
本記事は、ドコモアドベントカレンダー2023の18日目の記事になります。
こんにちは。NTTドコモサービスイノベーション部1年目社員の髙橋克です。
入社してから、主にレコメンデーションシステムの技術開発に携わらせていただいてます。
本記事では、OpenAI、Googleの提供しているLLMのテキスト埋め込みモデルを使い、レコメンドを行う際の商品情報の特徴量化の方法について検討し、主観評価してみました。
始めに
自然言語処理(NLP)分野において、テキストデータの理解は重要な課題の一つです。初期段階ではキーワードベースのアプローチが主流でしたが、技術の進歩により、「Word2Vec」のような方法が登場し、これによって単語間の意味的な関係を定量化し、テキスト理解を深めることができるようになりました。さらに、「fastText」は単語の内部構造を考慮に入れ、より詳細な理解を可能にしましたが、文脈を完全に捉えるにはまだ限界がありました。
現在は、大規模言語モデル(LLM)の時代に突入し、テキスト埋め込み技術は大きく進化しています。これらのモデルは、単語やフレーズを超えて文全体をベクトル化し、より広範な文脈を捉える能力を持っており、テキストの深い意味やニュアンスの理解が進み、より進化したNLPアプリケーションが可能になりました。
レコメンデーションシステムは、テキスト埋め込み技術の応用例として一般的ですが、LLMのテキスト埋め込みがどのようにレコメンデーションシステムに役立つか、また、この技術を活用することでどのように有意義な推薦を提供できるかが注目されています。
このブログ記事では、LLMのテキスト埋め込み技術をレコメンデーションシステムにどのように組み込むべきかを考察します。レコメンデーションシステムの進化において、これらの技術は非常に重要な役割を果たしており、今後さらにその影響力は増していくと考えられます。
fastTextによるテキスト埋め込みについて
fastTextのテキスト埋め込みをレコメンデーションシステムの特徴量として扱う場合、一般的に次のような手順を取ります。
テキストの前処理
対象のテキスト(例えば商品の説明)を前処理する。この段階では、テキストを単語に分割し、必要に応じて正規化やストップワードの除去を行う
単語の選択
一般に名詞や形容詞は商品の特徴を表すのに重要な役割を果たすため、これらの単語を特に選択
単語のベクトル化
fastTextを使用して、選択した単語をベクトル化する。fastTextは各単語を密度の高いベクトルとして表現し、単語の意味的な特徴を捉える
平均ベクトルの計算
個々の単語のベクトルを取り、それらの平均を計算する。この平均ベクトルは、テキスト全体の意味的な特徴を代表するものとして利用される
私たちのチームでもfastTextのテキスト埋め込みを特徴量の1つとしたレコメンドエンジンを所有しており、上記手順にならって、以下のように、商品データを、ジャンル(数百次元)、タイトル・商品詳細の名詞の平均ベクトル(数百次元)、タイトル・商品詳細の形容詞の平均ベクトル(数百次元) として扱っています。
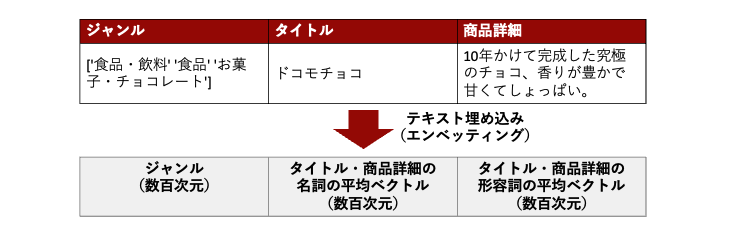
※架空の商品です。
LLMによるテキスト埋め込みについて
では、上記ドコモチョコの例において、fastTextではなく、文全体をベクトル化できるようになったLLMでテキスト埋め込みする場合、どのように扱うのことが望ましいでしょうか?
