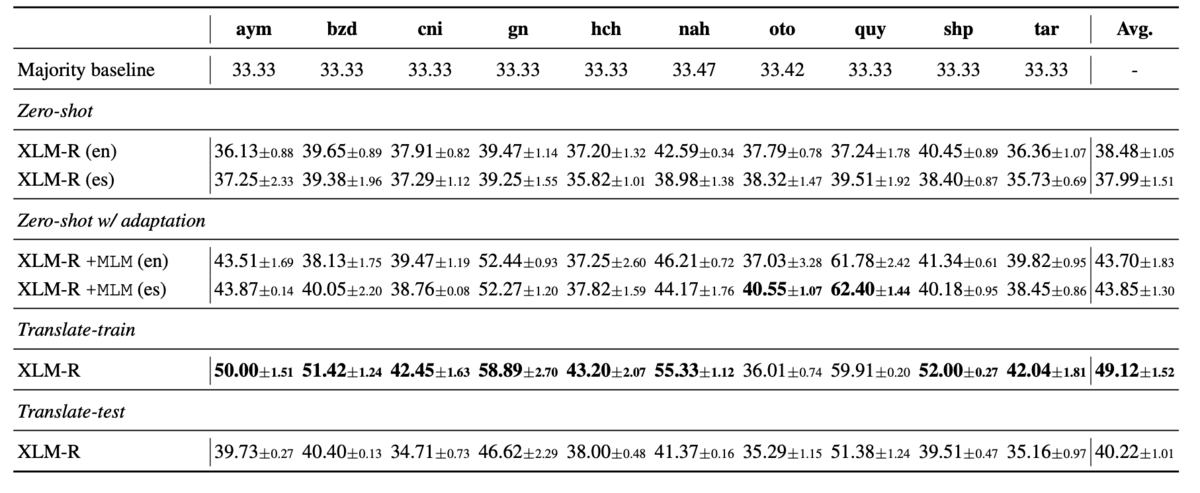
上の表は実験結果です。Zero-shotでも一部性能が高い言語がありますが、全体的にTranslationベースの手法の方が性能が高いことがわかります。
Translationベースのアプローチで用いているアメリカ先住民の言語の翻訳モデルは、少量のデータで学習されており、翻訳精度も高くはありません。そのため、Zero-shotのアプローチの方が性能が高いだろうと予想できます。しかし、Translationベースのアプローチの方が性能が出ており、NLIをZero-shotで行なった時の性能は高くなかったという結果になっています。
KinyaBERT: a Morphology-aware Kinyarwanda Language Model
この論文は、低リソース言語であるルワンダ語(Kinyarwanda)のBERTを作成した研究です。 ルワンダ語は、ルワンダの公用語で主に中央アフリカと西アフリカで話されている言語です。ルワンダ語の名詞には、16のクラスというものが存在し、それによって動詞の活用も変化します。
アフリカ系言語でBERTを学習した研究としてはAfriBERTがありますが、AfriBERTはBERTのモデルアーキテクチャはそのままに、学習に使用する言語をアフリカ系の言語に変更した多言語の言語モデルです。 KinyaBERTでは、ルワンダ語が持つ形態素を上手く活用したモデルアーキテクチャとなっており、少ないデータ量でも高い性能を実現しています。

KinyaBERTのモデルアーキテクチャは上の図の通りです。 まず、入力文に対して、形態素解析と品詞タグ付けを行っておきます。次に、品詞タグと語幹、接尾語を単語単位のTransformer EncoderであるMorphological Encoderに入力し、単語単位のEmbeddingを得ます。このEmbeddingをSentence/Document-Level Encoderに入力することで、文/文書のコンテキストを考慮したEmbeddingが得られる2段階のモデルとなっています。 Sentence/Document-Level Encoderは、従来のBERTで用いられているTransformer Encoderと同じものです。また、Morphological EncoderにはPosition Encodingが入力されていないため、Sentence/Document-Level Encoderへ入力する前に語幹のEmbeddingを結合して入力しています。
MLM(Masked Language Model)の学習では、一般的なMLMと同様にして、トレーニングデータに含まれるトークン全体の15%を予測対象とし、その中の80%を[MASK]トークンに置き換え、10%をランダムなトークンに置き換え、10%をそのままにするという操作を行います。ここまでは従来のBERTと同じですが、これに加えてKinyaBERTの学習では、[MASK]トークンに置き換え、10%をランダムなトークンに置き換えのどちらかの操作を行なった際に、70%の確率で予測対象のトークンの接尾語を削除します。 この学習方法では、語幹と接尾語の両方が予測対象となります。
また、接尾語のみを予測対象とした目的関数として、Affix Distribution Regression(ADR)とAffix Set Classification(ASC)の2つを新たに提案しています。

学習データセットを見てみると、従来のBERTのトークン数は約3,300Mなので、学習データ量がかなり少ないのがわかると思います。
最後に、実験結果を見ていきたいと思います。

GLUEベンチマークのほぼ全ての評価において、KinyaBERTの性能がBERTを上回っています。特に、ASCを目的関数として学習した場合の性能が高い結果となっています。

各タスクに対してFine-tuningを行なった際のLossの変化を見てみても、KinyaBERTが最も良く収束していることがわかります。
最後に
この記事では、ACL2022に採択された論文の傾向を見ていきました。
今回はPromptingについては深く取り上げませんでしたが、OpenPrompt: An Open-source Framework for Prompt-learning という論文がBest Demo Paperに選ばれています。簡単にPromptingが行えるようなフレームワークが出てくることで、今後更にPromptingについての研究が増えていくのではないかと考えられます。
また機会があれば、このような論文紹介をさせていただければと思います。