今回は以下2つの手法について検討してみました。
- 手法①:ジャンル・タイトル・商品詳細のそれぞれに対してエンベッティングを行い、その後3つのベクトルの平均を取る
- 手法②:ジャンル・タイトル・商品詳細を全て連結して1つの文として扱い、その後エンベッティングを行う
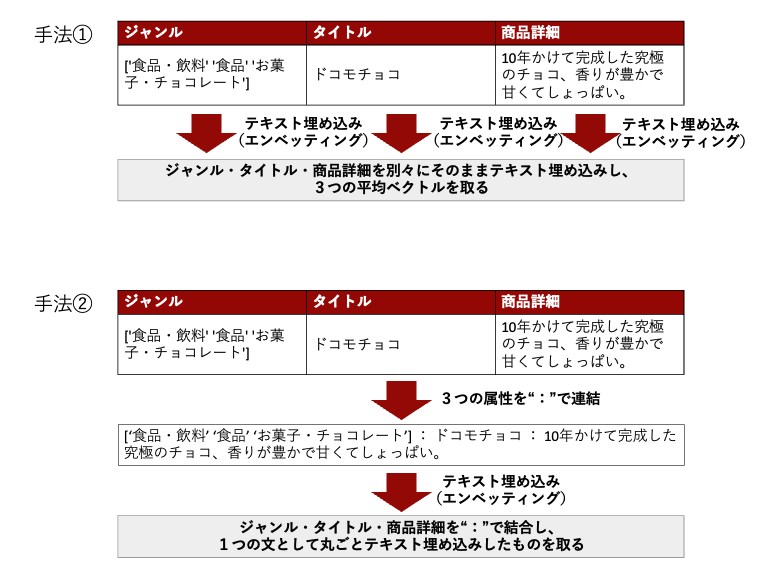
この2つの手法について、それぞれどのような利点と制約があるのか、以下仮説を立ててみました。
手法①(別々にエンベッティングしてから平均のベクトルを取る)
・利点:
・異なるテキストソース(ジャンル・タイトル・商品詳細)からの情報を統合して、
商品の総合的な表現を得ることができる
・各要素が等しく扱われ、バランスの取れたエンベッディングが可能
・制約:
・個々のテキスト要素の特異性や文脈が失われる可能性がある
・すべての要素が同じ重要度を持つわけではないため、特定の側面が過小評価される可能性がある
手法②(テキストを連結し、一つの文としてからエンベッティングする)
・利点:
・文脈の連続性を保ち、より豊かな意味情報をエンベッディングに反映させることができる
・商品に関する詳細な情報を失うことなく、エンベッディングに取り込むことが可能
・制約:
・長いテキストになると、エンベッディングモデルが扱える最大長を超える可能性がある
・結合されたテキストの全体的な長さや内容のバランスによって、特定の要素が他よりも強調される可能性がある
これらの仮説を念頭に置きながら、手法①②のどちらがよりレコメンデーションモデルの特徴量としてLLMのテキスト埋め込みを扱うのに応しいかを調査しました。
調査方法
- 目的
- LLMのテキスト埋め込みをレコメンデーションエンジンに特徴量として用いる際、上記2つの手法において、立案した仮説の基に、どちらが優れているかを評価する
- 使用データ
- dショッピングにおいて掲載されているランダムな商品1700点
- 評価方法
- ある商品を選び、残りの1699点の商品全てに対して、それぞれの手法を用いてコサイン類似度を計算し、類似度が最も高い上位5つの商品を選出します。これらの商品について、商品の類似性や文章の類似性を考慮し、私を含む複数人でレコメンデーションの観点から主観的にどちらの手法が優れているかを判断します。
なお、使用データのランダムな商品1700点をジャンルベースでカウントした際の上位10位の内訳は以下になります。
| ジャンル | カウント |
|---|---|
| ファッション・アクセサリー / 衣料品 / ナイトウェア・ルームウエア | 338 |
| ファッション・アクセサリー / 衣料品 / スポーツウェア | 155 |
| ファッション・アクセサリー / 衣料品 / トップス | 141 |
| ファッション・アクセサリー / 靴 | 80 |
| 食品・飲料 / 食品 | 76 |
| 食品・飲料 / 食品 / お菓子・チョコレート | 72 |
| ファッション・アクセサリー / ファッション小物 / 帽子 | 40 |
| 電気製品 / 通信機器 / 電話 / 携帯電話・スマートフォン用アクセサリー | 23 |
| 食品・飲料 / 食品 / パン・焼き菓子 | 23 |
| 電気製品 / プリンター・コピー機 / プリンター・コピー機関連用品 / プリンター消耗品 | 22 |
調査に用いるモデル
今回の調査において用いるLLMのテキスト埋め込みモデルは下記2つのモデルになります。
| 特徴 | text-embedding-ada-002 (OpenAI)[1] | embedding-gecko-001 (Google)[2][3][4] |
|---|---|---|
| 開発者 | OpenAI | |
| 用途 | テキスト検索、コード検索、文章の類似性タスク | 文書検索、文章の類似性タスクなどのNLPアプリケーション |
| コンテキスト長 | 最大8192トークン | 最大1024トークン |
| 埋め込みの次元 | 1536次元 | 768次元 |
| 主な機能 | 従来の5つのモデルを統合、パフォーマンス向上[1] | テキストを意味的に表現するベクトルに変換 |
| コスト | 1,000トークンごとに$0.0001 | 1,000トークンごとに$0.0004 [5] |
2つのモデルのテキスト埋め込みを、データフレームとして表示するサンプルコードはそれぞれ以下です。
- text-embedding-ada-002 のテキスト埋め込み
import openai import numpy as np import pandas as pd # OpenAI APIの設定 openai.api_type = "azure" openai.api_key = 'YOUR_API_KEY' openai.api_base = "YOUR_API_BASE" openai.api_version = "YOUR_API_VERSION" # テキスト texts = ["埋め込みたいテキスト"] # テキストごとのエンベディングを生成 embeddings = [] model = "text-embedding-ada-002" for text in texts: response = openai.Embedding.create(input=text, engine=model) embeddings.append(response['data'][0]['embedding']) # NumPy配列に変換 embeddings_np = np.array(embeddings) embeddings_df = pd.DataFrame(embeddings_np) print("Embeddings DataFrame:") display(embeddings_df)
- embedding-gecko-001のテキスト埋め込み[6]
import numpy as np import pandas as pd import google.generativeai as palm # PaLM APIの設定 palm.configure(api_key='YOUR_API_KEY') # テキスト texts = ["埋め込みたいテキスト"] # テキストごとのエンベディングを生成 embeddings = [] model = "models/embedding-gecko-001" for text in texts: embedding = palm.generate_embeddings(model=model, text=text) embeddings.append(embedding['embedding']) # NumPy配列に変換 embeddings_np = np.array(embeddings) embeddings_df = pd.DataFrame(embeddings_np) print("Embeddings DataFrame:") display(embeddings_df)
調査結果
※規約上、商品名や商品詳細を載せることができないので、以下、商品詳細からLLMに予想してもらった架空の商品名であることにご留意ください。また、商品のイメージ画像についても権利関係がクリアな生成AIを用いて作成した架空の商品画像を使用しています。
コサイン類似度を計算するための、起点となる商品はこちらです。
|

|
⚪︎text-embedding-ada-002(OpenAI)
text-embedding-ada-002 のテキスト埋め込みを活用し、手法①と手法②を用いて起点の商品と類似度が高い商品を調査した結果、類似度の高い上位5位の商品は以下のようになりました。
手法①(ジャンル・タイトル・商品詳細のそれぞれに対してエンベッティングを行い、その後3つのベクトルの平均を取る)
| 順位 | 類似度 | ジャンル | 商品名 |
|---|---|---|---|
| 1 | 0.967 | ['食品・飲料' '食品' 'お菓子・チョコレート'] | 北海道もちもち&なめらかミルキーバルーンプリン |
| 2 | 0.955 | ['食品・飲料' '食品' 'お菓子・チョコレート'] | 洋菓子デライト:ゼリー・ムース・プリンのアソートセット |
| 3 | 0.955 | ['食品・飲料' '食品' 'お菓子・チョコレート'] | 葉酸たまごのシンプルプリン |
| 4 | 0.954 | ['食品・飲料' '食品' 'お菓子・チョコレート'] | 地元産素材の手作りプレミアムプリン:濃厚クリーム&上品な甘さ |
| 5 | 0.954 | ['食品・飲料' '食品' 'お菓子・チョコレート'] | フルーツハーモニー:2層のフルーティーゼリー |
手法②(ジャンル・タイトル・商品詳細を全て連結して1つの文として扱い、その後エンベッティングを行う)
| 順位 | 類似度 | ジャンル | 商品名 |
|---|---|---|---|
| 1 | 0.911 | ['食品・飲料' '食品' 'お菓子・チョコレート'] | 北海道もちもち&なめらかミルキーバルーンプリン |
| 2 | 0.895 | ['食品・飲料' '食品' 'お菓子・チョコレート'] | 洋菓子デライト:ゼリー・ムース・プリンのアソートセット |
| 3 | 0.889 | ['食品・飲料' '食品' 'お菓子・チョコレート'] | フルーツアロマティックゼリー:6種香り高きセレクション |
| 4 | 0.889 | ['食品・飲料' '飲料' 'お茶・紅茶'] | プラズマ乳酸菌入り贅沢ミルクティー |
| 5 | 0.888 | ['食品・飲料' '食品' 'お菓子・チョコレート'] | 地元産素材の手作りプレミアムプリン:濃厚クリーム&上品な甘さ |
⚪︎embedding-gecko-001(Google)
embedding-gecko-001 のテキスト埋め込みを活用し、手法①と手法②を用いて起点の商品と類似度が高い商品を調査した結果、類似度の高い上位5位の商品は以下のようになりました。
手法①(ジャンル・タイトル・商品詳細のそれぞれに対してエンベッティングを行い、その後3つのベクトルの平均を取る)
| 順位 | 類似度 | ジャンル | 商品名 |
|---|---|---|---|
| 1 | 0.999 | ['食品・飲料' '食品' 'お菓子・チョコレート'] | 心を込めた小豆のぜんざい:映画にインスパイアされた風味豊かな和菓子 |
| 2 | 0.999 | ['食品・飲料' '食品' 'お菓子・チョコレート'] | 国産米のサクッと大判煎餅:甘辛醤油味 |
| 3 | 0.989 | ['食品・飲料' '食品' 'お菓子・チョコレート'] | 贈答用高級和菓子詰合せ:人気のバラエティー豊富な選集 |
| 4 | 0.989 | ['食品・飲料' '食品' 'お菓子・チョコレート'] | 濃厚マンゴープリン&なめらか杏仁豆腐セット |
| 5 | 0.989 | ['ファッション・アクセサリー' '衣料品' 'ナイトウェア・ルームウェア'] | ふわふわあったか快適着心地家族用ルームウェア |
手法②(ジャンル・タイトル・商品詳細を全て連結して1つの文として扱い、その後エンベッティングを行う)
| 順位 | 類似度 | ジャンル | 商品名 |
|---|---|---|---|
| 1 | 0.999 | ['食品・飲料' '食品' 'お菓子・チョコレート'] | 心を込めた小豆のぜんざい:映画にインスパイアされた風味豊かな和菓子 |
| 2 | 0.999 | ['食品・飲料' '食品' 'お菓子・チョコレート'] | 国産米のサクッと大判煎餅:甘辛醤油味 |
| 3 | 0.997 | ['食品・飲料' '食品' 'お菓子・チョコレート'] | 手作り干菓子わり氷:繊細色合いの詰合せ |
| 4 | 0.997 | ['食品・飲料' '食品' 'お菓子・チョコレート'] | 北海道もちもち&なめらかミルキーバルーンプリン |
| 5 | 0.997 | ['食品・飲料' '食品' 'パン・焼き菓子'] | 人気ベーカリーセレクション:パンの詰め合わせ |
考察
結果について、以下表に情報をサマライズしました。
また、追加調査として、起点である商品のジャンル”['食品・飲料' '食品' 'お菓子・チョコレート']”以外のジャンルが何位の位置で増えるのか、手法①②によって位置に違いがあるのかについてもまとめています。
| テキスト埋め込みモデル | text-embedding-ada-002 (OpenAI) | embedding-gecko-001 (Google) |
|---|---|---|
| 起点商品 | あまおうミルクプリン | あまおうミルクプリン |
| 上位ランク商品の傾向 | プリンやゼリーなど、起点に類似 | ぜんざい、煎餅、ルームウェアなど、起点と異なる商品も |
| 特徴表現の次元数 | 1536次元 | 768次元 |
| 手法①の類似度傾向 | 高い類似度。起点と同じジャンルが多い | 手法②と大きな差分なし |
| 手法②の類似度傾向 | より広範な商品カテゴリー。ジャンルにとらわれない | 手法①と大きな差分なし |
| [追加調査]ジャンル外商品のランクイン位置 (手法①) | 21位〜 | 5位〜 |
| [追加調査]ジャンル外商品のランクイン位置 (手法②) | 4位〜 | 5位〜 |
⚪︎text-embedding-ada-002(OpenAI)
- 手法①:類似度の高い上位5位全てにおいて、プリンやゼリーがあがっている
手法②:4位にジャンルが異なる”['食品・飲料' '飲料' 'お茶・紅茶']”である、”プラズマ乳酸菌入り贅沢ミルクティー”がランクインしている
手法①と手法②を比べてわかることは、手法①の方が手法②に比べて総じて類似度が高い水準であることです。これは、手法①の仮説にて記載した異なるテキストソース(ジャンル・タイトル・商品詳細)からの情報を統合して、商品の総合的な表現を得ることができるといった側面と、手法②の仮説にて記載した文脈の連続性を保ち、より豊かな意味情報をエンベッディングに反映させることができるという側面が良く反映されている部分だと言うことができると思います。 また、どちらの結果においても、ジャンルは違えど、果物であったり、焼き菓子であったりと、起点から大きく外れていることはないものが上位にあがっていました。
レコメンデーションシステムに適用する際にどちらの手法を取ることがより望ましいかと言う観点では、より厳格に起点に近い商品をおすすめしたい場合は手法①を採用した方が良いですが、レコメンデーションシステムにおける重要な観点の1つである商品のカーバー率に重きを置く場合、より豊かな意味情報を保持した手法②を採用した方がいいということが言えます。
⚪︎embedding-gecko-001(Google)
- 手法①:類似度の高い商品としてぜんざいや、煎餅が選択されているが、5位にはかなり異なる商品であるルームウェアがあがっている
手法②:ぜんざい、煎餅が上位にあがっている、5位には異なるジャンルのパンの詰め合わせが上がっている
手法①②ともにいえることとして、OpneAIのモデルtext-embedding-ada-002と比べると、ルームウェアがランクインされていたりと、テキスト埋め込みの精度が低いことが分かります。特徴量表現としてembedding-gecko-001は768次元、text-embedding-ada-002は1536次元であり、この違いが精度の違いを生んでいると思われます。
レコメンデーションシステムに適用する際にどちらの手法を取ることがより望ましいかと言う観点においては、追加調査も踏まえるとあまり差分がない結果となっています。
結論
レコメンデーションシステムに特徴量として、LLMのテキスト埋め込みを用いる場合、どのように扱うことが望ましいか。という課題について、以下の2つの手法について仮説を立てて調査しました。
手法①(ジャンル・タイトル・商品詳細のそれぞれに対してエンベッティングを行い、その後3つのベクトルの平均を取る)
手法②(ジャンル・タイトル・商品詳細を全て連結して1つの文として扱い、その後エンベッティングを行う)
2つのLLMテキスト埋め込みモデルを用いて調査を行った結果、手法①②で類似度が高いものがバラバラであるだとか、そのような大きく精度に影響が出るようなことはなく、より厳格に起点に近い商品をおすすめしたい場合は手法①を採用した方が良く、一方で、レコメンデーションシステムにおける重要な観点の1つである商品のカーバー率に重きを置く場合、より豊かな意味情報を保持した手法②を採用した方がいいということが言えます。
また、次元数の違いはあれど、text-embedding-ada-002(OpenAI)とembedding-gecko-001(Google)の両モデルの性能差についても見られた調査になったと思います。 Googleで言うと、最近Googleの新しいLLM「Gemini」も発表され、今後のテキスト埋め込みの進化にも期待が高まりますね。
今後については、マルチモーダルなアプローチから、商品画像などのビジュアルコンテンツを積極的に活用していきたいと考えています。
参考文献
[1]https://openai.com/blog/new-and-improved-embedding-model (2023/12/12)
[2]https://developers.generativeai.google/models/language?hl=ja (2023/12/12)
[3]https://weaviate.io/blog/announcing-palm-modules (2023/12/12)
[4]https://www.analyticsvidhya.com/blog/2023/10/getting-started-with-googles-palm-api-using-python/ (2023/12/12)
[5]https://tokescompare.io/product/palm-2-textembedding-gecko-001/ (2023/12/12)
[6]https://developers.generativeai.google/tutorials/embeddings_quickstart (2023/12/12)